
在 Go 语言实现的实时消息队列中, NSQ 的热度可以排第一。
NSQ 这款消息中间件简单易用,其设计目标是为在分布式环境下运行,为去中心化服务提供一个强大的基础架构。它具有分布式、去中心化的拓扑结构,该结构具有无单点故障、故障容错、高可用性以及能够保证消息的可靠传递的特征。
NSQ 以分布式架构, 能够处理数亿级别的消息能力俘获了众多 gopher 的心。 我司也不例外,较多的业务都依赖 NSQ 做消息推送。今天我想和大家唠一唠关于 NSQ 监控的问题。
为什么要部署监控?
监控的重要性大家应该都清楚。没有监控的服务就是 “盲人骑瞎马,夜半临深池”。 这样讲可能有些抽象,我来给大家分享一个亲历的真实案例吧。
还记得那天,我正吃着火锅唱着歌,心里甭提有多美了,突然手机响了,打开一看,发现有客户反馈 CDN 刷新成功后未生效的问题。
火锅是不可能继续愉快地吃了,我抱起电脑一顿操作猛如虎,可惜结果不靠谱: 我查了系统调用链路上相关服务的日志,但是客户需要刷新的 URL 却没在日志中查到任务蛛丝马迹。那问题出在哪呢?

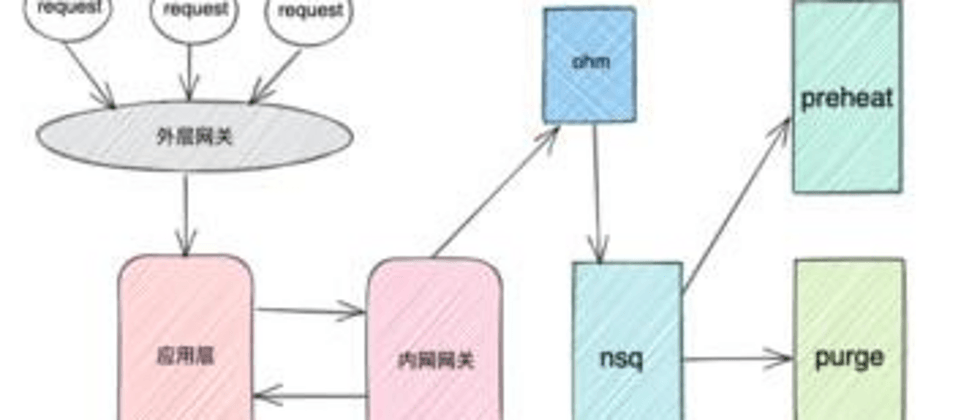
这块业务涉及到的服务调用示意图如上图所示。因为客户需求的紧急,我也把视线从沸腾的火锅收了回来,对着服务链路图沉思起来:
- 如图所示,用户成功提交了刷新请求说明请求流转到了 ohm 服务层,并且 ohm 成功处理了这个请求。
- ohm 服务是刷新预热相关业务的 gateway,记录的是 ERROR 级的 log。没有在 ohm 的日志中查到 该请求的相关的记录,表明 ohm 向下游的 NSQ 推送消息的动作是成功的。
- NSQ 对应的消费者是 purge 和 preheat 组件。purge 负责执行刷新动作,它记录的日志是 INFO 级,每一条刷新的 URL 它都会记录到日志中。 但是为什么在 purge 中却查不到相关日志?
刚才我就卡在了这里。问题的症结在于哪些情况下会在 purge 服务中查不到对应的日志。我大致列举了如下几种情况:
- 服务变更。purge 服务如果最近更新的代码如果有 Bug 可能导致了异常。但是我很快排除了这点,因为发布记录中,这个服务最近几个月都没人动过。
- NSQ 坏了。这个更不靠谱,NSQ 是集群部署的,单点故障可以避免,全局故障的话恐怕公司群现在已经炸翻了天。
- NSQ 没把消息发过来。但是 NSQ 是实时消息队列,消息投递应该很快,而且客户的刷新操作是在几个小时前了。
会不会因为 NSQ 消息堆积了,才没及时把消息投递过来呢?之前在测试环境没有发现此类问题,因为测试的量级与线上环境相比远远不够 ... 想到这,有点茅塞顿开的感觉。登录 NSQ 的控制台看对应的 Topic,果然问题出现在这,NSQ 上未投递的消息已经堆积了几亿条!
问题定位了,后续先通过内部工具先替客户解决问题就属于常规操作了,这里就不展开了。
监控部署落地
工单处理完了,我松了一口气,但是事情并没有告一段落。这个故障算是敲响了警钟:不能觉得 NSQ 性能不错就认为消息不会堆积了,必要的监控报警还是得安排上。
因为我司已经存在的基础设施,所以我决定使用 Prometheus 来监控 NSQ 服务。(Prometheus 的相关背景知识就不在这里科普了, 想看的请留言。)
Prometheus 通过 exporter 去采集第三方服务的数据,也就是说 NSQ 必须配置一个 exporter 才能接入 Prometheus。
Prometheus 的官方文档[https://prometheus.io/docs/in... exporter 有推荐,我顺着链接找到了官方推荐的 NSQ exporter[https://github.com/lovoo/nsq_... exporter 这个项目年久失修,最近的一次提交已经在 4 年前。

于是,我把这个项目拿到了本地,做了一些简单的改造, 使它支持 go mod。(PR 在这里[https://github.com/lovoo/nsq_...
NSQ exporter 部署完成后,接下来的问题是哪些指标需要监控?
参考官网[https://nsq.io/components/nsq...
- Depth:当前 NSQ 堆积的消息。NSQ 在内存中默认只保存 8000 消息,超过的消息会持久化到磁盘中。
- Requeued:消息 requeue 的次数。
- Timed Out:处理超时的消息。
Prometheus 建议配置 Grafana 更加直观地查看指标的变动情况,我配置大体的效果如下:

超时消息对应着 Timed Out 指标
- 堆积消息对应着 Depth 指标
- 负载是根据公式 sum(irate(NSQ_topic_message_count{}[5m])) 生成的。
- 探测服务是探测 NSQ exporter 服务是否正常。 因为该服务经常会因为 NSQ 压力过来导致 exporter 自身服务不可用。
自从 NSQ 配置监控服务后,我们能迅速感知 NSQ 当前状况,在报警发出后及时人工处理跟进。相关业务的稳定性有明显提升,此类问题引起的工单变少了;此外监控收集到的相关数据,让我们在接下来的性能优化工作中的思路更加清晰,方向更加明显。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。