
Based on the experience accumulated in the advertising field for many years, the algorithm team of the Meituan to-store advertising platform has been continuously optimizing and innovating algorithms on challenging problems in the industry such as data deviation. In the previously shared article "KDD Cup 2020 Debiasing Championship Technical Solution and Advertising Business Application" [4], the team shared the solution to the selective deviation and popularity deviation of winning the championship in the KDD Cup competition, and also shared The technical framework of deviation optimization in the advertising business. Based on this technical framework, this article will continue to introduce, focusing on the latest developments in the problem of positional deviation, and introduce in detail the positional deviation CTR model optimization program that the team has achieved significant business results in Meituan advertising. The paper "Deep "Position-wise Interaction Network for CTR Prediction" was also accepted by the top international conference SIGIR 2021.
In recent years, due to the rapid development of artificial intelligence technology, fairness issues have also attracted increasing attention. Similarly, advertising technology also has many fairness problems. Deviations caused by fairness problems will have a greater negative impact on the ecology of the advertising system. Figure 1 shows the feedback loop in the advertising system [1]. The advertising system uses accumulated user interaction feedback data to train the model based on certain assumptions. Of ads interact and accumulate in the data. In this loop, various types of deviations, such as location deviation and popularity deviation, will continue to accumulate in each link, and eventually lead to the continuous deterioration of the ecology of the advertising system, forming a Matthew that "the strong gets stronger, the weak gets weaker" effect.
As deviations have a great impact on the ecology of advertising systems and recommendation systems, research efforts aimed at eliminating deviations are also increasing. For example, the International Information Retrieval Conference SIGIR organized some special conferences focusing on the topic of eliminating bias in 2018 and 2020, and also awarded Best Paper awards to some papers based on bias and fairness[2,3] . One of the tracks of KDD Cup 2020 is also carried out based on the popularity bias in e-commerce recommendations [1].

Based on the experience accumulated in the advertising field for many years, the algorithm team of the Meituan to-store advertising platform has been continuously optimizing and innovating algorithms on challenging problems in the industry such as data deviation. In the previously shared "160c9a890b7fd6 KDD Cup 2020 Debiasing competition champion technical solution and advertising business application " [4], the team shared the solution to the selection bias and popularity bias of winning the KDD Cup competition, and also Shared the technical framework of deviation optimization in advertising business.
Based on this technical framework, this article will continue to introduce, focusing on the latest developments in the problem of positional deviation, and introduce in detail the positional deviation CTR model optimization program that the team has achieved significant business results in Meituan advertising. The paper "Deep "Position-wise Interaction Network for CTR Prediction" was also accepted by the top international conference SIGIR 2021.
1. Background
Based on the advertising business scenarios of Meituan and Dianping, the algorithm team of the Meituan-to-store advertising platform continuously optimizes and innovates the cutting-edge advertising technology. In most advertising business scenarios, the advertising system is divided into four modules, namely trigger strategy, creative optimization, quality estimation, and mechanism design. These modules form an advertising funnel to filter and select high-quality advertisements from a large number of advertisements. Deliver to target users. Among them, the trigger strategy selects a set of candidate advertisements that meet the user's intentions from a large number of advertisements. The creative optimization is responsible for the generation of the image and text of the candidate advertisements. The quality estimation combines the results of the creative optimization to estimate the quality of each candidate advertisement, including the click rate. (CTR) estimation, conversion rate (CVR) estimation, etc., the mechanism ranking combines the advertising quality and advertising bidding to optimize the ranking. In this article, we will also refer to advertising as item.
CTR estimation, as a link of quality estimation, is one of the most core algorithms in calculating advertising. Under the pay-per-click (CPC) billing model, the mechanism design can simply sort advertisements by revenue per thousand impressions (eCPM) to maximize advertising revenue. Because eCPM is proportional to the product of CTR and advertising bid (bid). Therefore, CTR estimates will directly affect the final revenue and user experience of advertising. In order to have higher accuracy of CTR estimation, CTR estimation ranges from the early models that support large-scale sparse features, such as LR[5], FM[6], and FFM[7], to XGBoost[8], LightGBM[9], etc. The combination of tree models, and then to Wide&Deep[10], Deep&Cross[11], DeepFM[12], xDeepFM[13] and other deep learning models that support high-order feature crossover, further evolved to DIN[14], DIEN[15], DSIN [16] and other deep learning models that combine user behavior sequences have always been one of the hot research areas in the industry and academia, and they have been continuously explored and innovated.
Since the training of the CTR prediction model usually uses exposure click data, which is a kind of implicit feedback data, various deviation problems will inevitably occur. Among them, position deviation has attracted much attention because of its great influence on CTR. As shown in Figure 2, the CTR distribution of different positions on the random traffic reflects that users usually tend to click on the ads in the front position, and the CTR will drop rapidly as the exposure position increases. Therefore, by training directly on the exposure click data, the model will inevitably be biased toward the set of advertisements in the front position, causing the problem of position deviation. Figure 2 shows that the CTR distribution of normal traffic is more concentrated on high-position advertisements than random traffic. Through the feedback loop, this problem will continue to amplify and further damage the performance of the model. Therefore, solving the problem of position deviation can not only improve the effectiveness of the advertising system, but also balance the ecology of the advertising system and promote the fairness of the system.

The final real exposure position information of the advertisement is unknown when it is estimated online, which undoubtedly further increases the difficulty of solving the position deviation problem. The existing methods for solving position deviation can be roughly divided into the following two types:
- neural network location feature modeling : This method models the location as a feature in the neural network. Since the real location information is not known during the estimation process, some methods [17-19] put the location information in the network In the Wide part, the real position is used for offline training and a fixed position is used for online estimation. This method is widely used in the industry due to its simplicity and effectiveness. In order to avoid using location information for online estimation, as shown in Figure 3, PAL[20] models the sample’s CTR as ProbSeen multiplied by pCTR, where ProbSeen only uses location feature modeling, while pCTR uses other information to model. Only pCTR is used online as the CTR estimate.

- Inverse Propensity Weighting (IPW) : This method has been extensively studied by academia [21-29]. It assigns different sample weights to samples at different exposure positions during model training. Intuitively, it should have lower received feedback Tendency ad samples (ads with lower exposure positions) are assigned higher weights. Therefore, the difficulty of this method lies in how to determine the sample weights of different locations. A simple method is to use the traffic of randomly displayed advertisements to accurately calculate the position CTR deviation, but it will inevitably damage the user experience. Therefore, many methods are devoted to accurately predict the position deviation on the biased flow.
The above method is usually based on a strong assumption that clicking on the Bernoulli variable $C$ depends on two potential Bernoulli variables E and $R$, as shown in the following formula:

Among them, the left side of the equation refers to the probability that the user $u$ clicks on the $k$th advertisement $i$ in the context $c$. We define the context $c$ as the real-time request information. The first term on the right side of the equation refers to the probability that the position $k$ is viewed, where $[s]$ is usually a subset of the context $c$. Most methods assume that $[s]$ is the empty set, that is, the position The probability of $k$ being viewed is only related to $k$. The second term on the right side of the equation refers to the probability of relevance (for example, the real interest of the user $u$ in the advertisement $i$ in the context $c$). The above methods usually estimate the viewing probability explicitly or implicitly, then use Counterfactual Inference to obtain the correlation probability, and finally use the correlation probability as the estimated value of CTR online. The different processing of location information between training and estimation will inevitably lead to inconsistencies between offline and online, and further lead to sub-optimal model performance.
In addition, existing methods usually assume that the viewing probability depends only on location and some contextual information, and their assumptions are too simple. Different users usually have different browsing habits, some users may tend to browse more items, and some users usually make quick decisions, and the same user will have different location preferences in search intent in different contexts. For example, search for location words such as shopping malls often has unclear intentions, resulting in little difference in CTR between high and low positions. Therefore, the position deviation is related to the user, the context, and may even be related to the advertisement itself. Modeling the relationship between them can better solve the position deviation problem.
Different from the above methods, this paper proposes a multi-position estimation method based on the Deep Position-wise Interaction Network (DPIN) model to effectively and directly model the $ CTR_k^j=p(C=1| u,c,i,k) $
To improve the performance of the model, $CTR_k^j$ is the estimated CTR value of the $j$th advertisement at the $k$th position. The model effectively combines all candidate advertisements and locations to estimate the CTR of each advertisement in each location, achieve consistency between offline and online, and support location, user, context, and location under the constraints of online service performance. Deep non-linear intersection between advertisements. The final order of the advertisement can be determined by maximizing $\sum CTR_k^jbid^j $, where $bid^j$ is the bid of the advertisement. The online mechanism of this article uses a top-down greedy algorithm to get the final advertisement. sequence. The contributions of this article are as follows:
- In this paper, a shallow location combination module with nonlinear crossover is used in DPIN. This module can predict the CTR of candidate advertisements and location combinations in parallel, achieve consistency between offline and online, and greatly improve the performance of the model.
- Different from the previous modeling of user interest only for candidate advertisements, this time it is the first time to model user interest for candidate locations as well. DPIN applies a deep position cross module to effectively learn the position, the deep non-linear cross representation between user interest and context.
- According to the new processing method of position, this paper proposes a new evaluation index PAUC (Position-wise AUC), which is used to measure the model performance of the model in solving the problem of position deviation. In this paper, full experiments have been carried out on the real data set of Meituan Advertising, which verifies that DPIN can achieve good results in both model performance and service performance. At the same time, this article also deployed A/B Test online, verifying that DPIN is significantly improved compared to the highly optimized existing baseline.
2. Deep Position-wise Interaction Network
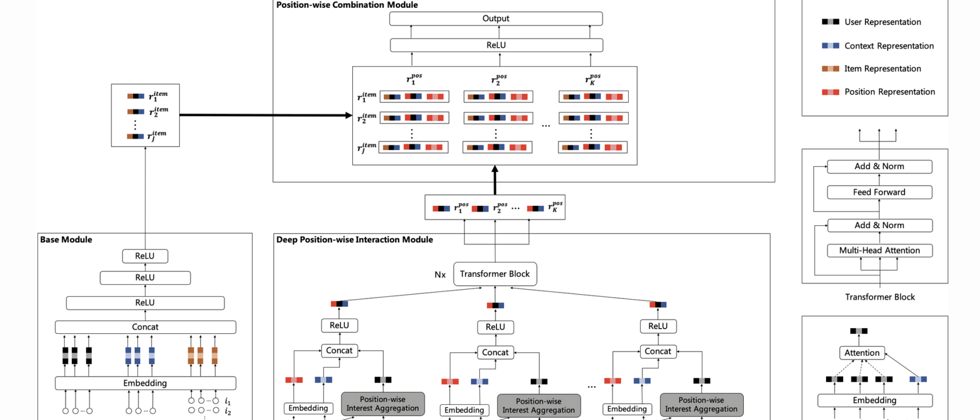
This section mainly introduces the Deep Position-wise Interaction Network (DPIN) model. As shown in Figure 4, the DPIN model consists of three modules, namely the Base Module for processing $J$ candidate advertisements, and the Deep Position-wise Interaction Module (Deep Position-wise Interaction Module) for processing $K$ candidate positions. ) And the Position-wise Combination Module (Position-wise Combination Module) that combines $J$ advertisements and $K$ positions. The number of samples to be estimated is different for different modules. The number of samples estimated by complex modules is small, while the number of simple modules is estimated. A large number of samples are used to improve model performance and guarantee service performance. Through the combination of these three modules, the DPIN model has the ability to estimate the CTR of each advertisement at each location under the constraints of service performance, and learn the deep non-linear cross-representation of location information and other information. These three modules will be introduced in detail below.

2.1 Base Module
Similar to most deep learning CTR models [10-16], this paper adopts the structure of Embedding and MLP (multilayer perceptron) as the basic modules. For a specific request, the basic module takes the user, context, and $J$ candidate advertisements as input, and expresses each feature by Embedding. Splicing Embedding means inputting a multi-layer MLP, using ReLU as the activation function, and finally getting each The representation of the ad under the request. The representation of the $j$th advertisement $r_j^{item}$ can be obtained by the following formula:

Where $\{u_1,...,u_m\}$, $\{c_1,...,c_m\}$, $\{i_1^j,...,i_o^j\}$ are the current users respectively The feature set, the current context feature set, and the feature set of the $j$th advertisement, $E(\cdot)\in \mathbb{R} $ is the Embedding mapping.
2.2 Deep Position-wise Interaction Module
In most business scenarios, the basic modules are usually highly optimized, containing a large number of features and even user sequence information, and their purpose is to capture the user's interest in different advertisements in this context. Therefore, the reasoning time complexity of the basic module is usually relatively large, and it is unacceptable to directly add location features to the basic module to estimate the CTR of all advertisements in all positions. Therefore, this article proposes a deep location cross module parallel to the basic module, which is different from the basic module for interest modeling for advertisements. This module performs interest modeling for location and learns the depth of each location, context, and user interest. Linear cross representation.
In the deep position cross module, we extract the user's behavior sequence at each position and use it for the user interest aggregation at each position, which can eliminate the position deviation in the entire user behavior sequence. Next, we use a non-linear fully connected layer to learn the non-linear cross representation of location, context, and user interest. Finally, in order to aggregate the user's sequence information at different locations to ensure that the information is not lost, we use Transformer [30] to make the behavior sequence representations at different locations interactive.
Position-wise Interest Aggregation. Let us set $B_k=\{b_1^k,b_2^k,...,b_L^k \}$ to be the user's historical behavior sequence at the $k$th position, where $b_l^k=[v_l^k , c_l^k]$ is the historical behavior record of the user at the position $k$, $v_l$ is the item feature set of the click, and $c_l^k$ is the context when the behavior occurs (including Search keywords, request geographic location, days of the week, hours of the day, etc.), Embedding of the behavior record indicates that $\mathbf{b_l^k}$ can be obtained by the following formula:

Where $\{v_1^{k_l},v_o^{k_l}\}$, $\{c_1^{k_l},c_n^{k_l}\}$ are respectively $v_l^k$ and $c_l^k$ Feature set, $dif^{kl}$ is the time difference between the behavior and the current context.
The aggregation of the $k$th position behavior sequence indicates that $\mathbf{b_k}$ can be obtained through the attention mechanism, as shown in the following formula:

It introduces the current context $\mathbf{c}$ to calculate the attention weight, and can give more weight to the behaviors that are more relevant to the context.
Position-wise Non-linear Interaction: We use a non-linear fully connected layer to learn the non-linear cross representation of position, context and user interest, as shown in the following formula:

Among them, $\mathbf{W_v},\mathbf{b_v},$ maps the spliced vector to the $d_{model}$ dimension.
Transformer Block: if $V_k$ is directly used as the non-linear cross representation of the $k$th position, then the user's behavior sequence information in other positions will be lost. Therefore, we use Transformer to learn the interaction of interests in different locations. Let $\mathbf{Q}=\mathbf{K}=\mathbf{V}=Concat(\mathbf{v_1},\mathbf{v_2},...,\mathbf{v_K})$ be the input of Transformer, The multi-head self-attention structure of Tranformer can be expressed by the following formula:

Among them, $d_k=d_{model}/h$ is the dimension of each head. Because $\mathbf{v_k}$ already contains location information, we don't need the location code in Transformer. Similarly, we also use the Position-wise Feed-forward Network, Residual Connections, and Layer Normalization in Transformer. N Transformer Blocks will be used to deepen the network.
Finally, the depth position cross module will produce a deep nonlinear cross representation of each position, where the $k$th position is represented as $r_k^{pos}$.
2.3 Position-wise Combination Module
The purpose of the location combination module is to combine $J$ ads and $K$ locations to estimate the CTR of each ad at each location. We use a non-linear fully connected layer to learn advertising, location, context, and The non-linear representation of the user, the CTR of the $j$th advertisement at the $k$th position can be obtained by the following formula:

It includes a non-linear connection layer and an output layer, which is the embedding representation of position k in $E(k)$, and $\sigma(\cdot)$ is the sigmoid function.
The entire model can be trained and learned by batch gradient descent using the real position, and we use cross entropy as our loss function.
3. Experiment
In this section, we evaluate the model performance and service performance of DPIN, and we will describe the experimental setup and experimental results in detail.
3.1 Experimental setup
data set: We use the Meituan search keyword advertising data set to train and evaluate our CTR model. The amount of training data reaches hundreds of millions, and the amount of test data is about 10 million. The test set is divided into two parts, one is the regular traffic logs collected online, and the other is the online Top-k random exploration traffic logs. The Top-k random exploratory traffic log is more suitable for evaluating the position deviation problem, because it greatly weakens the influence of the correlation recommendation on the position deviation.
evaluation indicators: We use AUC (Area Under ROC) as one of our evaluation indicators. In order to better evaluate the position deviation problem, we propose PAUC (Position-wise AUC) as our other evaluation index, which is calculated by the following formula:

Among them, $\#impression_k$ is the number of exposures at the $k$th position, and $PAUC@k$ is the AUC of the exposure data at the $k$th position. The PAUC indicator measures the quality of the relevance ranking at each location, ignoring the impact of positional deviation on the ranking quality.
method of comparison. In order to fairly and fully compare the effects of different models, the model inputs used in all our experiments use the same amount and deeply combine the characteristics of Meituan's business. The same modules in different models use the same parameters, and the baseline DIN for comparison [14] The model has been highly optimized. The following is a specific experiment for comparison:
- DIN: This model does not use location information during training and estimation.
- DIN+PosInWide: This method models location features in the Wide part of the network, and uses the first location as the default value of location features to evaluate.
- DIN+PAL: This method uses the PAL framework to model location information.
- DIN+ActualPosInWide: This method models location features in the Wide part of the network, and uses real location features to evaluate.
- DIN+Combination: This method adds a position combination module on the basis of DIN, and uses real position features to evaluate.
- DPIN-Transformer: This method removes the Transformer structure from the DPIN model we proposed to verify the role of the Transformer.
- DPIN: This is our DPIN model.
- DPIN+ItemAction: We add a deep position cross module in front of the MLP layer of the basic module of DPIN, and introduce candidate advertisement information in position interest aggregation and position nonlinear crossover. This experiment is the theoretical upper bound of the performance of our method model. However, the service performance is unacceptable.
3.2 Offline evaluation

Table 1 shows the offline experimental evaluation results of our comparison method on regular traffic and random traffic. The values are the differences in the effects of each model relative to the DIN model. We first analyze the differences between different methods on regular traffic. Compared with DIN, the DIN+PosInWide and DIN+PAL models have decreased in AUC index, but improved in PAUC, which shows that both methods can effectively alleviate position deviation, but will cause offline and Inconsistency between the lines.
DIN+AcutalPosInWide solves the inconsistency problem by introducing the actual position in the evaluation process. This can be achieved by the position combination module. However, modeling the position in the wide part will cause the position feature to be only a deviation and cannot improve the PAUC index, although it can be more accurate Estimate the CTR at each position, but do not better learn the inherent positional deviation in the data.
DIN+Combination has achieved 1.52% AUC gain and 0.82% PAUC gain by introducing the position combination module into DIN, which achieves offline and online consistency and further alleviates the position deviation. This result shows the position deviation It is not independent of information such as context and user, and there will be different position deviations in different users and contexts. Furthermore, DPIN models the deep non-linear cross relationship of position, context, and users, and also eliminates the position deviation in the user behavior sequence. Compared with DIN+Combination, it has achieved 0.24% AUC gain and 0.44% PAUC gain.
The effect of DPIN-Transformer shows that losing user interest in other locations will affect the performance of the model, because it will lose most of the user interest information. Comparing DPIN and DPIN+ItemAction, we find that the performance of DPIN model is close to this brute force method, indicating that the DPIN model approaches the theoretical upper bound of our method. Finally, compared to our online baseline model DIN+PosInWide, DPIN achieved an AUC gain of 2.98% and a PAUC gain of 1.07%, which is a great AUC and PAUC improvement in our business scenario.
In order to ensure that our method can learn the positional bias rather than simply overfitting the selective bias of the system, we further evaluate our method on random flow. The results in Table 1 show that the differences between the different methods on regular traffic and random traffic are consistent, which shows that even if the recommendation results of the system have huge differences, the model can still effectively learn in different users and contexts. The position deviation in the model, the position deviation learned by the model is little affected by the system recommendation list, which also shows that our model can be generalized to the flow of other recommended methods without being affected by the system selectivity deviation.
3.3 Service performance

We retrieved some requests with different numbers of candidate advertisements from the data set to evaluate the service performance under different numbers of candidate advertisements. As shown in Figure 5, since the delay of the user sequence operation accounts for a large proportion of the service delay, compared with the DIN model, the service delay of the location combination module is negligible. The service delay of DPIN increases slowly with the increase in the number of advertisements. This is because compared to DIN, DPIN moves the user sequence from the basic module to the deep position cross module, and the service performance of the deep position cross module has nothing to do with the number of advertisements. Compared with the DIPIN+ItemAction method, DPIN has a great improvement in service performance, and the damage to the model performance is small, which shows that the method we propose is both efficient and effective.
3.4 Online evaluation
We deployed A/B testing online, and stable results showed that compared with the baseline, DPIN increased by 2.25% in CTR and 2.15% in RPM (revenue per thousand impressions). Today, DPIN has been deployed online and served major traffic, contributing to a significant increase in business revenue.
4. Summary and Outlook
In this article, we propose a novel Deep Position-wise Interaction Network model (Deep Position-wise Interaction Network) to alleviate the problem of position bias. This model effectively combines all candidate advertisements and positions to estimate the position of each advertisement in each position. The click-through rate achieves the consistency between offline and online. The model designs a deep non-linear intersection between location, context, and users, and can learn location deviations in different users and different contexts. In order to evaluate the problem of location bias, we propose a new evaluation index PAUC. Offline experiments show that the effect and efficiency of the proposed DPIN are better than existing methods. At present, DPIN has been deployed to the Meituan search keyword advertising system and serves the main traffic.
It is worth mentioning that our parallel combination idea can be used not only in the combination of advertising and location, but also in the common combination ordering problem in the advertising field such as the combination of advertising and creativity. In the future, we will continue to practice our methods on these issues, and further design a more complete network structure to solve similar combinatorial sequencing problems. We will also conduct more explorations in the field of deviation, solve more problems, and further maintain the ecological balance of the advertising system.
About the Author
Jianqiang, Hu Ke, Qingtao, Mingjian, Qi Yi, Cheng Jia, Lei Jun, etc., all come from Meituan Advertising Platform Technology Department.
references
- [1] Chen, Jiawei, et al. "Bias and Debias in Recommender System: A Survey and Future Directions." arXiv preprint arXiv:2010.03240 (2020).
- [2] Cañamares, Rocío, and Pablo Castells. "Should I follow the crowd? A probabilistic analysis of the effectiveness of popularity in recommender systems." The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.
- [3] Morik, Marco, et al. "Controlling fairness and bias in dynamic learning-to-rank." Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2020.
- [4] "KDD Cup 2020 Debiasing Championship Technical Plan and Practice in the US Mission" .
- [5] Richardson, Matthew, Ewa Dominowska, and Robert Ragno. "Predicting clicks: estimating the click-through rate for new ads." Proceedings of the 16th international conference on World Wide Web. 2007.
- [6] Rendle, Steffen. "Factorization machines." 2010 IEEE International Conference on Data Mining. IEEE, 2010.
- [7] Juan, Yuchin, et al. "Field-aware factorization machines for CTR prediction." Proceedings of the 10th ACM conference on recommender systems. 2016.
- [8] Chen, Tianqi, and Carlos Guestrin. "Xgboost: A scalable tree boosting system." Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016.
- [9] Ke, Guolin, et al. "Lightgbm: A highly efficient gradient boosting decision tree." Advances in neural information processing systems 30 (2017): 3146-3154.
- [10] Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st workshop on deep learning for recommender systems. 2016.
- [11] Wang, Ruoxi, et al. "Deep & cross network for ad click predictions." Proceedings of the ADKDD'17. 2017. 1-7.
- [12] Guo, Huifeng, et al. "DeepFM: a factorization-machine based neural network for CTR prediction." arXiv preprint arXiv:1703.04247 (2017).
- [13] Lian, Jianxun, et al. "xdeepfm: Combining explicit and implicit feature interactions for recommender systems." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
- [14] Zhou, Guorui, et al. "Deep interest network for click-through rate prediction." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
- [15] Zhou, Guorui, et al. "Deep interest evolution network for click-through rate prediction." Proceedings of the AAAI conference on artificial intelligence. Vol. 33. No. 01. 2019.
- [16] Feng, Yufei, et al. "Deep session interest network for click-through rate prediction." arXiv preprint arXiv:1905.06482 (2019).
- [17] Ling, Xiaoliang, et al. "Model ensemble for click prediction in bing search ads." Proceedings of the 26th International Conference on World Wide Web Companion. 2017.
- [18] Zhao, Zhe, et al. "Recommending what video to watch next: a multitask ranking system." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
- [19] Haldar, Malay, et al. "Improving Deep Learning For Airbnb Search." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
- [20] Guo, Huifeng, et al. "PAL: a position-bias aware learning framework for CTR prediction in live recommender systems." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
- [21] Wang, Xuanhui, et al. "Learning to rank with selection bias in personal search." Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. 2016.
- [22] Joachims, Thorsten, Adith Swaminathan, and Tobias Schnabel. "Unbiased learning-to-rank with biased feedback." Proceedings of the Tenth ACM International Conference on Web Search and Data Mining. 2017.
- [23] Ai, Qingyao, et al. "Unbiased learning to rank with unbiased propensity estimation." The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.
- [24] Wang, Xuanhui, et al. "Position bias estimation for unbiased learning to rank in personal search." Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining. 2018.
- [25] Agarwal, Aman, et al. "Estimating position bias without intrusive interventions." Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. 2019.
- [26] Hu, Ziniu, et al. "Unbiased lambdamart: an unbiased pairwise learning-to-rank algorithm." The World Wide Web Conference. 2019.
- [27] Ovaisi, Zohreh, et al. "Correcting for selection bias in learning-to-rank systems." Proceedings of The Web Conference 2020. 2020.
- [28] Yuan, Bowen, et al. "Unbiased Ad click prediction for position-aware advertising systems." Fourteenth ACM Conference on Recommender Systems. 2020.
- [29] Qin, Zhen, et al. "Attribute-based propensity for unbiased learning in recommender systems: Algorithm and case studies." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
- [30] Vaswani, Ashish, et al. "Attention is all you need." arXiv preprint arXiv:1706.03762 (2017).
Read more technical articles from the
the front | algorithm | backend | data | security | operation and maintenance | iOS | Android | test
160c9a890b8fef | . You can view the collection of technical articles from the Meituan technical team over the years.

| This article is produced by the Meituan technical team, and the copyright belongs to Meituan. Welcome to reprint or use the content of this article for non-commercial purposes such as sharing and communication, please indicate "the content is reproduced from the Meituan technical team". This article may not be reproduced or used commercially without permission. For any commercial activity, please send an email to tech@meituan.com to apply for authorization.






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。