
简介
kube-router是一套开源网络方案,基于bgp协议构建路由,从而构建整个容器集群网络,它使用ipvs实现了k8s的service网络,并使用ipset和iptables工具实现了networkpolicy。
我们知道calico对于networkpolicy的实现也是ipset+iptables这一套,本文将结合源码和实例,介绍kube-router是如何实现networkpolicy的,并分析它与calico在设计上的异同。
简要概括
kube-router在节点上启动一个agent同步pod、networkpolicy对象的信息, 并构建iptables规则和ipset集合。主要的程序入口在func (npc *NetworkPolicyController) fullPolicySync()。读者可以自己阅读源码,挺清晰的。
规则处理分为四步:
- 顶层规则集:
npc.ensureTopLevelChains() - networkpolicy粒度的规则集:
networkPoliciesInfo, err = npc.buildNetworkPoliciesInfo() ; activePolicyChains, activePolicyIPSets, err := npc.syncNetworkPolicyChains(networkPoliciesInfo, syncVersion) - pod粒度规则集:
activePodFwChains, err := npc.syncPodFirewallChains(networkPoliciesInfo, syncVersion) - 清理stale规则
err = cleanupStaleRules(activePolicyChains, activePodFwChains, activePolicyIPSets)
整体上的链路如下图:
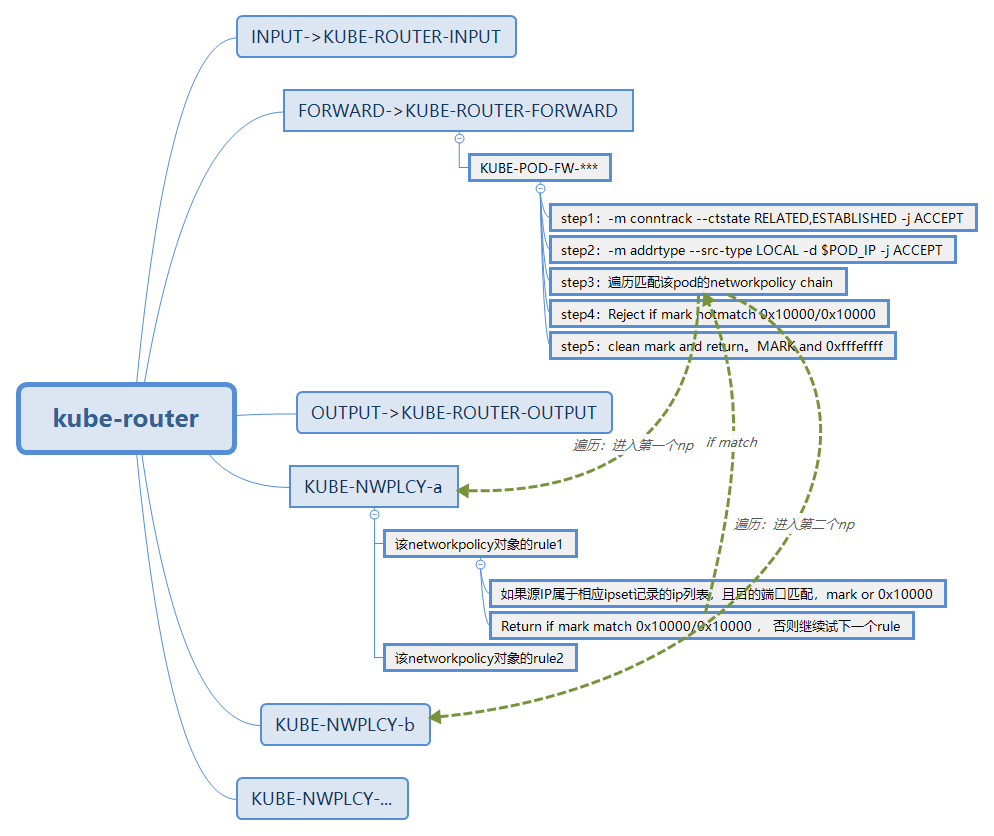
下面我们将详细介绍各个规则集的设计。
顶层规则集
与calico一样,在INPUT/FORWARD/OUTPUT三个地方做hook。分别hook到KUBE-ROUTER-INPUT、KUBE-ROUTER-FORWARD、KUBE-ROUTER-OUTPUT。
KUBE-ROUTER-FORWARD、KUBE-ROUTER-OUTPUT两个链中没有什么特殊的规则,直接就进入到了各个pod粒度的规则集中。
KUBE-ROUTER-INPUT链中做了一些特殊目的地址的egress白名单,如下:
- 允许访问service cidr
-d $SERVICE_RANGE -j RETURN - 允许访问nodeport port range
-p tcp/udp -m addrtype --dst-type LOCAL -m multiport --dports $NODEPORT_RANGE -j RETURN - 允许访问service external ip
-d $SERVICE_EXTERNAL_RANGE -j RETURN - 各个pod的规则
这里有两个疑问:
- 为什么允许访问service、nodeport等地址?社区有过一次讨论,话题就是:service地址是否要作为networkpolicy禁止访问的对象?kube-router设计上认为没必要,只需要将service的endpoint,也就是pod IP作为networkpolicy禁止访问的对象就够了。
- 为什么这部分是放在KUBE-ROUTER-INPUT链中呢?我们思考一下,当我们用iptables模式运行keub-proxy时,k8s service的nat规则是在宿主机的PREROUTING链中的,pod里访问service时,host-veth的PREROUTING链中做了NAT后,目的IP应该就不会再是service IP了呀。
但是,在ipvs模式、或者kube-router自己实现的vip方案下,service的ClusterIP会绑在宿主机上的某个dummy网卡(当我们使用ipvs模式的kube-proxy时,这块网卡名字是kube-ipvs0)上,pod访问service的包会由local路由发到这块dummy网卡,并经过dummy网卡的INPUT链。由于ipvs方案下,必须由dummy网卡INPUT后,才会进行转发,所以为了能让pod正常访问service,我们至少要在INPUT链放行。
networkpolicy粒度规则集
networkpolicy粒度的规则以KUBE-NWPLCY为前缀,一个规则一个链。
来个例子:
Chain KUBE-NWPLCY-4UOMHLJABMXP4VW2 (1 references)
target prot opt source destination
MARK all -- anywhere anywhere /* rule to ACCEPT traffic from source pods to dest pods selected by policy
name access-pod namespace default */ match-set KUBE-SRC-IMXDMRGLZFP7QJCX src match-set KUBE-DST-5CXCQ5O6AOA47RC6 dst /* rule to mark traf
fic matching a network policy */ MARK or 0x10000
RETURN all -- anywhere anywhere /* rule to ACCEPT traffic from source pods to dest pods selected by policy
name access-pod namespace default */ match-set KUBE-SRC-IMXDMRGLZFP7QJCX src match-set KUBE-DST-5CXCQ5O6AOA47RC6 dst /* rule to RETURN tr
affic matching a network policy */ mark match 0x10000/0x10000
MARK all -- anywhere anywhere /* rule to ACCEPT traffic from source pods to specified ipBlocks selected b
y policy name: access-pod namespace default */ match-set KUBE-SRC-5CXCQ5O6AOA47RC6 src match-set KUBE-DST-7VKW2UTKN2UOEU4I dst /* rule to
mark traffic matching a network policy */ MARK or 0x10000
RETURN all -- anywhere anywhere /* rule to ACCEPT traffic from source pods to specified ipBlocks selected b
y policy name: access-pod namespace default */ match-set KUBE-SRC-5CXCQ5O6AOA47RC6 src match-set KUBE-DST-7VKW2UTKN2UOEU4I dst /* rule to
RETURN traffic matching a network policy */ mark match 0x10000/0x10000一个KUBE-NWPLCY-*** chain里描述了一个networkpolicy对象, 对于该对象的每一个rule(ingress or egress),我们都会有如下的操作:
- 判断源地址+端口/目的地址+端口是否符合ingress/egress rule。如果符合就打mark:
MARK or 0x10000。 这里的地址匹配,是一个ipset - 判断mark是否匹配
mark match 0x10000/0x10000, 如果匹配,return ,如果不匹配, 再检查下一个rule的规则。
pod粒度规则集
从顶层规则集中,kube-router基于包的源/目的 IP跳转到相应的pod粒度规则集。
如何进入pod粒度集
因为kube-router对接的网络插件是官方的bridge插件, node上容器host-veth都绑在网桥上,pod彼此之间属于二层互联(包直接桥接转发)
所以同一个node上的pod-to-pod 的包会直接在bridge进行二层转发,这类包必须要经由如下的iptables规则处理:
-t filter KUBE-ROUTER-FORWARD -m physdev --physdev-is-bridged -m comment --comment "******" -d $POD_IP -j KUBE-POD-FW-XXXXX (匹配某个pod的ingress policy) 例:同node的pod要访问本pod,node对pod做健康检查
-t filter KUBE-ROUTER-FORWARD -m physdev --physdev-is-bridged -m comment --comment "******" -s $POD_IP -j KUBE-POD-FW-XXXXX (匹配某个pod的egress policy) 例:本pod要访问同node其他pod注意:
XXXXX是pod的ns+name的hash,但格式与calico不一样- 同一个node上的pod-to-pod走二层转发,这个过程想要被netfilter hook,需要加载br_netfilter模块,并且开启
/proc/sys/net/bridge/bridge-nf-call-iptables,/proc/sys/net/bridge/bridge-nf-call-ip6tables为1
除此之外的包,都是通过对方向、src或dst IP的匹配,来进入特定pod的规则链。例如:
-t filter KUBE-ROUTER-FORWARD -d $POD_IP -j KUBE-POD-FW-XXXXX (匹配某个pod的ingress policy) 例:其他节点(及上的pod)访问pod
-t filter KUBE-ROUTER-OUTPUT -d $POD_IP -j KUBE-POD-FW-XXXXX (匹配某个pod的ingress policy)
-t filter KUBE-ROUTER-INPUT -s $POD_IP -j KUBE-POD-FW-XXXXX (匹配某个pod的egress policy) 例:pod访问其他任何地址
-t filter KUBE-ROUTER-FORWARD -s $POD_IP -j KUBE-POD-FW-XXXXX (匹配某个pod的egress policy)
-t filter KUBE-ROUTER-OUTPUT -s $POD_IP -j KUBE-POD-FW-XXXXX (匹配某个pod的egress policy)
pod粒度规则集里有什么?
ingress policy
在KUBE-POD-FW-XXXXX链中,添加了若干规则:
一、 已经建立的连接,直接接受
-t filter KUBE-POD-FW-XXXXX -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT二、 所有从node访问过来的包,都予以接受
-t filter KUBE-POD-FW-XXXXX -m addrtype --src-type LOCAL -d $POD_IP -j ACCEPT三、 其他情况下,需要基于匹配该pod的每个ingress policy,都添加一条jump规则:
-t filter KUBE-POD-FW-XXXXX -j XXXXXXXXX (XXXXXXXXX表示作用于该pod的第一个networkpolicy的ns+name的hash)
-t filter KUBE-POD-FW-XXXXX -j XXXXXXXXY (XXXXXXXXY表示作用于该pod的第二个networkpolicy的ns+name的hash)
...egress policy
一、 已经建立的连接,直接接受
-t filter KUBE-POD-FW-XXXXX -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT二、 其他情况下,需要基于匹配该pod的每个egress policy,都添加一条jump规则:
-t filter KUBE-POD-FW-XXXXX -j XXXXXXXXX (XXXXXXXXX表示作用于该pod的第一个networkpolicy的ns+name的hash)
-t filter KUBE-POD-FW-XXXXX -j XXXXXXXXY (XXXXXXXXY表示作用于该pod的第二个networkpolicy的ns+name的hash)
...示例
Chain KUBE-POD-FW-VFY4MIYKQH6U2ZBK (7 references)
target prot opt source destination
ACCEPT all -- anywhere anywhere /* rule for stateful firewall for pod */ ctstate RELATED,ESTABLISHED
ACCEPT all -- anywhere 10.0.0.24 /* rule to permit the traffic traffic to pods when source is the pod's loca
l node */ ADDRTYPE match src-type LOCAL
KUBE-NWPLCY-4UOMHLJABMXP4VW2 all -- anywhere anywhere /* run through nw policy access-pod */
KUBE-NWPLCY-TOUTUXPCBONZJXQA all -- anywhere anywhere /* run through nw policy access-pod-and-node */
NFLOG all -- anywhere anywhere /* rule to log dropped traffic POD name:hyserver-d4f9cf4df-55ggn namespace:
default */ mark match ! 0x10000/0x10000 limit: avg 10/min burst 10 nflog-group 100
REJECT all -- anywhere anywhere /* rule to REJECT traffic destined for POD name:hyserver-d4f9cf4df-55ggn na
mespace: default */ mark match ! 0x10000/0x10000 reject-with icmp-port-unreachable
MARK all -- anywhere anywhere MARK and 0xfffeffff
我们注意到,先是Accept了已成立的连接和来自宿主机的IP, 然后就会遍历所有的networkpolicy,全部走一遍后,判断mark,如果mark不匹配,打印日志,并且reject,如果匹配,我们将用于标记的那一位再置0:MARK and 0xfffeffff
集成
令人欣喜的是,kube-router的设计具备很高的兼容性,并且由于它是以pod的status.podIP为pod的规则执行入口,所以对于pod的网卡设计没有任何要求,我们基本做到了即插即用。这比起calico的felix方案方便太多了。
在VPC环境下的K8S集群中,只需要部署如下的模板即可在集群中运行kube-router,且该kube-router只会基于集群的pod/network-policy对象信息,构建iptables/ipset规则。
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
k8s-app: kube-router
tier: node
name: kube-router
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: kube-router
tier: node
template:
metadata:
labels:
k8s-app: kube-router
tier: node
spec:
priorityClassName: system-node-critical
serviceAccountName: kube-router
serviceAccount: kube-router
containers:
- name: kube-router
image: docker.io/cloudnativelabs/kube-router
imagePullPolicy: Always
args:
- --run-router=false
- --run-firewall=true
- --run-service-proxy=false
- --bgp-graceful-restart=true
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
livenessProbe:
httpGet:
path: /healthz
port: 20244
initialDelaySeconds: 10
periodSeconds: 3
resources:
requests:
cpu: 250m
memory: 250Mi
securityContext:
privileged: true
volumeMounts:
- name: lib-modules
mountPath: /lib/modules
readOnly: true
- name: kubeconfig
mountPath: /var/lib/kube-router/kubeconfig
readOnly: true
- name: xtables-lock
mountPath: /run/xtables.lock
readOnly: false
hostNetwork: true
tolerations:
- effect: NoSchedule
operator: Exists
- key: CriticalAddonsOnly
operator: Exists
- effect: NoExecute
operator: Exists
volumes:
- name: lib-modules
hostPath:
path: /lib/modules
- name: kubeconfig
hostPath:
path: /var/lib/kube-router/kubeconfig
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-router
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kube-router
namespace: kube-system
rules:
- apiGroups:
- ""
resources:
- namespaces
- pods
- services
- nodes
- endpoints
verbs:
- list
- get
- watch
- apiGroups:
- "networking.k8s.io"
resources:
- networkpolicies
verbs:
- list
- get
- watch
- apiGroups:
- extensions
resources:
- networkpolicies
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kube-router
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-router
subjects:
- kind: ServiceAccount
name: kube-router
总结
根据对kube-router的实现判断,可以看出它和calico-felix在实现上的一些区别。kube-router的规则脉络更清晰,更简单,而且有充分的comment进行判断和跟踪。最重要的是,它是基于pod IP进行匹配的; felix在规则上更复杂,但是做了一些优化,所以从设计上看,性能应该会比kube-router更好。体现在:
- felix基于网卡做前缀判断pod流量,相比于根据pod IP(记录于etcd)更准确靠谱一些
- felix基于网卡前缀做分表,可以节省遍历时间
- felix在任何一个networkpolicy规则匹配后直接return,不需要遍历所有networkpolicy。
kube-router优点主要体现在兼容性:
- 兼容IPVS模式的kube-proxy
- 以pod IP为policy入口,理论上可以无缝兼容各种“经过宿主机协议栈”的网络方案
- 部署更为简洁
所以使用上心智负担会更少。
问题
kube-router仍然有一些功能上的问题,笔者在进行一系列的测试后,发现了两个较为重要的问题,并反馈给了社区。整理如下:
问题1
通过在集群中部署kube-router,并使用sonobuoy进行networkpolicy相关的用例测试,我们发现kube-router在29个测试用例中会有一个失败:
should allow egress access on one named port也就是说,当networkpolicy的Egress规则中,To为空(表示对应所有的dst)且存在namedport(k8s中用来描述port的name字段)时,无法对这类port进行egress放行。
问题2
当我们临时修改pod的label,使其匹配某项networkpolicy规则时,对于该pod,这个规则无法生效。
附录
calico中networkpolicy的实现
iptables中physdev选项的说明
--physdev-in [name|prefix+|!name] 匹配从name端口进入网桥的数据包。(作用于INPUT、FORWARD和PREROUTING链),可以通过'+'对端口名进行前缀匹配。'!name'用于反向匹配。
--physdev-out [name|prefix+|!name] 匹配从name端口发出的数据包。(作用于FORWARD、OUTPUT和POSTROUTING链)
--physdev-is-in 匹配进入网桥数据包
--physdev-is-out 匹配离开网桥数据包
--physdev-is-bridged 匹配被桥接不是被路由的数据包。(作用于FORWARD和POSTROUTING链)






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。