
摘要:简单介绍Raft协议的原理、以及存储节点(Pinetree)如何应用 Raft实现复制的一些工程实践经验。
1、引言
在华为分布式数据库的工程实践过程中,我们实现了一个计算存储分离、 底层存储基于Raft协议进行复制的分布式数据库系统原型。下面是它的架构图。
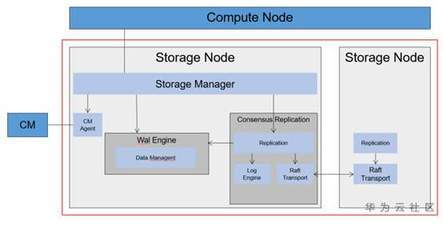
计算节点生成日志经过封装后通过网络下发到存储节点,在Raft层达成一致后日志被应用到状态机wal Engine,完成日志的回放和数据的存储管理。
下面简单介绍一下Raft的原理、以及存储节点(Pinetree)如何应用 Raft实现复制的一些工程实践经验。
2、Raft的原理
2.1 Raft的基本原理
Raft 算法一切以领导者为准,实现一系列值的共识和各节点日志的一致。下面重点介绍一下Raft协议的Leader选举、log复制 和 成员变更。
Raft的选举机制:
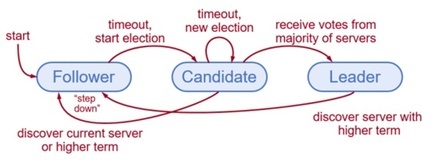
协议为每个节点定义了三个状态:Leader、Candidate、Follower,将时间定义为Term,每个Term有一个ID。Term类似逻辑时钟,在每个Term都会有Leader被选举出来。
Leader负责处理所有的写请求、发起日志复制、定时心跳,每个Term期间最多只能有一个Leader,可能会存在选举失败的场景,那么这个Term内是没有Leader。
Follower 处于被动状态,负责处理Leader发过来的RPC请求,并且做出回应。
Candidate 是用来选举一个新的Leader,当Follower超时,就会进入Candidate状态。
初始状态,所有的节点都处于Follower状态,节点超时后,递增current Term进入Candidate,该节点发送广播消息RequestVote RPC给其他Follower请求投票。当收到多数节点的投票后,该节点从Candidate进入Leader。Follower在收到投票请求后,会首先比较Term,然后再比较日志index,如果都满足则更新本地Current Term然后回应RequestVote RPC为其投票。每个Term期间,follower只能投一次票。
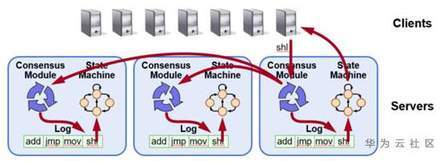
Raft的日志同步机制:
当Leader被选举出来后,就可以接受写请求。每个写请求即代表了用户需要复制的指令或Command。Raft协议会给写请求包装上Term和Index,由此组成了Raft的Log entry. Leader把Log entry append到日志中,然后给其它的节点发AppendEntries RPC请求。当Leader确定一个Log entry被大多数节点已经写入日志当中,就apply这条Log entry到状态机中然后返回结果给客户端。
Raft成员变更机制:
成员变更就意味着集群节点数的增加或减少以及替换。Raft协议定义时考虑了成员变更的场景,从而避免由于集群变化引起的系统不可用。Raft是利用上面的Log Entry和一致性协议来实现该功能。成员的变更也是由Leader发起的,Leader会在本地生成一个新的Log entry,同时将Log entry推送到其他的Follower节点。
Follower节点收到Log entry后更新本地日志,并且应用该log中的配置关系。多数节点应用后,Leader就会提交这条变更log entry。还要考虑新就配置的更替所带来的问题。更详细的不再赘述。
2.2 Raft的开源实现
Raft的实现有coreos的etcd/raft、kudu、consul、logcabin、cockroach等。
Etcd 、LogCabin 、Consul 实现的是单个Raft环,无法做到弹性伸缩。而kudu和cockroach实现了多个raft环。kudu的consensus 模块实现了副本的数据复制一致性,kudu将数据分片称之为Tablet, 是kudu table的水平分表,TabletPeer就是在Raft环里面的一个节点. 一个Tablet相当于一个Raft环,一个Tablet对应一个Raft Consensus,这些对应Raft里面的一个环,Consensus Round相当于同步的消息,一个环之间会有多个Consensus Round做同步。而cockroach则是基于etcd/raft实现的多Raft环,它维护了多个Raft实例,被称之为multiraft。
因为Etcd的Raft是目前功能较全的Raft实现之一,最早应用于生产环境,并且做到了很好的模块化。其中Raft内核部分实现了Raft大部分协议,而对外则提供了storage和transport所用的interface,对于使用者可以单独实现灵活性较高,用户还可以自主实现 snapshot、wal ,Raft非常便于移植和应用,因此存储节点Pinetree采用了开源的Etcd中的Raft实现来构建我们的原型系统,也便于后期向Multiraft演进。。
3、工程实践
3.1 实现Raft的存储接口和网络传输
Raft存储部分指的是raft- log的存储,是对日志条目进行持久化的存储,通过benchmark测试发现,raft-log引擎性能是影响整体ops的主要瓶颈,为了更灵活的支持底层存储引擎的快速替换,增加可插拔的存储引擎框架,我们对底层存储引擎进行解耦。Pinetree封装了第三方独立存储接口来适配etcd raft的log存储接口;
通讯部分即Raft Transport、snapShot传输等,采用GRPC+Protobuf来实现,心跳、日志传输AppendEntries RPC、选举RequestVote RPC等应用场景将GRPC设置为简单式,snapShot设置为流式的形式。
3.2 选举问题
Raft可以实现自我选举。但是在实践中发现缺点也很明显,Raft自主选主可能存在如下的问题:
1、不可控:可能随意选择一个满足Raft条件的节点
2、网络闪断导致Leader变动
3、节点忙导致的Leader变动
4、破坏性的节点
为了防止存储节点Leader在不同的AZ或者节点间进行切换,Pinetree采用的方案是由集群管理模块来指定 Leader。Pinetree中将electionTimeout设置为无穷大,关闭Follower可能触发的自动选举过程,一切选举过程由集群管理的建议选主模块来控制。
3.3 读一致性模型
在 Raft 集群中,一般会有 default、consistent、stale 三种一致性模型,如何实现读操作关乎一致性的实现。一般的做法是将一致性的选择权交给用户,让用户根据实际业务特点,按需选择,灵活使用。
Consistent具有最高的读一致性,但是实现上要求所有的读请求都要走一遍Raft 内核并且将会与写操作串行,会给集群造成一定的压力。stale具有很好的性能优势,但是读操作可能会落到数据有延迟的节点上。在Pinetree的设计中,集群管理负责维护存储节点的信息,管理所有节点的Raft主副本的状态,一方面可以对读请求进行负载均衡,另一方面可以根据AZ亲和性、副本上的数据是否有最新的log 来路由读请求。这样在性能和一致性之间进行了最大的tradeoff。
3.4 日志问题
Raft以Leader为中心进行复制需要考虑几个问题:
1、性能问题,如果leader为慢节点会导致长尾
2、日志的同步必须是有序提交
3、切换leader时有一段时间的不可用
问题3我们通过集群管理来最大程度的防止Leader的切换。
对于问题2,因为Pinetree的日志类似innodb的redo log ,采用LSN来编号的,所以应用到Pinetree存储层的的日志必须要保序,不能出现跳过日志段或日志空洞的情况。这就要求发给Raft的日志要做保序处理。计算层产生的wal log都对应一个LSN,LSN代表的是日志在文件中的偏移量,具有单调递增且不连续的特点。因此要求Wal log产生的顺序和apply到pinetree storage的顺序要保证一致。为了满足这一需求,我们在计算层和Raft层中间增加一个适配层,维护一个队列负责进行排序,同时为了应对计算层主备的切换,对消息增加Term以保证日志不会乱序。Raft指令还可能会被重复提交和执行,所以存储层要考虑幂等性的问题。因为Pinetree storage的日志用LSN进行编号,所以可以进行重复apply。
3.5 如何解决假主问题
计算节点需要获取某些元数据信息,每次都必须从Leader中读取数据防止出现备机延迟。在网络隔离的情况下,老的leader不会主动退出,会出现双主的情况,这个假主可能永远不知道自己其实已经不是真正的Raft主节点,导致真Leader和假Leader同时存在并提供读服务,这在无延迟系统是不允许的。
如果每次读请求都走一遍Raft协议可以识别出假主,但是将会严重的影响系统的性能。
Pinetree是通过租约(lease)的方式,让一个Pinetree主节点在提供服务之前,保守地检查自身在这一时刻是否拥有lease,再决定自身能不能提供读服务。因此,就算访问了一个Pinetree假主,假主也因为没有lease而不能提供服务。
3.6 性能问题
涉及到性能Pinetree考虑和优化的地方:
1 如果使用 Raft 算法 保证强一致性,那么读写操作都应该在领导者节点上进行。这样的话,读的性能相当于单机,不是很理想, 优化实现了基于leader+lease的方式来提供读服务即能保证一致性又不影响性能。
2 优化raft参数 :in-flight的数目;transport queue的数量
3 最大限度的异步化,例如:指令在raft达成一致完成持久化后传递给状态机存入消息队列立即返回,后续对消息进行异步并行解析。
4 最大限度的进行Batch和Cache。例如:把一个事务内的写操作缓存到客户端,在事务提交时,再把所有的写打包成一个batch与事务commit请求一起发送给服务端
#DevRun开发者沙龙# 9月15日20:00-21:00,特邀华为云数据库解决方案专家Sugar,为您打造专场直播“端到端安全可信,华为云数据库解决方案最佳实践”!华为云数据库服务,聚焦互联网、车企、金融、游戏、ISV、地图等行业痛点,满足企业用户多样性计算需求。提供端到端安全可信的解决方案,帮助企业应用全面云化和智能化。欢迎点击直播(http://live.vhall.com/206537223)围观,社区互动(https://bbs.huaweicloud.com/forum/thread-76193-1-1.html)有礼!


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。