
大家好,我是张晋涛。

群里有个小伙伴问了我上图中这个问题,如何度量滚动升级这个过程的时间。
这个问题可以抽象为一种通用需求,适用于多种场景。
- 比如你是 Kubernetes 集群的管理员,你想度量这个过程中的耗时,以便发现优化点;
- 比如你是在做 CI/CD ,你想通过度量这个过程的耗时,来给出 CI/CD 过程的耗时;
现有方案
Kubernetes 已经提供了很方便的办法来解决此问题,也就是我回复中谈到的,通过 event 来度量即可。
比如,我们在 K8S 中,创建一个 deployment,看看这个过程中的 event 信息:
➜ ~ kubectl create ns moelove
namespace/moelove created
➜ ~ kubectl -n moelove create deployment redis --image=ghcr.io/moelove/redis:alpine
deployment.apps/redis created
➜ ~ kubectl -n moelove get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
redis 1/1 1 1 16s
➜ ~ kubectl -n moelove get events
LAST SEEN TYPE REASON OBJECT MESSAGE
27s Normal Scheduled pod/redis-687967dbc5-gsz5n Successfully assigned moelove/redis-687967dbc5-gsz5n to kind-control-plane
27s Normal Pulled pod/redis-687967dbc5-gsz5n Container image "ghcr.io/moelove/redis:alpine" already present on machine
27s Normal Created pod/redis-687967dbc5-gsz5n Created container redis
27s Normal Started pod/redis-687967dbc5-gsz5n Started container redis
27s Normal SuccessfulCreate replicaset/redis-687967dbc5 Created pod: redis-687967dbc5-gsz5n
27s Normal ScalingReplicaSet deployment/redis Scaled up replica set redis-687967dbc5 to 1可以看到我们主要关注的一些事件均已经有记录了。但是总不能每次都通过 kubectl 这么来看吧,有点浪费时间。
我之前的一种做法是在 K8S 中写了一个程序,持续的监听&收集 K8S 集群中的 event ,并将它写入到我另外开发的一套系统中进行存储和可视化。但这种方法需要做额外的开发也并不普适。这里我来介绍另一个更优的解决方案。
更优雅的方案
K8S 中的这些事件,都对应着我们的一个操作,比如上文中是创建了一个 deployment ,它产生了几个 event , 包括 Scheduled , Pulled ,Created 等。我们将其进行抽象,是不是和我们做的链路追踪(tracing)很像呢?
这里我们会用到一个 CNCF 的毕业项目 Jaeger ,在之前的 K8S生态周报 中我有多次介绍它,Jaeger 是一款开源的,端对端的分布式 tracing 系统。不过本文重点不是介绍它,所以我们查看其文档,快速的部署一个 Jaeger 即可。另一个 CNCF 的 sandbox 级别的项目是 OpenTelemetry 是一个云原生软件的可观测框架,我们可以把它跟 Jaeger 结合起来使用。不过本文的重点不是介绍这俩项目,这里暂且略过。
接下来介绍我们这篇文章的用到的主要项目,是来自 Weaveworks 开源的一个项目,名叫 kspan ,它的主要做法就是将 K8S 中的 event 作为 trace 系统中的 span 进行组织。
部署 kspan
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kspan
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
creationTimestamp: null
name: kspan-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kspan
namespace: default
---
apiVersion: v1
kind: Pod
metadata:
labels:
run: kspan
name: kspan
spec:
containers:
- image: docker.io/weaveworks/kspan:v0.0
name: kspan
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
serviceAccountName: kspan
可以直接使用我这里提供的 YAML 进行部署测试,但注意上述配置文件别用在生产环境下, RBAC 权限需要修改 。
它默认会使用 otlp-collector.default:55680 传递 span ,所有你需要确保有这个 svc 存在。以上所有内容部署完成后你大概会是这样:
➜ ~ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/jaeger-76c84457fb-89s5v 1/1 Running 0 64m
pod/kspan 1/1 Running 0 35m
pod/otel-agent-sqlk6 1/1 Running 0 59m
pod/otel-collector-69985cc444-bjb92 1/1 Running 0 56m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/jaeger-collector ClusterIP 10.96.47.12 <none> 14250/TCP 60m
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 39h
service/otel-collector ClusterIP 10.96.231.43 <none> 4317/TCP,14250/TCP,14268/TCP,9411/TCP,8888/TCP 59m
service/otlp-collector ClusterIP 10.96.79.181 <none> 55680/TCP 52m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/otel-agent 1 1 1 1 1 <none> 59m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/jaeger 1/1 1 1 73m
deployment.apps/otel-collector 1/1 1 1 59m
NAME DESIRED CURRENT READY AGE
replicaset.apps/jaeger-6f77c67c44 0 0 0 73m
replicaset.apps/jaeger-76c84457fb 1 1 1 64m
replicaset.apps/otel-collector-69985cc444 1 1 1 59m上手实践
这里我们先创建一个 namespace 用于测试:
➜ ~ kubectl create ns moelove
namespace/moelove created创建一个 Deployment
➜ ~ kubectl -n moelove create deployment redis --image=ghcr.io/moelove/redis:alpine
deployment.apps/redis created
➜ ~ kubectl -n moelove get pods
NAME READY STATUS RESTARTS AGE
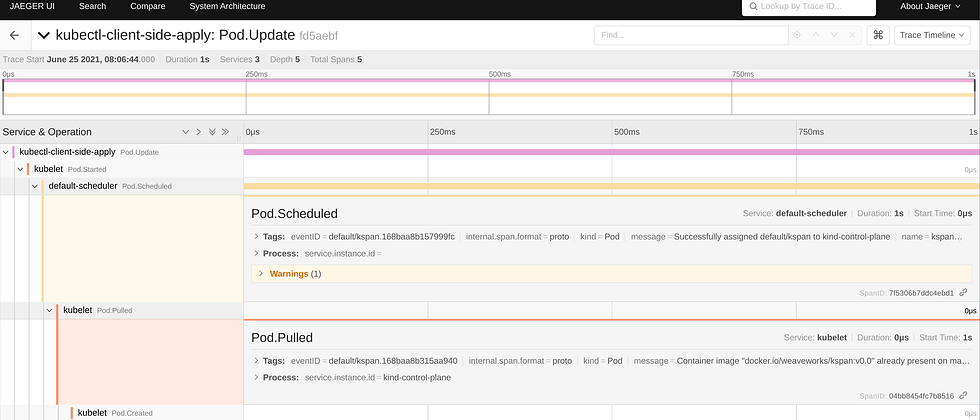
redis-687967dbc5-xj2zs 1/1 Running 0 10s在 Jaeger 上进行查看:

点开看详细内容

可以看到,和此创建 deploy 有关的 event 均被归到了一起,在时间线上可以看到其耗时等详细信息。
总结
本文介绍了如何结合 Jaeger 利用 tracing 的方式来采集 K8S 中的 events ,以便更好的掌握 K8S 集群中所有事件的耗时点,更易于找到优化的方向及度量结果。
欢迎订阅我的文章公众号【MoeLove】








**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。