
Livy探究(一) -- 初体验
Livy探究(二) -- 运行模式
Livy探究(三) -- 核心架构细节探索
Livy探究(四) -- 从es读取数据
Livy探究(五) -- 解释器的实现
Livy探究(六) -- RPC的实现
Livy探究(七) -- 编程接口分析
Livy是Apache的开源项目,目前仍然处于孵化阶段。它提供了一种通过restful接口执行交互式spark任务的机制。通过它可以进一步开发交互式的应用。当然,交互式spark应用其实有许多实现。本系列与大家一起对Livy做个探索
简介
提交spark任务一般有两种方式:
- 通过
spark shell编写交互式的代码 - 通过
spark submit提交编写好的jar包到集群上运行,执行批处理任务
Livy把交互式和批处理都搬到了web上,提供restful接口,下面是Livy的架构图:
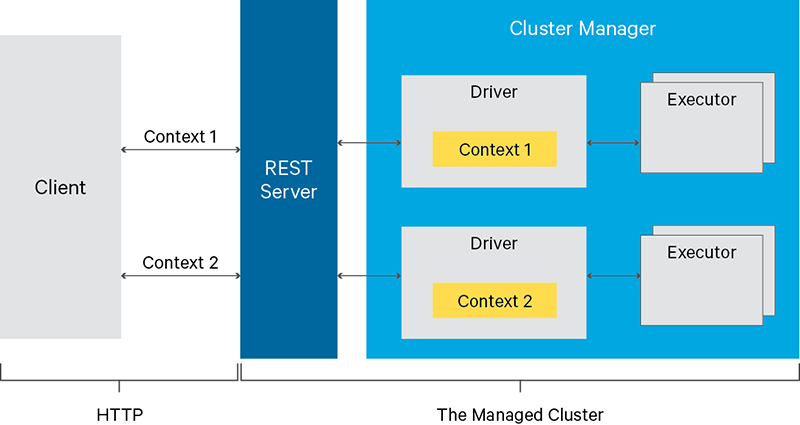
Livy会为用户运行多个session,每个session就是一个常驻的spark context。用户通过restful接口在对应的spark context执行代码。session可以运行在local模式,standalone集群或者yarn集群模式下。
借助Livy或者其思想,我们主要是希望可以开发交互式数据平台。
安装
选一台Hadoop集群中的机器,从Livy官网下载livy:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zipLivy依赖spark,所以另外需要下载和解压好spark
设置好spark环境,例如
export SPARK_HOME=/home/spark-2.4.1-bin-hadoop2.7设置好hadoop环境,例如
export HADOOP_CONF_DIR=/etc/hadoop/conf运行livy:
bin/livy-server start由于我的hadoop开启了kerberos认证,所以会报错。通过报错的提示,我们需要配置一下kerberos:
cp conf/livy.conf.template conf/livy.conf
vi conf/livy.conf
# 增加如下两行
livy.server.launch.kerberos.principal=spark1@xxxxx.COM
livy.server.launch.kerberos.keytab=/var/keytab/spark1.keytabLivy启动后,默认监听端口为8998,通过web访问这个端口:

提示还没有创建任何session,接下来我们通过官网的example启动一个交互式session
第一个session
在交互式python中,运行如下python代码,提交一个session,并尝试运行一个scala命令1 + 1(注意替换其中的host):
import json, pprint, requests, textwrap
host = 'http://vm3198:8998'
data = {'kind': 'spark'}
headers = {'Content-Type': 'application/json'}
r = requests.post(host + '/sessions', data=json.dumps(data), headers=headers)
# 此处会提交一个spark类型的session,稍等几秒后继续
statements_url = host + r.headers['location'] + '/statements'
data = {'code': '1 + 1'}
r = requests.post(statements_url, data=json.dumps(data), headers=headers)
# 此处会将1+1这个scala语句提交到服务端执行,执行是异步的,所以等几秒钟后,通过接口查看结果
statement_url = host + r.headers['location']
r = requests.get(statement_url, headers=headers)
pprint.pprint(r.json())
{'code': '1 + 1',
'completed': 1601521233533,
'id': 0,
'output': {'data': {'text/plain': 'res0: Int = 2n'},
'execution_count': 0,
'status': 'ok'},
'progress': 1.0,
'started': 1601521233404,
'state': 'available'}通过web看下创建的session和执行的语句:

观察服务器启动的进程:
.../java -cp /home/spark-2.4.1-bin-hadoop2.7/conf/:/home/spark-2.4.1-bin-hadoop2.7/jars/*:/etc/hadoop/conf/ -Xmx1g org.apache.spark.deploy.SparkSubmit \
--properties-file /tmp/livyConf142660555568889215.properties \
--class org.apache.livy.rsc.driver.RSCDriverBootstrapper spark-internal可以看到,livy运行了一个SparkSubmit,driver类为org.apache.livy.rsc.driver.RSCDriverBootstrapper,更重要的是看下生成的临时配置文件,其中比较关键的配置如下:
...
spark.master=local
spark.jars=/home/apache-livy-0.7.0-incubating-bin/rsc-jars/netty-all-4.0.37.Final.jar,/home/apache-livy-0.7.0-incubating-bin/rsc-jars/livy-api-0.7.0-incubating.jar,/home/apache-livy-0.7.0-incubating-bin/rsc-jars/livy-rsc-0.7.0-incubating.jar,/home/apache-livy-0.7.0-incubating-bin/rsc-jars/livy-thriftserver-session-0.7.0-incubating.jar,/home/apache-livy-0.7.0-incubating-bin/repl_2.11-jars/livy-core_2.11-0.7.0-incubating.jar,/home/apache-livy-0.7.0-incubating-bin/repl_2.11-jars/commons-codec-1.9.jar,/home/apache-livy-0.7.0-incubating-bin/repl_2.11-jars/livy-repl_2.11-0.7.0-incubating.jar
spark.__livy__.livy.rsc.driver-class=org.apache.livy.repl.ReplDriver
...可以看到livy是使用local模式启动的SparkContext。这些信息对于我们后续分析源码是很重要的,相当于执行的入口。
接下来再创建一个经典的PI任务。依然是通过python交互模式,运行如下代码
# 再创建一个statement,用于执行PI任务
data = {
'code': textwrap.dedent("""
val NUM_SAMPLES = 100000;
val count = sc.parallelize(1 to NUM_SAMPLES).map { i =>
val x = Math.random();
val y = Math.random();
if (x*x + y*y < 1) 1 else 0
}.reduce(_ + _);
println("Pi is roughly " + 4.0 * count / NUM_SAMPLES)
""")
}
r = requests.post(statements_url, data=json.dumps(data), headers=headers)
statement_url2 = host + r.headers['location']
# 稍等几秒钟,等待执行完成,检查执行结果
r = requests.get(statement_url2, headers=headers)
pprint.pprint(r.json())
{'code': '\n'
'val NUM_SAMPLES = 100000;\n'
'val count = sc.parallelize(1 to NUM_SAMPLES).map { i =>\n'
' val x = Math.random();\n'
' val y = Math.random();\n'
' if (x*x + y*y < 1) 1 else 0\n'
'}.reduce(_ + _);\n'
'println("Pi is roughly " + 4.0 * count / NUM_SAMPLES)\n',
'completed': 1601522536564,
'id': 1,
'output': {'data': {'text/plain': 'NUM_SAMPLES: Int = 100000\n'
'count: Int = 78560\n'
'Pi is roughly 3.1424\n'},
'execution_count': 1,
'status': 'ok'},
'progress': 1.0,
'started': 1601522534363,
'state': 'available'}再次看下web界面,增加了一个statements:

总结
通过第一个session的实验,我们可以掌握如何通过livy的restful接口创建session,并在同一个session(同一个SparkContext)中执行多个交互式的代码。并且livy默认启动的是local模式的SparkContext。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。