
In the real-time message queue implemented by the Go language, NSQ can rank first in popularity.
The NSQ message middleware is simple and easy to use, and its design goal is to provide a powerful infrastructure for running in a distributed environment and for decentralized services. It has a distributed, decentralized topological structure, which has the characteristics of no single point of failure, fault tolerance, high availability, and reliable delivery of messages.
NSQ has captured the hearts of many gophers with its distributed architecture and the ability to process hundreds of millions of messages. Our company is no exception. Many businesses rely on NSQ for news push. Today I want to talk to you about NSQ monitoring.
Why deploy monitoring?
Everyone should be aware of the importance of monitoring. Services without monitoring are "blind people riding blind horses and facing deep pools in the middle of the night". This may be a little abstract. Let me share with you a real case.
I still remember that day, I was eating hot pot and singing. I didn't mention how beautiful it was. Suddenly my phone rang. I opened it and found that some customers reported that the CDN did not take effect after the refresh was successful.
It’s impossible to continue eating hot pot happily. I picked up the computer and the operation was fierce, but the results were unreliable: I checked the logs of related services on the system call link, but the URL that the customer needed to refresh was not in the log. Find clues to the task. Where is the problem?

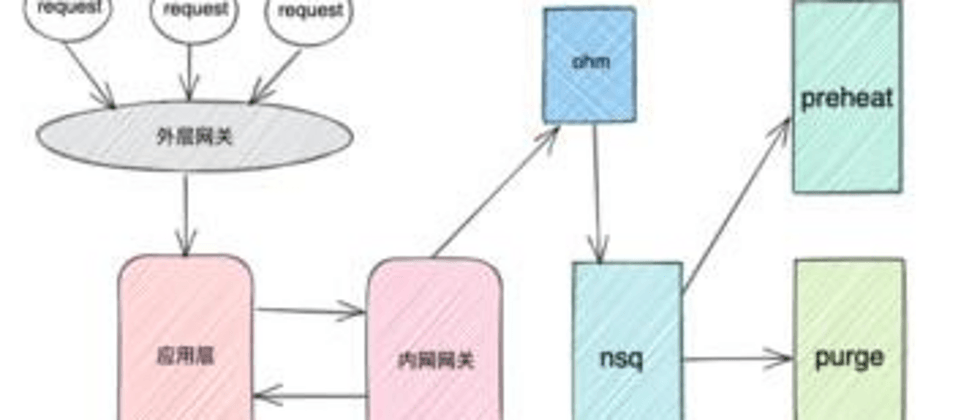
The service call diagram involved in this business is shown in the figure above. Because of the urgency of customer needs, I also took my eyes back from the boiling hot pot and thought about the service link diagram:
- As shown in the figure, the user successfully submitted the refresh request, indicating that the request flow was transferred to the ohm service layer, and ohm successfully processed the request.
- The ohm service is a gateway for refreshing and warming up related services, and it records the ERROR level log. No relevant record of the request was found in ohm's log, indicating that ohm's push to the downstream NSQ was successful.
- The corresponding consumers of NSQ are purge and preheat components. Purge is responsible for performing refresh actions. The log it records is INFO level, and every refreshed URL will be recorded in the log. But why can't I find relevant logs in purge?
I got stuck here just now. The crux of the problem lies in the circumstances under which the corresponding log cannot be found in the purge service. I roughly enumerated the following situations:
- Service changes. The purge service may cause an exception if there is a bug in the code that has been updated recently. But I quickly ruled out this because in the release record, no one has moved this service in recent months.
- NSQ is broken. This is even more unreliable. NSQ is deployed in a cluster, and a single point of failure can be avoided. If there is a global failure, I am afraid that the company group has now blown up.
- NSQ did not send the news. But NSQ is a real-time message queue, and the message delivery should be fast, and the client's refresh operation was a few hours ago.
Is it because the NSQ news is piled up and the news is not delivered in time? I haven't found such problems in the test environment before, because the magnitude of the test is far from enough compared with the online environment... Thinking of this, it feels a bit daunting. Log in to the NSQ console to see the corresponding topic, and sure enough, the problem occurred here. There have been hundreds of millions of undelivered messages on NSQ!
Once the problem is located, it is a normal operation to solve the problem for the customer first through internal tools, and it will not be expanded here.
Monitoring deployment landing
The work order was processed, and I was relieved, but the matter did not come to an end. This failure can be regarded as a wake-up call: you can't think that the NSQ performance is good and that the news will not accumulate, the necessary monitoring alarms must be arranged.
Because of our existing infrastructure, I decided to use Prometheus to monitor NSQ services. (Prometheus related background knowledge will not be popularized here, please leave a message if you want to see it.)
Prometheus collects data from third-party services through exporter, which means that NSQ must configure an exporter to access Prometheus.
Prometheus's official document [ https://prometheus.io/docs/instrumenting/exporters/] exporter, I followed the link and found the official recommended NSQ exporter[ https://github.com/lovoo /nsq_exporter]. NSQ exporter This project has been in disrepair for many years, and the most recent submission was 4 years ago.

So, I took this project locally and made some simple modifications to make it support go mod. (PR is here [ https://github.com/lovoo/nsq_exporter/pull/29])
After the NSQ exporter is deployed, the next question is which indicators need to be monitored?
Refer to the official website [ https://nsq.io/components/nsqadmin.html] I think these indicators need to be focused on:
- Depth: The current NSQ accumulated news. NSQ only saves 8000 messages in memory by default, and the excess messages will be persisted to disk.
- Requeued: The number of times the message was requeueed.
- Timed Out: Processing timed out messages.
Prometheus recommends configuring Grafana to view the changes in indicators more intuitively. The general effect of my configuration is as follows:

The timeout message corresponds to the Timed Out indicator
- The accumulation of messages corresponds to the Depth indicator
- The load is generated according to the formula sum(irate(NSQ_topic_message_count{}[5m])).
- The detection service is to detect whether the NSQ exporter service is normal. Because this service is often pressured by NSQ, the exporter's own service is unavailable.
Since NSQ has configured the monitoring service, we can quickly perceive the current status of NSQ and follow up manually after the alarm is issued. The stability of related businesses has been significantly improved, and the number of work orders caused by such problems has decreased; in addition, the relevant data collected by monitoring allows us to have a clearer thinking and direction in the next performance optimization work.
Recommended reading
server comes standard with SSH protocol, how much do you know?






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。