
本文转载自Rancher Labs
无论你喜欢与否,你都不得不承认Helm是管理Kubernetes应用程序独一无二的工具,你甚至可以通过不同的方式使用它。
在Helm的使用过程中,我们注意到有几个问题不断出现:
- 你将你的Helm chart放在哪里?
你是使用app文件保存它们还是使用chart仓库?
- 你如何划分Helm chart?
你是使用一个共享的chart或是为每个服务维护一个chart?
我正在通过我以往在各种创业公司的经验来尝试解决这些问题,但是我也借鉴了大型公司的做法。
以下是我要概述的几个方法:
- 使用一个chart仓库来存储一个大型共享chart
- 使用一个chart仓库来存储许多特定于服务的chart
- 使用特定于服务的chart,这些chart与服务本身存储在同一仓库中
然后,我将介绍在决定这些选项时应该考虑的因素,例如依赖项差异和团队结构等。

Option1:在一个chart仓库中维护一个大型共享chart
在我们一个项目中,我们从一个用于部署多个服务的大型chart开始。它存储在ChartMuseum中,并由负责部署基础架构的人员进行维护。
如果你的各个服务在本质上十分类似,那么共享chart可以为你省去很多麻烦。这里我们采用Helm维护者Josh Dolitsky在KubeCon 2019上描述的情况:
我最近在负责一个项目,这个项目包含9个微服务……我意识到它们几乎都是相同的HTTP监听服务。所以我决定仅仅构建一个helm chart来部署9个不同的服务,为每个服务做不同的配置——仅为特定的服务设置一个新的docker标签。
在这种情况下,将Helm chart存储在ChartMuseum等chart仓库中是有意义的,因为只有值需要保存在这些特定服务的仓库中。
Option2:在一个chart仓库中维护几个特定于服务的chart
特定于服务的chart优势在于,你可以更改一项服务,而无需担心会破坏另一项服务。但是它们可能会导致重复的工作——如果你要更新通用配置,则必须在每个chart中进行相同的更改。
是否需要在一个chart仓库中保存它们则是另一个问题了。如果这些chart是特定于服务的,那么将它们存储在一起尚没有强有力的架构论证。当然,如果你有专门的人员或团队来维护所有的chart,一起存储多个特定于服务的chart通常会比较容易。
例如,与我一起工作的一位DevOps工程师,他在一个中心chart仓库中维护15种不同的微服务chart。对于他而言,在同一个位置更新所有chart比向15个不同的仓库提交拉取请求要容易得多。开发人员当然清楚如何更新chart,但是处理资源相关的设置显然更吸引他们。
Option3:在与服务本身相同的仓库种维护特定于服务的chart
对于基于微服务的应用程序来说,特定于服务的chart是一个很好的选择。而当你将每个chart与服务代码保存在同一仓库中时,使用特定于服务的chart则会更好。
如果你在服务仓库中存储Helm chart,那么可以更轻松地独立于其他项目持续部署服务。并且你可以将chart更新(例如添加新变量)与应用程序逻辑的更改一起提交,使其更易于识别和还原重大更改。
然而,本选项的优势取决于你所维护的微服务的数量。如果你的微服务数量正迈入两位数,那么这一选项的优势则没有那么明显,更多的是阻碍。如果你要处理非常同质的服务(如Josh Dolisky),则尤其如此。
决定选项时需要考虑的因素
一般情况下,有两个方面需要考虑:
- 依赖项和可重现:每个服务的依赖项有多少区别?对一个服务的更改有多大风险会中断另一个服务?你如何再现特定的开发条件?
- 团队结构:你负责每个服务的小型自治团队吗?你有了解DevOps的开发人员吗?你的团队中DevOps文化流行程度如何?
依赖项和可重现
如果你将你的chart和应用程序分开维护,它们的版本将彼此不同。如果你在部署时遇到问题,并且需要重现导致该问题的条件,则需要确定:a)服务版本;b)用于部署它的chart版本。你可能想要走捷径,使用“latest” chart来测试服务x.x.x,但这并不是一个好想法,因为这样你将永远无法重现造成问题的确切条件。
那么,如果你经常需要更改的chart版本怎么办?是不是应该一起测试这些改动呢?
考虑到许多开发人员需要创建同一共享chart中的分支版本这一场景:
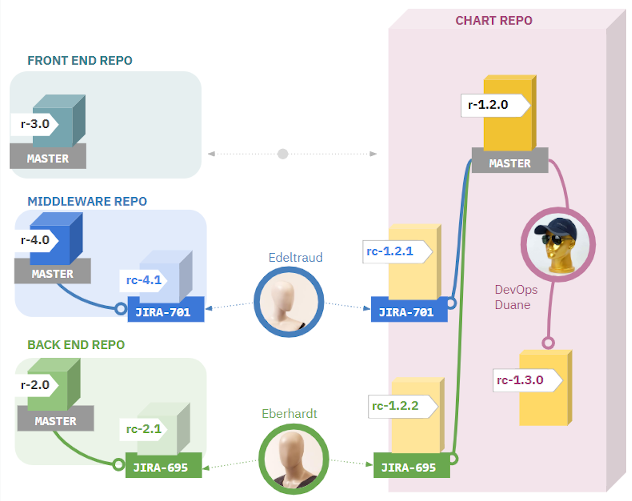
开发人员(图中的Edeltraud和Eberhardt)分别在不同的分支中工作,并且想要在开发环境中测试他们的更改以及图表更改——所以他们还需要分支chart。同时,DevOps工程师在他的共享chart的分支中更新一些常用组件。
如果没有人将他们的chart更改更新到各个分支,那么就有可能破坏另一个服务部署。
不久前,我们正好遇到了这个问题。Chart维护者用一个新的条件块更新了共享chart。该语句检查了一个新的变量“foo”是否被设置为“启用”。然而,变量“foo”还没有在所有服务的值文件中定义。对于缺少该变量的服务,部署中断了。不幸的是,当时chart中没有定义默认的回滚行为。
如果chart和代码位于同一个仓库中,并且可以在同一个分支中进行测试,则针对这些问题的测试将更加容易。
即使一开始似乎是矫枉过正,我们也会这样做。我们的工作对象是很少有依赖项的服务。对于每个服务,Helm chart只部署一个带有特定Docker标签的主容器。chart的名称和docker标签是通过变量传递进来的。尽管如此,我们仍然避免了使用共享chart,而是选择在每个服务仓库中放置单独的chart。
这主要是因为我们只处理了四个服务。但我们的开发人员也更喜欢掌控所有能够影响CI/CD的配置。然而情况并非总是如此,所以现在是研究另一个维度的好时机。
团队结构
Chart维护的问题同时也取决于谁管理部署流程。
这里推荐另一篇文章,由Helm维护者Matt Farina撰写的,在文章中他阐述了关于Helm正在尝试解决复杂性的话题。文章链接:
https://codeengineered.com/bl...
他阐明了必须处理Kubernetes复杂性的三个主要角色。为了清楚起见,我将对其内容进行一些解释,并将角色描述如下:
- App开发人员——这个角色主要构建服务、添加特性以及修复bug
- Deployer——这个角色负责将应用程序推向世界。理想情况下,有一个不错的自动化程序可以为他们部署应用程序,但是他们知道它的工作方式,可以根据需要进行修改。
- 系统工程师——这一角色负责维护deployer部署的Kubernetes环境。他们是管理计算机资源的专家,并且可以尽量减少任何服务的停机时间。
第一个和第三个角色你都能在公司里找到与其负责内容相符的职位,而Deployer这个角色则有些模糊,这个角色所负责的内容常常会被其他两个角色的人接管——这会影响你如何管理你的Helm chart。
尚在早期阶段的初创公司的DevOps
如前所述,我们的业务是为初创企业提供运维支持,这些企业往往需要快速扩大规模。我们见过很多“非常规”的设置和分工。在早期阶段,App开发者可能会负责各种事情,有些人甚至会帮忙完成系统管理员的任务,比如设置打印机或配置办公室网络等。他们会尽力去了解其他两个角色所需要负责的内容,因为没有人可以帮助他们(直到我们参与进来)。
一旦他们想了解Helm,大多数应用开发者会把他们的chart放在最容易处理的地方——也就是他们维护的同一个repo。
在大型企业中的DevOps
你可能在一个更大的、架构更分明的团队中工作,
在这种情况下,你可能有自己的DevOps工程师甚至是整个DevOps部门。而这个人或团队经常会觉得自己也要负责 “Deployer”的角色。很有可能,他们会倾向于采用更集中的方法,比如将所有的chart存储在ChartMuseum这样的chart仓库中。更不愿意让应用开发者过多地参与到Helm chart中来(往往是有合理缘由的)。
例如,我最近看了一个经典的技术讲座,叫《从头开始构建Helm chart》,由VMWare系统工程师Amy Chen主讲。在她的开场白中,她说:
在基础设施方面,你的主要目标是时刻准备着应对故障,没有信任——在这个意义上说,就像我不太愿意信任我的APP开发者,并且我也不太需要信任我的APP开发者。
这是可以理解的。你不想让应用开发者去搞乱设置,比如CPU和内存限制,或者是pod中断预算。但整个 “DevOps文化”的概念是专门为了改善基础设施维护者和开发者之间有时会出现的疏离关系而演化出来的。
实践DveOps文化
Atlassian(JIRA和Trello的所有者)出版了一本“团队手册”,其中定义了DevOps文化:
DevOps文化是关于开发者和运维之间的共同理解,并为他们所构建的软件分担责任。这意味着增加透明度、沟通和协作,并在开发、IT/运维和 “业务”之间进行合作。
如果将其实际应用到Helm chart维护和一般的基础架构配置中,就会把大部分的责任放在应用开发者的手中。他们也会承担起“Deployer”的角色,并改变他们拥有的仓库中的配置。
系统工程师仍然可以把他们专门维护的设置集中起来。例如,一些团队也会维护一个中央基础架构repo,该repo中保存着Terraform配置或Helm文件等常用资源,这些资源是启动新项目所需要的(例如,用于设置ingress controller和cert manager)。Helm 3还支持所谓的 “library chart”,它只能作为另一个chart的一部分进行部署。这让我们更容易区分常见的和服务特定的变更责任。
即使当chart存储在服务仓库中,系统工程师仍然可以作为重要更改的把关人。例如,你可以使用GitHub CODEOWNERS文件来确保系统工程师在你的repo中的chart目录中的任何更改都会被添加为审核者。
如果系统工程师需要主动做一些与应用开发无关的改动,可以指导开发人员为他们做更改,并解释为什么这些改动是必须的。以下图片也许能反映这种情况:
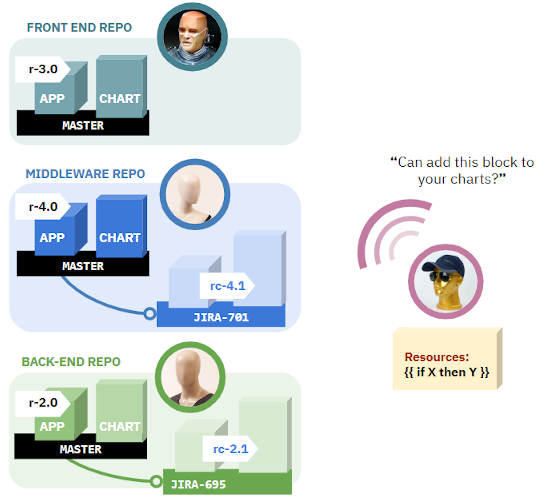
开发者可以了解更多关于基础设施的内容以及这些更改如何影响他们的服务。
经验法则
如果有简单的经验法则,那就是:先了解选项3。尝试为服务仓库中的每个服务维护一个Helm chart。或者至少考虑一下我之前描述的混合方法。
如果你有几十个服务都非常相似,那么共享chart是更好的选择。只是要记住,你必须把它维护在一个中心repo中。但是这增加了意外耦合的风险,可能会破坏一个服务部署。风险增加意味着你在部署的时候需要更加谨慎,这反过来又意味着你会减少部署的频率。
即使你有特定服务的chart,你可能也需要集中存储,因为你没有足够的人员或专业知识以分布式的方式来管理这些chart。或者,也许你的团队需要在“Deployer”和“应用开发者”之间明确划分责任。
无论你决定做什么,我希望我已经说明清楚了你在做最后决定时需要考虑的问题。做一个“Deployer”并不容易,尤其是当它不是你的日常工作时。
作者:Merlin Carter,专注于早期创业公司的风险投资家,擅长撰写开发人员创新和新技术的文章


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。