

1. Background
Some businesses in the Internet field of vivo chose the TARS microservice framework based on many comprehensive considerations in the practice of microservices.
The official description is: TARS is a microservice framework that supports multi-language, embedded service management functions, and can work well with Devops. On the basis of open source, we have done a lot of things to adapt to the internal system, such as building a release system with CICD, and getting through the single sign-on system, but this is not the focus of our introduction this time. Here I want to focus on the dynamic load balancing algorithm we implemented in addition to the existing load balancing algorithm.
Second, what is load balancing
Wikipedia is defined as follows: Load balancing is an electronic computer technology used to distribute load among multiple computers (computer clusters), network connections, CPUs, disk drives, or other resources to optimize resource usage, The purpose of maximizing throughput, minimizing response time, and avoiding overload. Using multiple server components with load balancing instead of a single component can improve reliability through redundancy. Load balancing services are usually completed by dedicated software and hardware. The main function is to reasonably allocate a large number of operations to multiple operation units for execution, which is used to solve the problems of high concurrency and high availability in the Internet architecture.
This passage is easy to understand, and is essentially a way to solve the problem of traffic distribution when distributed services respond to a large number of concurrent requests.
3. Which load balancing algorithms does TARS support?
TARS supports three load balancing algorithms, polling-based load balancing algorithms, polling load balancing algorithms based on weight distribution, and consistent hash load balancing algorithms. The function entry is selectAdapterProxy, and the code is in the TarsCpp file. Those who are interested can learn more about it from this function.
3.1 Load balancing algorithm based on polling
The implementation of the load balancing algorithm based on polling is very simple. The principle is to form a call list of all available IPs that provide services. When a request arrives, the request is allocated to each machine in the request list one by one in chronological order. If it is allocated to the last node in the last list, the loop will restart from the first node in the list. In this way, the purpose of flow dispersion is achieved, the load of each machine is balanced as much as possible, and the use efficiency of the machine is improved. This algorithm can basically meet a large number of distributed scenarios, which is also the default load balancing algorithm of TARS.
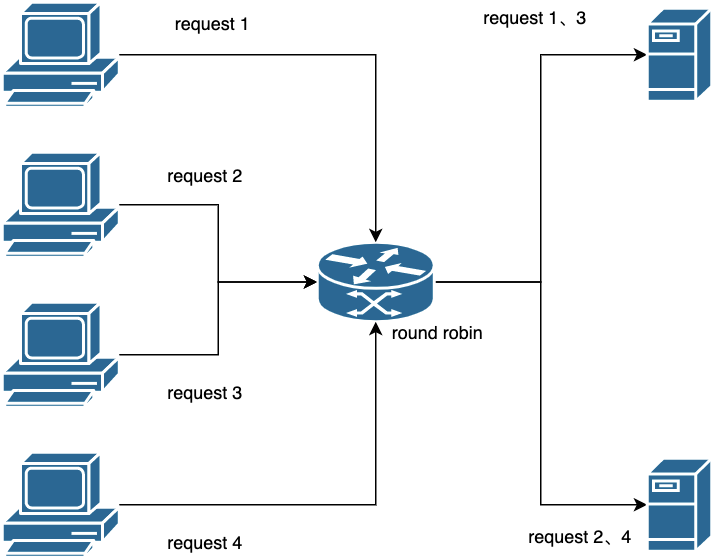
But what if the processing power of each node is different? Although the traffic is evenly divided, because there are nodes with weaker processing capabilities in the middle, these nodes still have the possibility of overload. So we have the following load balancing algorithm.
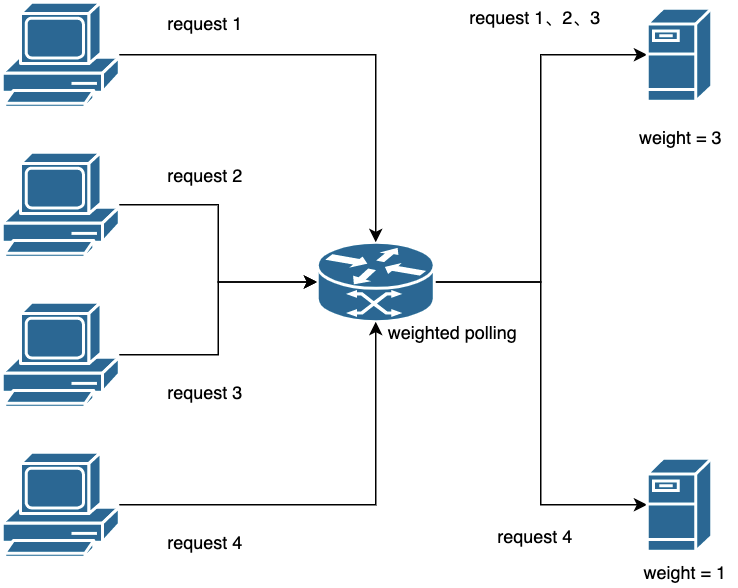
3.2 Polling load balancing algorithm based on weight distribution
As the name implies, weight distribution is to assign a fixed weight to each node, which represents the probability that each node can be allocated to traffic. For example, there are 5 nodes, and the configured weights are 4, 1, 1, 1, 3 respectively. If 100 requests come, the corresponding allocated traffic is also 40, 10, 10, 10, and 30 respectively. In this way, the client's request is allocated according to the configured weight. There is a detail that needs to be paid attention to. It must be smooth when implementing weighted polling. That is to say, if there are 10 requests, the first 4 times cannot all fall on the first node.
There are many smooth weighted polling algorithms in the industry, and interested readers can search and understand by themselves.
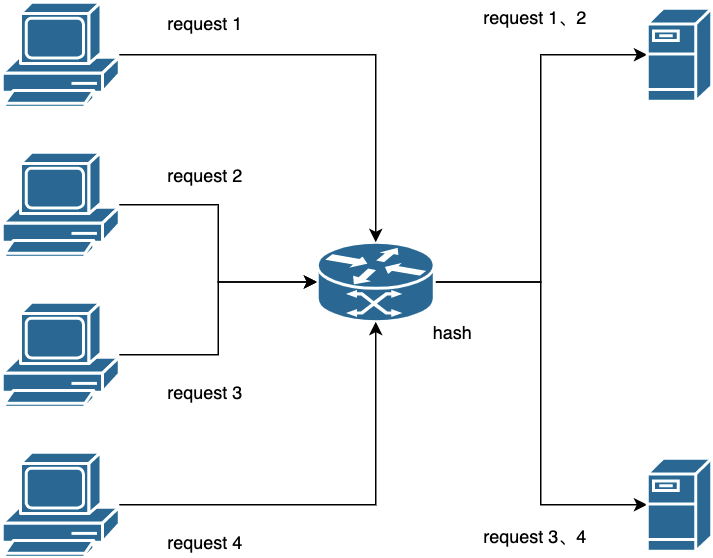
3.3 Consistent Hash
Many times in some business scenarios where there is a cache, in addition to the need for even distribution of traffic, we also have a need for the same client request to fall on the same node as much as possible.
Suppose there is a scenario where a business has 10 million users, and each user has an identification id and a set of user information. There is a one-to-one correspondence between user identification id and user information. This mapping relationship exists in the DB, and all other modules need to query this mapping relationship and obtain some necessary user field information from it. In the scene of large concurrency, it is definitely impossible to directly request the DB system, so we naturally thought of using the cache solution to solve it. Does each node need to store the full amount of user information? Although it is possible, it is not the best solution. What if the number of users rises from 10 million to 100 million? Obviously, this solution becomes stretched with the increase in the scale of users, and bottlenecks will soon appear or even unable to meet the demand. So a consistent hash algorithm is needed to solve this problem. The consistent hash algorithm provides the guarantee that requests fall on the same node as much as possible under the same input.
Why is it as far as possible? Because nodes will fail and go offline, or may be added due to expansion, the consistent hash algorithm can minimize cache reconstruction under such changes. There are two hash algorithms used by TARS, one is to obtain the md5 value of the key and then take the address offset to do an XOR operation, and the other is ketama hash.
4. Why do we need dynamic load balancing?
Most of our current services are still running on virtual machines, so hybrid deployment (multiple services deployed on a node) is a common phenomenon. In the case of mixed deployment, if a service code has a bug that takes up a lot of CPU or memory, then the services that must be deployed with it will be affected.
Then if the above three load balancing algorithms are still used, there will be a problem. The affected machines will still be distributed to the traffic according to the specified rules. Some people may think, can't the weight-based polling load balancing algorithm configure the problematic node to have a low weight and distribute it to a small amount of traffic? It is true, but this method is often not handled in time. What if it happens in the middle of the night? And after the fault is removed, it needs to be manually configured back, which increases the operation and maintenance cost. Therefore, we need a dynamically adjusted load balancing algorithm to automatically adjust the distribution of traffic, as far as possible to ensure the quality of service under this abnormal situation.
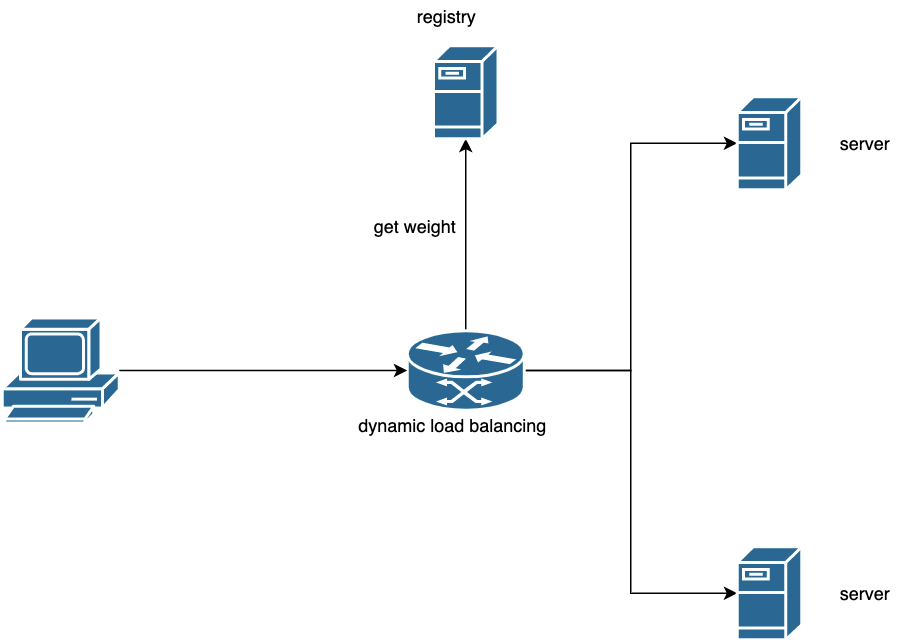
It is not difficult to see from here that the core of the dynamic load balancing function actually only needs to dynamically adjust the weights of different nodes according to the load of the service. This is actually some common practice in the industry, which is to dynamically calculate the weight that each current server should have by periodically obtaining server status information.
Five, dynamic load balancing strategy
Here we also use a method based on various load factors to dynamically calculate the weights of the available nodes, and reuse the TARS static weight node selection algorithm after returning the weights. The load factors we choose are: interface 5-minute average time/interface 5-minute timeout rate/interface 5-minute abnormal rate/CPU load/memory usage rate/network card load. The load factor supports dynamic expansion.
The overall function diagram is as follows:
5.1 Overall interaction sequence diagram
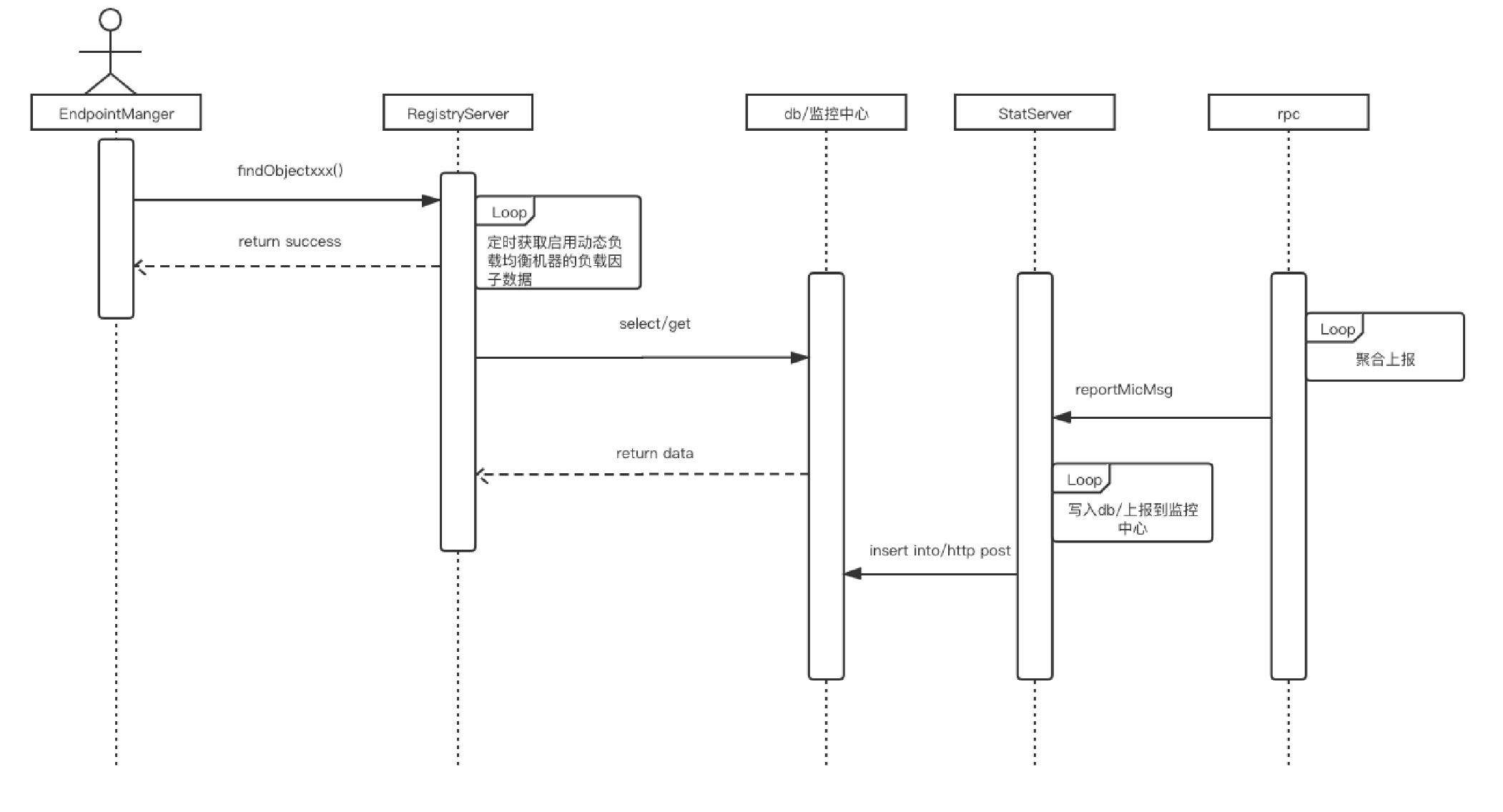
When rpc is called, EndpointManager periodically obtains the set of available nodes. The node is attached with weight information. When a business initiates a call, it selects the corresponding node according to the load balancing algorithm specified by the business party;
RegistrServer regularly obtains timeout rate and average time-consuming information from db/monitoring. Obtain machine load information, such as cpu/memory, from other platforms (such as CMDB). All calculation process threads are asynchronously executed and cached locally;
EndpointManager executes the selection strategy according to the weight obtained. The following figure shows the impact of node weight changes on request traffic distribution:
5.2 Node update and load balancing strategy
All node performance data is updated every 60 seconds, using threads to update regularly;
Calculate the weight value and value range of all nodes and store them in the memory cache;
After the main toner obtains the node weight information, executes the current static weight load balancing algorithm to select the node;
Bottom-line strategy: If all nodes are the same or abnormal, the polling method is used to select nodes by default;
5.3 How to calculate the load
Load calculation method: each load factor sets the weight value and the corresponding importance degree (expressed as a percentage), adjust the settings according to the specific importance degree, and finally calculate the total value after multiplying the weight value calculated according to all load factors by the corresponding percentage. For example, if the time-consuming weight is 10, the time-out rate weight is 20, and the corresponding importance levels are 40% and 60%, respectively, the sum is 10 0.4 + 20 0.6 = 16. The calculation method corresponding to each load factor is as follows (currently we only use the two load factors of average time and timeout rate, which are also the easiest data that can be obtained in the current TARS system):
1. The weight is allocated according to the inverse proportion of the total time consumed by each machine: weight = initial weight * (sum of time consumption-average time consumed by a single machine) / sum of time consumption (the disadvantage is that it is not entirely based on time consumption Ratio distribution flow);
2. Timeout rate weight: timeout rate weight = initial weight-timeout rate initial weight 90%, 90% conversion is because 100% timeout may also be caused by excessive traffic, keep small traffic trial requests;
The corresponding code is implemented as follows:
void LoadBalanceThread::calculateWeight(LoadCache &loadCache)
{
for (auto &loadPair : loadCache)
{
ostringstream log;
const auto ITEM_SIZE(static_cast<int>(loadPair.second.vtBalanceItem.size()));
int aveTime(loadPair.second.aveTimeSum / ITEM_SIZE);
log << "aveTime: " << aveTime << "|"
<< "vtBalanceItem size: " << ITEM_SIZE << "|";
for (auto &loadInfo : loadPair.second.vtBalanceItem)
{
// 按每台机器在总耗时的占比反比例分配权重:权重 = 初始权重 *(耗时总和 - 单台机器平均耗时)/ 耗时总和
TLOGDEBUG("loadPair.second.aveTimeSum: " << loadPair.second.aveTimeSum << endl);
int aveTimeWeight(loadPair.second.aveTimeSum ? (DEFAULT_WEIGHT * ITEM_SIZE * (loadPair.second.aveTimeSum - loadInfo.aveTime) / loadPair.second.aveTimeSum) : 0);
aveTimeWeight = aveTimeWeight <= 0 ? MIN_WEIGHT : aveTimeWeight;
// 超时率权重:超时率权重 = 初始权重 - 超时率 * 初始权重 * 90%,折算90%是因为100%超时时也可能是因为流量过大导致的,保留小流量试探请求
int timeoutRateWeight(loadInfo.succCount ? (DEFAULT_WEIGHT - static_cast<int>(loadInfo.timeoutCount * TIMEOUT_WEIGHT_FACTOR / (loadInfo.succCount
+ loadInfo.timeoutCount))) : (loadInfo.timeoutCount ? MIN_WEIGHT : DEFAULT_WEIGHT));
// 各类权重乘对应比例后相加求和
loadInfo.weight = aveTimeWeight * getProportion(TIME_CONSUMING_WEIGHT_PROPORTION) / WEIGHT_PERCENT_UNIT
+ timeoutRateWeight * getProportion(TIMEOUT_WEIGHT_PROPORTION) / WEIGHT_PERCENT_UNIT ;
log << "aveTimeWeight: " << aveTimeWeight << ", "
<< "timeoutRateWeight: " << timeoutRateWeight << ", "
<< "loadInfo.weight: " << loadInfo.weight << "; ";
}
TLOGDEBUG(log.str() << "|" << endl);
}
}The relevant code is implemented in RegistryServer, the code file is as follows:
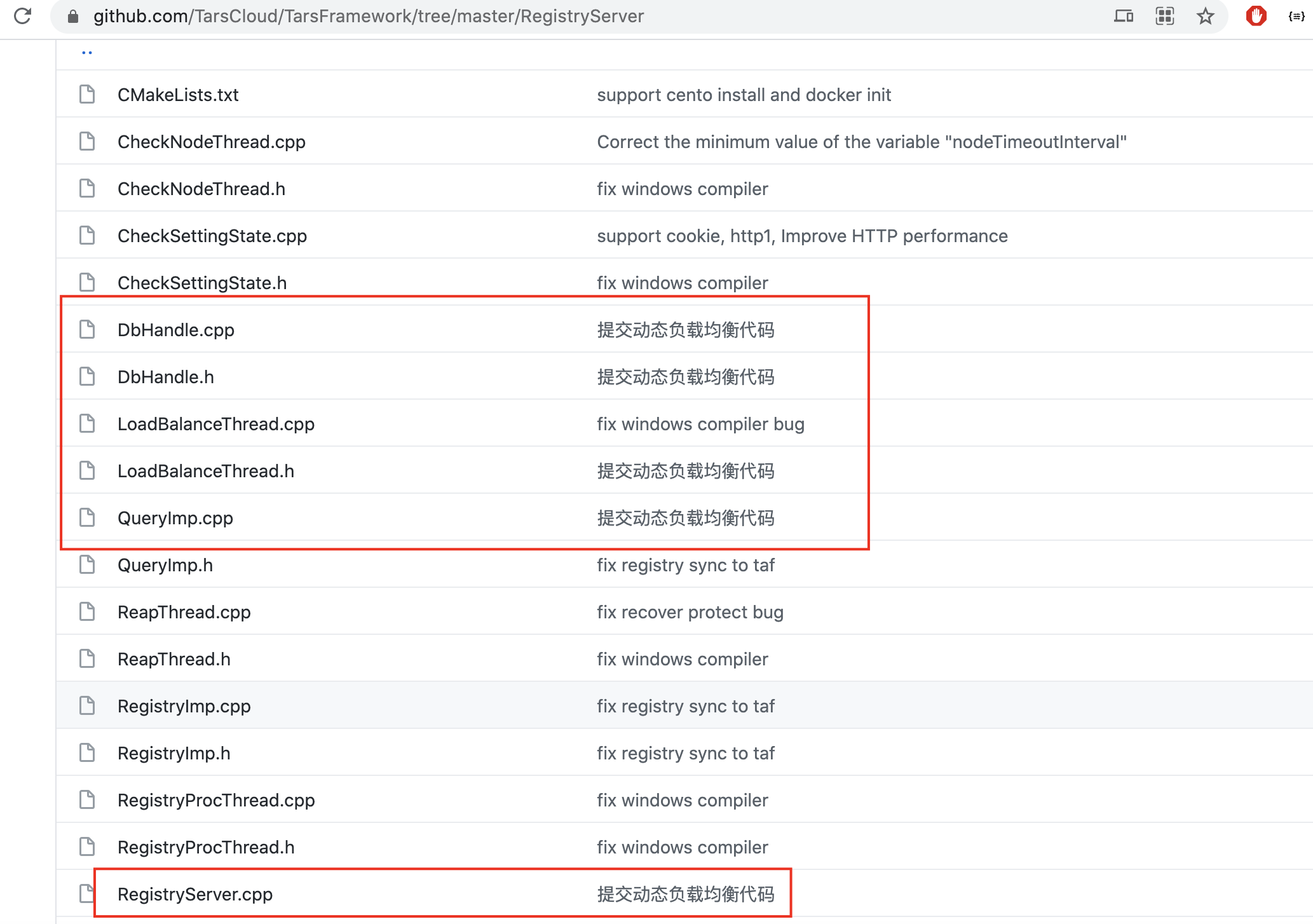
The core implementation is the LoadBalanceThread class, you are welcome to correct me.
5.4 How to use
- Configure the -w -v parameter in the Servant management office to support dynamic load balancing. If it is not configured, it will not be enabled.
As shown below:
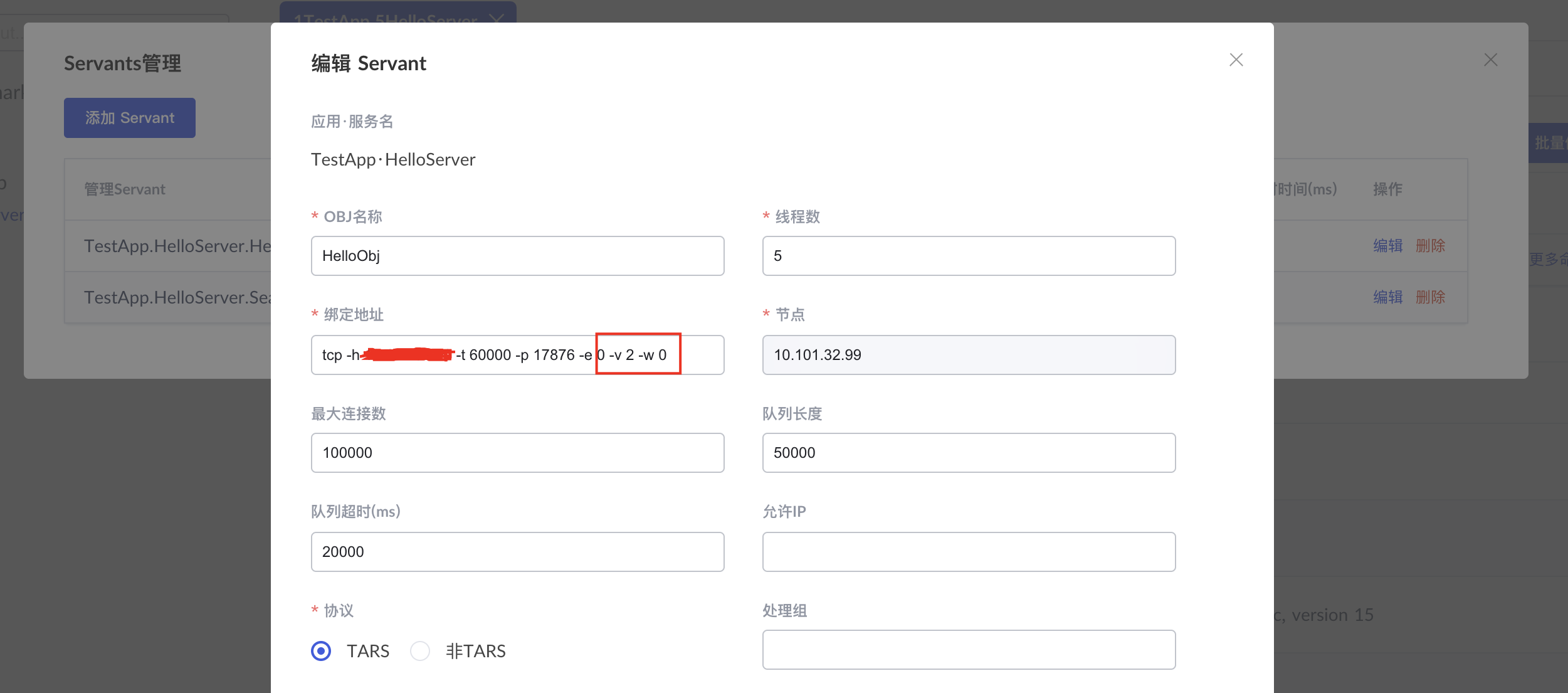
- Note: All nodes need to be enabled to take effect, otherwise the rpc framework finds that different nodes use different load balancing algorithms and forces all nodes to be adjusted to the polling mode.
Six, dynamic load balancing applicable scenarios
If your service is running on a Docker container, you may not need the feature of dynamic load balancing. Directly use Docker's scheduling capabilities to automatically scale services, or directly reduce the granularity of Docker allocation in deployment, so that services can monopolize docker and there is no problem of mutual influence. If the service is deployed in a mixed manner, and the service is likely to be affected by other services, such as a service that directly fills up the cpu, it is recommended to enable this function.
Seven, the next step
In the current implementation, only two factors, the average time-consuming and the overtime rate, are considered, which can reflect the service capability provision to a certain extent, but it is not complete. Therefore, in the future, we will also consider adding cpu usage indicators that can better reflect node load. And, some strategies for adjusting the weight according to the return code at the main adjuster.
Finally, everyone is welcome to discuss and exchange with us, and contribute to TARS open source together.
Author: vivo Internet server team-Yang Minshan




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。