
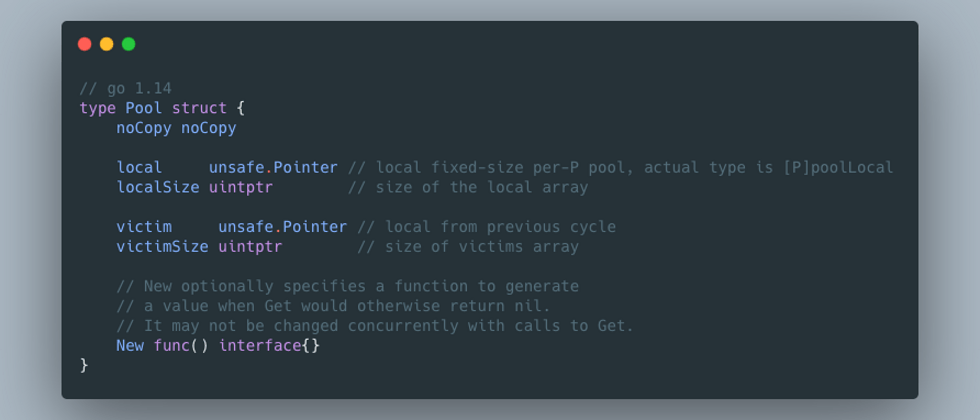
介绍
拥有垃圾回收特性的语言里,gc发生时都会带来性能损耗,为了减少gc影响,通常的做法是减少小块对象内存频繁申请,让每次发生垃圾回收时scan和clean活跃对象尽可能的少。sync.Pool可以帮助在程序构建了对象池,提供对象可复用能力,本身是可伸缩且并发安全的。
主要结构体Pool对外导出两个方法: Get 和 Put,Get是用来从Pool中获取可用对象,如果可用对象为空,则会通过New预定义的func创建新对象。Put是将对象放入Pool中,提供下次获取。

Get
func (p *Pool) Get() interface{} {
if race.Enabled {
race.Disable()
}
l, pid := p.pin()
x := l.private
l.private = nil
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
if x == nil && p.New != nil {
x = p.New()
}
return x
}首先看下GET方法的逻辑(在看前需要对gmp调度模型有大致了解)
- 通过
pin拿到poolLocal和当前 goroutine 绑定运行的P的 id。每个goroutine创建后会挂在P结构体上;运行时,需要绑定P才能在M上执行。因此,对private指向的poolLocal操作无需加锁,都是线程安全的 - 设置
x,并且清空private x为空说明本地对象未设置,由于P上存在多个G,如果一个时间片内协程1把私有对象获取后置空,下一时间片g2再去获取就是nil。此时需要去share中获取头部元素,share是在多个P间共享的,读写都需要加锁,但是这里并未加锁,具体原因等下讲- 如果
share中也返回空,调用getSlow()函数获取,等下具体看内部实现 - runtime_procUnpin()方法,稍后我们详细看
- 最后如果还是未找到可复用的对象, 并且设置了
New的func,初始化一个新对象
Pool的local字段表示poolLocal指针。获取时,优先检查private域是否为空,为空时再从share中读取,还是空的话从其他P中窃取一个,类似goroutine的调度机制。
pin
刚才的几个问题,我们具体看下。首先,pin方法获取当前P的poolLocal,方法逻辑比较简单
func (p *Pool) pin() *poolLocal {
pid := runtime_procPin()
s := atomic.LoadUintptr(&p.localSize) // load-acquire
l := p.local // load-consume
if uintptr(pid) < s {
return indexLocal(l, pid)
}
return p.pinSlow()
}runtime_procPin返回了当前的pid,实现细节看看runtime内部
//go:linkname sync_runtime_procPin sync.runtime_procPin
//go:nosplit
func sync_runtime_procPin() int {
return procPin()
}
//go:linkname sync_runtime_procUnpin sync.runtime_procUnpin
//go:nosplit
func sync_runtime_procUnpin() {
procUnpin()
}
//go:nosplit
func procPin() int {
_g_ := getg()
mp := _g_.m
mp.locks++
return int(mp.p.ptr().id)
}
//go:nosplit
func procUnpin() {
_g_ := getg()
_g_.m.locks--
}pin获取当前goroutine的地址,让g对应的m结构体中locks字段++,返回p的id。unPin则是对m的locks字段--,为什么要这么做?
协程发生调度的时机之一:如果某个g长时间占用cpu资源,便会发生抢占式调度,可以抢占的依据就是locks == 0。其实本质是为了禁止发生抢占。
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
_g_ := getg()
//调度时,会判断`locks`是否为0。
if _g_.m.locks != 0 {
throw("schedule: holding locks")
}
...
}为什么要禁止调度呢?因为调度是把m和p的绑定关系解除,让p去绑定其他线程,执行其他线程的代码段。在get时,首先是获取当前goroutine绑定的p的private,不禁止调度的话,后面的获取都不是当前协程的运行时的p,会污染其他p上的数据,引起未知错误。
poolChain
poolChain是一个双端链表,结构体如下:
type poolChain struct {
head *poolChainElt
tail *poolChainElt
}poolChain.popHead
poolChain.popHead获取时,首先从poolDequeue的popHead方法获取,未获取到时,找到prev节点,继续重复查找,直到返回nil。
func (c *poolChain) popHead() (interface{}, bool) {
d := c.head
for d != nil {
if val, ok := d.popHead(); ok {
return val, ok
}
// There may still be unconsumed elements in the
// previous dequeue, so try backing up.
d = loadPoolChainElt(&d.prev)
}
return nil, false
}这里注意区分poolChain和poolDequeue,两个结构存在同名的方法,但是结构和逻辑完全不同
type poolChain struct {
// head is the poolDequeue to push to. This is only accessed
// by the producer, so doesn't need to be synchronized.
head *poolChainElt
// tail is the poolDequeue to popTail from. This is accessed
// by consumers, so reads and writes must be atomic.
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
next, prev *poolChainElt
}
type poolDequeue struct {
headTail uint64
vals []eface
}需要说明下:poolChainElt组成的链表结构和我们常见的链表方向相反,从head -> tail的方向是prev,反之是next;poolDequeue 是一个环形链表,headTail字段保存首尾地址,其中高32位表示head,低32位表示tail.
poolDequeue.popHead
func (d *poolDequeue) popHead() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if tail == head {
return nil, false
}
head--
ptrs2 := d.pack(head, tail)
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
slot = &d.vals[head&uint32(len(d.vals)-1)]
break
}
}
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
*slot = eface{}
return val, true
}- 看到
if tail == head,如果首位地址相同说明链表整体为空,证明poolDequeue确实是环形链表; head--后pack(head, tail)得到新的地址ptrs2,如果ptrs == ptrs2,修改headTail地址;- 把slot转成interface{}类型的value;
getSlow
如果从shared的popHead中没拿到可服用的对象,需要通过getSlow来获取
func (p *Pool) getSlow(pid int) interface{} {
size := atomic.LoadUintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
// 遍历locals,从其他P上的尾部窃取
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
// 尝试从victim指向的poolLocal中,按照先private -> shared的顺序获取
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}通过遍历locals获取对象,使用到victim字段指向的[]poolLocal。这里其实引用了一种叫做Victim Cache的机制,具体解释详见这里。
poolChain.popTail
func (c *poolChain) popTail() (interface{}, bool) {
d := loadPoolChainElt(&c.tail)
if d == nil {
return nil, false
}
for {
d2 := loadPoolChainElt(&d.next)
if val, ok := d.popTail(); ok {
return val, ok
}
if d2 == nil {
return nil, false
}
if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {
storePoolChainElt(&d2.prev, nil)
}
d = d2
}
}d2是d的next节点,d已经为链表尾部了,这里也应证了我们刚才说到的poolChain链表的首尾方向和正常的链表是相反的(至于为啥要这么设计,我也是比较懵逼)。如果d2为空证明已经到了链表的头部,所以直接返回;- 从尾部节点get成功时直接返回,已经返回的这个位置,等待着下次get遍历时再删除。由于是从其他的P上窃取,可能发生同时多个协程获取对象,需要保证并发安全;
- 为什么
popHead不去删除链表节点,两个原因吧。第一个,popHead只有当前协程在自己的P上操作,popTail是窃取,如果在popHead中操作,也需要原子操作,作者应该是希望把get阶段的开销降到最低;第二个,因为poolChain结构本身是链表,无论在哪一步做结果都是一样,不如统一放在尾部获取时删除。
poolDequeue.popTail
func (d *poolDequeue) popTail() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if tail == head {
return nil, false
}
ptrs2 := d.pack(head, tail+1)
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
slot = &d.vals[tail&uint32(len(d.vals)-1)]
break
}
}
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
slot.val = nil
atomic.StorePointer(&slot.typ, nil)
return val, true
}和poolDequeue.popHead方法逻辑基本差不多,由于popTail存在多个协程同时遍历,需要通过CAS获取,最后设置slot为空。
Put
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
if race.Enabled {
if fastrand()%4 == 0 {
// Randomly drop x on floor.
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
l, _ := p.pin()
if l.private == nil {
l.private = x
x = nil
}
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
}
}put方法相关逻辑和get很像,先设置poolLocal的private,如果private已有,通过shared.pushHead写入。
poolChain.pushHead
func (c *poolChain) pushHead(val interface{}) {
d := c.head
if d == nil {
// 初始化环,数量为2的幂
const initSize = 8
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
storePoolChainElt(&c.tail, d)
}
if d.pushHead(val) {
return
}
// 如果环已满,按照2倍大小创建新的ring。注意这里有最大数量限制
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// Can't make it any bigger.
newSize = dequeueLimit
}
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(&d.next, d2)
d2.pushHead(val)
}如果节点是空,则创建一个新的poolChainElt对象作为头节点,然后调用pushHead放入到环状队列中.如果放置失败,那么创建一个2倍大小且不超过dequeueLimit(2的30次方)的poolChainElt节点。所有的vals长度必须为2的整数幂。
func (d *poolDequeue) pushHead(val interface{}) bool {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head {
return false
}
slot := &d.vals[head&uint32(len(d.vals)-1)]
typ := atomic.LoadPointer(&slot.typ)
if typ != nil {
return false
}
if val == nil {
val = dequeueNil(nil)
}
*(*interface{})(unsafe.Pointer(slot)) = val
atomic.AddUint64(&d.headTail, 1<<dequeueBits)
return true
}首先判断ring是否大小已满,然后找到head位置对应的slot判断typ是否为空,因为popTail是先设置 val,再将 typ 设置为 nil,有冲突会直接返回。
结论:
整个对象池通过几个主要的结构体构成,它们之间关系如下:

poolCleanup
注册了全局清理的func,在每次gc开始时运行。既然每次gc都会清理pool内对象,那么对象复用的优势在哪里呢? poolCleanup在每次gc时,会将allPools里的对象写入oldPools对象后再清除自身对象。那么就是说,如果申请的对象,会经过两次gc后,才会被彻底回收。p.local会先设置为p.victim,是不是有点类似新生代、老生代的感觉。
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
func poolCleanup() {
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}可以看出,在gc发生不频繁的场景,sync.Pool对象复用就可以减少内存的频繁申请和回收。





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。