
最近参加公司组织的Node学习小组,每个人认领不同的知识点,并和组内同学分享。很喜欢这样的学习形式,除了可以系统学习外,还能倒逼自己输出,收获颇多,把自己准备的笔记分享出来。
- 简介
Buffer
- 简介
- 编码
- 内存分配机制
- API概览
stream
- 简介
- 可读流
- 可写流
- 双工流
- 实现与使用
简介
Buffer是数据以二进制形式临时存放在内存中的物理映射,stream为搬运数据的传送带和加工器,有方向、状态、缓冲大小。

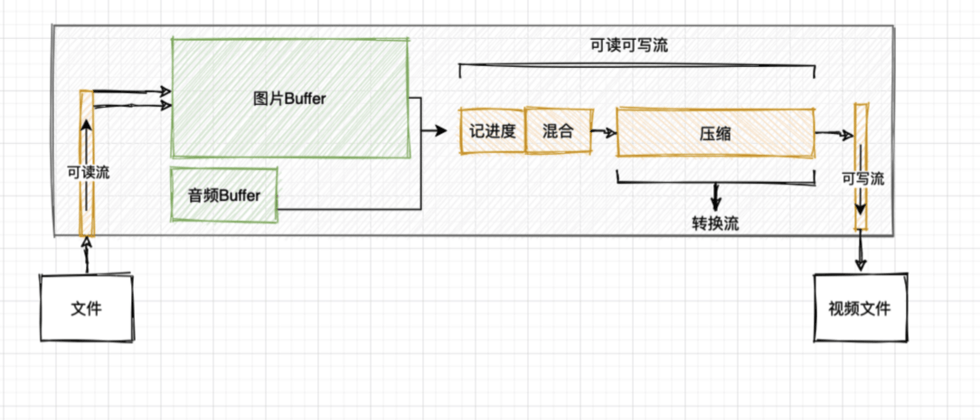
比如我们实现一个将图片和音频读取到内存然后加工为的视频程序,类似于将原料运输到工厂然后加工为月饼的流程。
Buffer
简介
缓冲区
数据的移动是为了处理或读取它,如果数据到达的速度比进程消耗的速度快,那么少数早到达的数据会处于等待区等候被处理。
《Node.js 中的缓冲区(Buffer)究竟是什么?》

我们读一个秘钥文件进入内存,肯定是等整个文件读入内存后再处理,要提前划分存放的空间。
就像摆渡车一样,坐满了20位才发车,乘客有早到有晚到,必须有一个地方等候,这就是缓冲区。
Buffer是数据以二进制形式临时存放在内存中的物理映射。
早期js没有读取操作二进制的机制,js最初设计是为了操作html。
Node早期为了处理图像、视频等文件,将字节编码为字符串来处理二进制数据,速度慢。
ECMAScript 2015发布 TypedArray,更高效的访问和处理二进制,用于操作网络协议、数据库、图片和文件 I/O 等一些需要大量二进制数据的场景。
Buffer对象用于表示固定长度的字节序列。Buffer类是 JavaScript 的Uint8Array类的子类,且继承时带上了涵盖额外用例的方法。 只要支持Buffer的地方,Node.js API 都可以接受普通的Uint8Array。
-- 官方文档
由于历史原因,早期的JavaScript语言没有用于读取或操作二进制数据流的机制。因为JavaScript最初被设计用于处理HTML文档,而文档主要由字符串组成。
-- 《Node.js 企业级应用开发实践》
总结起来一句话 Node.js 可以用来处理二进制流数据或者与之进行交互。
-- 《Node.js 中的缓冲区(Buffer)究竟是什么?》
编解码
将原始字符串与目标字符串进行互转。
编码:将消息转换为适合传输的字节流。
解码:将传输的字节流转换为> 程序可用的消息格式 --《Node.js企业级应用开发实战》>
Buffer与String传输对比
const http = require('http');
let s = '';
for (let i=0; i<1024*10; i++) {
s+='a'
}
const str = s;
const bufStr = Buffer.from(s);
const server = http.createServer((req, res) => {
console.log(req.url);
if (req.url === '/buffer') {
res.end(bufStr);
} else if (req.url === '/string') {
res.end(str);
}
});
server.listen(3000);# -c 200并发数 -t 等待响应最大时间 秒
$ ab -c 200 -t 60 http://localhost:3000/buffer
$ ab -c 200 -t 60 http://localhost:3000/string
相同的测试参数,Buffer完成请求13998次,string完成请求9237次,相差4761次,Buffer比字符串的的传输更快。

支持格式
Buffer 和字符串之间转换时,默认使用UTF-8,也可以指定其他字符编码格式。

注意事项:
- Buffer => utf8:如遇到非UTF-8数据会转换为 �。
- Buffer => utf16le:每个字符会使用2或4个字节进行编码。
- Buffer => latin1:指定了Unicode编码范围,超出会截断并映射为范围内的字符串。
Tip:buffer不支持的编码类型,gbk、gb2312等可以借助js工具包iconv-lite实现。
--《深入浅出Node.js》
内存分配机制
由于 Buffer 需要处理的是大量的二进制数据,假如用一点就向系统去申请,则会造成频繁的向系统申请内存调用,所以 Buffer 所占用的内存不是由 V8 分配,而是在 Node.js 的 C++ 层面完成申请,在 JavaScript 中进行内存分配。这部分内存称之为堆外内存。
Node.js 采用了 slab 预先申请、事后分配机制。
- new Buffer1 => 创建slab对象1 => new Buffer2 => 判断slab对象1剩余空间是否够用。
- 释放Buffer1、Buffer2对象时,依然保留slab1对象。
- new Buffer3 => 将slab1对象空间划分给 Buffer3。
slab对象的三种状态:

小对象创建
Node以为 8kb 区分大对象与小对象。当创建的小对象时,分配一个slab对象。
再创建一个小对象时,会判断当前的slab对象剩余空间是足够,如果够用则使用剩余空间,如果不够用则分配新的slab空间。
const Buffer1 = new Buffer(1024)
const Buffer2 = new Buffer(4000)


slab分配
slab是Linux操作系统的一种内存分配机制。其工作是针对一些经常分配并释放的对象,这些对象的大小一般比较小,
如果直接采用伙伴系统来进行分配和释放,不仅会造成大量的内存碎片,而且处理速度也太慢。而slab分配器是基于对象进行管理的,相同类型的对象归为一类,每当要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免这些内碎片。
slab分配器并不丢弃已分配的对象,而是释放并把它们保存在内存中。当以后又要请求新的对象时,就可以从内存直接获取而不用重复初始化。
--百度百科 slab
白话:一些小对象经常需要高频次分配、释放 ,导致了 内存碎片和处理速度慢,slab机制是:不丢弃释放的slab对象,将旧slab对象直接分配给新buffer(旧slab对象可能包含旧数据),以此提高性能。
老版本new Buffer、与新版本Buffer.allocUnsafe运行更快,但是内存未初始化,可能导致敏感数据泄露:
手动填充解决:
使用 --zero-fill-buffers 命令行选项解决:
Buffer.alloc 较慢,但更可靠:




API概览

简单使用:
// 指定长度初始化
Buffer.alloc(10)
// 指定填充 1
Buffer.alloc(10, 1)
// 未初始化的缓冲区 比alloc更快,有可能包含旧数据
Buffer.allocUnsafe(10)
//from创建缓冲区
Buffer.from([1,2,3])
Buffer.from('test')
Buffer.from('test','test2')
//类似数据组 可以用 for..of
const buf = Buffer.from([1,2,3])
for(const item of buf){
console.log(item)
}
// 输出
// 1
// 2
// 3Node 6~8 版本使用new Buffer创建:
// 创建实例
const buf1 = new Buffer()
const buf2 = new Buffer(10)
// 手动覆盖
buf1.fill(0)slice/concat/compare:
// 1. 切分
const buf = new Buffer.from('buffer')
console.log(buf.slice(0, 4).toString())
// buff
// 2. 连接
const buf = new Buffer.from('buffer')
const buf1 = new Buffer.from('11111')
const buf2 = new Buffer.from('22222')
const concatBuf = Buffer.concat([buf, buf1, buf2], buf.length + buf1.length + buf2.length)
console.log(concatBuf.toString())
// buffer1111122222
// 3. 比较
const buf1 = new Buffer.from('1234')
const buf2 = new Buffer.from('0123')
const arr = [buf1, buf2]
arr.sort(Buffer.compare)
console.log(arr.toString())
// 0123,1234
const buf3 = new Buffer.from('4567')
console.log(buf1.compare(buf1))
console.log(buf1.compare(buf2))
console.log(buf1.compare(buf3))
// 0 相同
// 1 之前
// -1 之后
stream
简介
流(stream)是 Node.js 中处理流式数据的抽象接口。stream模块用于构建实现了流接口的对象。
Node.js 提供了多种流对象。 例如,HTTP 服务器的请求和process.stdout都是流的实例。
流可以是可读的、可写的、或者可读可写的。
-- 官方文档
什么是 Stream?
流,英文 Stream 是对输入输出设备的抽象,这里的设备可以是文件、网络、内存等。
流是有方向性的,当程序从某个数据源读入数据,会开启一个输入流,这里的数据源可以是文件或者网络等,例如我们从 a.txt 文件读入数据。相反的当我们的程序需要写出数据到指定数据源(文件、网络等)时,则开启一个输出流。当有一些大文件操作时,我们就需要 Stream 像管道一样,一点一点的将数据流出。
--《Node.js 中的缓冲区(Buffer)究竟是什么?》
流是输入输出设备的抽象,数据从设备流入内存为可读流,从内存流入设备为可写,就向水流管道一样,有方向,也有状态(流动、暂停)。
stream 模块主要用于创建新类型的流实例。 对于以消费流对象为主的开发者,极少需要直接使用 stream 模块。
stream有4种类型,所有流都是EventEmitter对象:
- 可读流:Writable
- 可写流:Readabale
- 双工流(可读可写):Duplex
- 转换流:Transform
简单用法:
const { Writable } = require('stream');
const fs = require('fs');
// 可读流实例
const rr = fs.createReadStream('foo.txt');
// 可写流实例
const myWritable = new Writable({
write(chunk, encoding, callback) {
// ...
}
});
// EventEmitter用法
myWritable.on('pipe',function(){
// do some thing
})
myWritable.on('finish',function(){
// do some thing
})
// 可读流推送到可写流
myWritable.pipe(rr)对象模式
Node.js 创建的流都是运作在字符串和Buffer(或Uint8Array)上。 当然,流的实现也可以使用其它类型的 JavaScript 值(除了null)。 这些流会以“对象模式”进行操作。
当创建流时,可以使用objectMode选项把流实例切换到对象模式。 将已存在的流切换到对象模式是不安全的。
-- Node.js v14.16.0
缓冲
highWaterMark选项指定了可缓冲数据大小,即字节总数,对象模式的流为对象总数。
可读流缓冲到达highWaterMark指定的值时,会停止从底层资源读取数据,直到数据被消费。
可写流缓冲到达highWaterMark值时writable.write()返回false。
stream.pipe()会限制缓冲,避免读写不一致导致内存崩溃。
可读流
2种模式
- 暂停Paused模式
- 流动Flowing模式
这两种模式是基于readable.readableFlowing的3种内部状态的一种简化抽象。
- readable.readableFlowing = null 没有提供消费流数据的机制,此时指定data、指定pipe、执行resume 会使值变为true
- readable.readableFlowing = true 调用pause、unpipe会使值变为false
- readable.readableFlowing = false
暂停模式对应null 和false。
选择一种接口风格
Node提供了多种方法来消费流数据。 开发者通常应该选择其中一种方法来消费数据,不要在单个流使用多种方法来消费数据。 混合使用 on('data')、 on('readable')、 pipe() 或异步迭代器,会导致不明确的行为。
const fs = require('fs');
const rr = fs.createReadStream('api.xmind');
const file = fs.createWriteStream('api.xmind.file');
// 1. 可读流绑定可写流
rr.pipe(file)
rr.unpipe(file)
// 2. data end
rr.on('data', (chunk) => {
file.write(chunk)
});
rr.on('end', () => {
file.end()
});
// 3. readable read
rr.on('readable', () => {
const chunk = rr.read()
if(null !== chunk){
file.write(chunk)
}else{
file.end()
}
// 结束时 read()返回null
});
可写流

例子:
const Writable = require('stream').Writable
const writable = Writable()
// 实现`_write`方法
// 这是将数据写入底层的逻辑
writable._write = function (data, enc, next) {
// 将流中的数据写入底层
process.stdout.write(data.toString().toUpperCase())
// 写入完成时,调用`next()`方法通知流传入下一个数据
process.nextTick(next)
}
// 所有数据均已写入底层
writable.on('finish', () => process.stdout.write('DONE'))
// 将一个数据写入流中
writable.write('a' + '\n')
writable.write('b' + '\n')
writable.write('c' + '\n')
// 再无数据写入流时,需要调用`end`方法
writable.end()
// 输出
// A
// B
// C
// DONE%cork/uncork方法
writable.cork() 方法强制把所有写入的数据都缓冲到内存中。 当调用 stream.uncork() 或 stream.end() 方法时,缓冲的数据才会被输出。
stream.cork();
stream.write('一些 ');
stream.write('数据 ');
process.nextTick(() => stream.uncork());如果一个流上多次调用 writable.cork(),则必须调用同样次数的 writable.uncork() 才能输出缓冲的数据。
stream.cork();
stream.write('一些 ');
stream.cork();
stream.write('数据 ');
process.nextTick(() => {
stream.uncork();
// 数据不会被输出,直到第二次调用 uncork()。
stream.uncork();
});双工流
双工流(Duplex)是同时实现了可读、可写的流,包括TCP socket、zlib、crypto。
转换流(Transform)是双工流的一种,例zlib、crypto。
区别:Duplex 虽然同时具备可读流和可写流,但两者是独立的;Transform 的可读流的数据会经过一定的处理过程自动进入可写流。
例子,实现_read、_write方法,将写入数据转为1、2 :
var Duplex = require('stream').Duplex
var duplex = Duplex()
// 可读端底层读取逻辑
duplex._read = function () {
this._readNum = this._readNum || 0
if (this._readNum > 1) {
this.push(null)
} else {
this.push('' + (this._readNum++))
}
}
// 可写端底层写逻辑
duplex._write = function (buf, enc, next) {
// a, b
process.stdout.write('_write ' + buf.toString() + '\n')
next()
}
// 0, 1
duplex.on('data', data => console.log('ondata', data.toString()))
duplex.write('a')
duplex.write('b')
duplex.end()
// 输出
// _write a
// _write b
// ondata 0
// ondata 1转换流是一种特殊双工流,对输入计算后再输入,如加解密、zlib流、crypto流。输入、输入的数据流大小、数据块数量不一定一致。如果可读端的数据没有被消费,可写流的数据可能会被暂停。
例子,通过transform方法实现大小写转换:
const { Transform } = require('stream');
const upperCaseTr = new Transform({
transform(chunk, encoding, callback) {
this.push(chunk.toString().toUpperCase());
callback();
}
});
upperCaseTr.on('data', data => process.stdout.write(data))
upperCaseTr.write('hello, ')
upperCaseTr.write('world!')
upperCaseTr.end()
// 输出 HELLO, WORLD!% 内置转换流
// 使用pipe 创建.gz压缩文件
const fs = require('fs');
const zlib = require('zlib');
const fileName = 'api.xmind'
fs.createReadStream(fileName)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(fileName + '.gz'));// 使用pipe + transform + on 实现进度打印
const fs = require('fs');
const zlib = require('zlib');
const fileName = 'api.xmind'
const { Transform } = require('stream');
const reportProgress = new Transform({
transform(chunk, encoding, callback) {
process.stdout.write('.');
callback(null, chunk);
}
});
fs.createReadStream(fileName)
.pipe(zlib.createGzip())
.pipe(reportProgress)
.pipe(fs.createWriteStream(fileName + '.zz'))
.on('finish', () => console.log('Done'));
// 输出
// ........Done// 使用pipeline方法 实现管道
const { pipeline } = require('stream');
const fs = require('fs');
const zlib = require('zlib');
const fileName = 'api'
// 使用 pipeline API 轻松地将一系列的流通过管道一起传送,并在管道完全地完成时获得通知。
// 使用 pipeline 可以有效地压缩一个可能很大的 tar 文件:
pipeline(
fs.createReadStream(fileName + '.xmind'),
zlib.createGzip(),
fs.createWriteStream( fileName + '.tar.gz'),
(err) => {
if (err) {
console.error('管道传送失败', err);
} else {
console.log('管道传送成功');
}
}
);
// 输出
// 管道传送成功实现与使用
实现
如果实现一个新的流,应继承了四个基本流类之一(
stream.Writeable、stream.Readable、stream.Duplex或stream.Transform),并确保调用了相应的父类构造函数:// 1. 继承 const { Readable } = require('stream'); class Counter extends Readable { constructor(opt) { // do some thing } _read() { // do some thing } }新的流类必须实现一个或多个特定的方法,具体取决于要创建的流的类型,如下图所示:
用例 类 需要实现的方法 只读 Readable_read()只写 Writable_write()、_writev()、_final()可读可写 Duplex_read()、_write()、_writev()、_final()对写入的数据进行操作,然后读取结果 Transform_transform()、_flush()、_final()
避免重写诸如 write()、 end()、 cork()、 uncork()、 read() 和 destroy() 之类的公共方法,或通过 .emit() 触发诸如 'error'、 'data'、 'end'、 'finish' 和 'close' 之类的内部事件。 这样做会破坏当前和未来的流的不变量,从而导致与其他流、流的实用工具、以及用户期望的行为和/或兼容性问题。
使用
// 1. 使用自定义构造函数
const { Readable } = require('stream');
class Counter extends Readable {
constructor(opt) {
// do some thing
}
_read() {
// do some thing
}
}
const myReadable = new Counter()
// 2. 使用原生构造函数
const { Readable } = require('stream');
const myReadable = new Readable({
read(size) {
// do some thing
}
});
// 3. 重写实例方法
const { Readable } = require('stream');
const myReadable = Readable()
myReadable._write = function (buf, enc, next) {
// do some thing
}回顾
- Buffer与stream的类比。
- Buffer为数据缓冲区,Buffer类主要处理二进制。
- Buffer比String更是适合传输。
- slab分配机制:重复使用。
- Buffer的API概览。
- stream是I/O数据流的抽象,有方向、状态、缓冲大小。
- 3种流:可读、可写、可读可写(双工)。
- 双工流中Duplex与Transform区别:读写是否独立。
- stream中Readable、Writable、Duplex、Transform、pipeline的使用。
- 通过继承实现不同类型的流
- 自定义类、构造函数、实例重写3种使用方式
东拼西凑的知识点,如有问题恳请斧正,以防误导他人。







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。