

The topic I shared this time is still the same as in "16108bf4b23be8 The Future of Database ". If you are an old friend of PingCAP, you will know that after participating in the previous DevCon, this is a repertoire of mine. If I want to say where I have some distinctive temperament, I think that besides my hairstyle, there is another belief and persistence in technology. We still talk about technology in this repertoire.
What has been the biggest change in technology of TiDB in the past two years? There may be many students who think that the performance is getting better and better, the functions are getting more and more, the ecological functions are getting bigger and bigger, in fact it is not.

From a programmer's point of view, TiDB has actually completed a very important change in the past two years, that is, the development model change . On the left side of the picture above, an engineer is writing code to the screen. This is the state where we started writing the first line of code in TiDB in the first office in the early years. There was a bottle of coke and pizza next to it, and what to write about. Now TiDB's entire R&D process is more and more like the picture on the right, with a small factory streamlining to make mooncakes. Although it is still a little away from the Mid-Autumn Festival, it is still very cute.
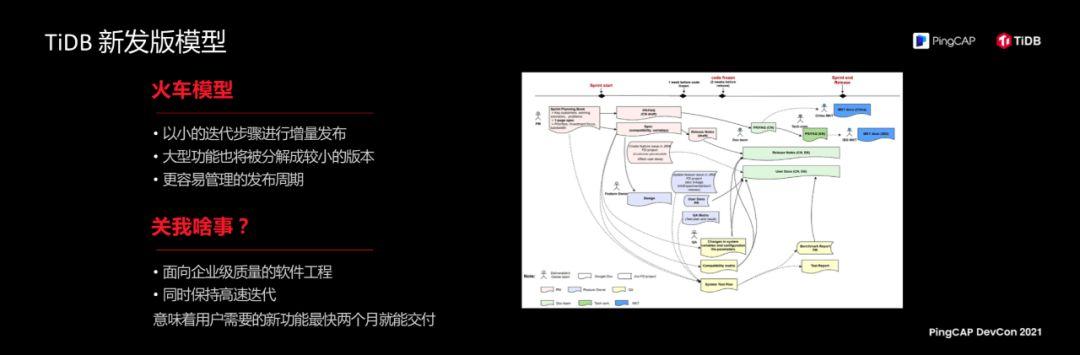
One of the most important things for TiDB in the past two years is that the R&D process uses a brand new release model to do software engineering. We call it the "train release" model. The characteristic of this model is that we will release many large features gradually in small iterations, which means that it is easier to manage the release cycle.
Many people may say "what's up to me?" The significance of this matter is that TiDB has gradually evolved from a pure community open source software to an enterprise-level database product . To put it more grounded, the features needed in the user's real scene can be merged into the backbone of TiDB and delivered to the user in two months at the earliest.
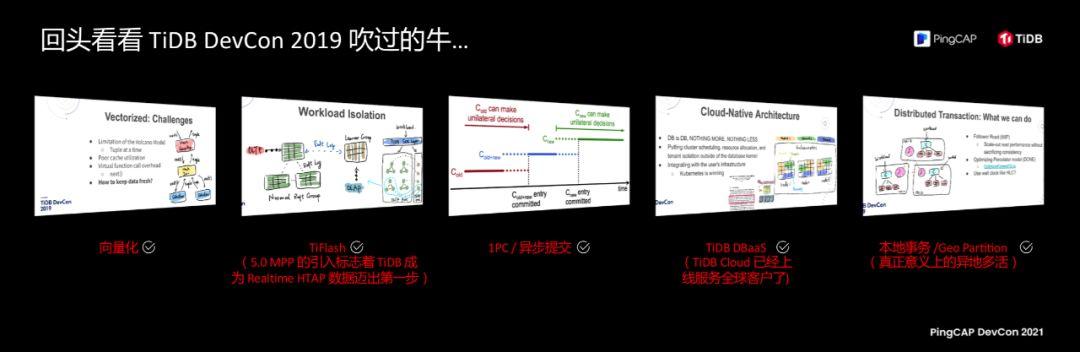
Two years ago, the topic of my speech was also "The Future of Database". The picture above is a screenshot of the speech two years ago. Vectorization, which was a challenge at the time, has now been completed; TiFlash, which was just an architecture designed on a sketch at the time, made it a real Real-time HTAP database after the introduction of MPP in 5.0; IPC/asynchronous submission , The performance and stability of 5.0 have been steadily improved; TiDB DBaaS, and now TiDB Cloud has served thousands of households, serving real products in all parts of the world; local affairs have been worked in different places, and they have been completed in two years.
The five big ideas two years ago have all become reality today.
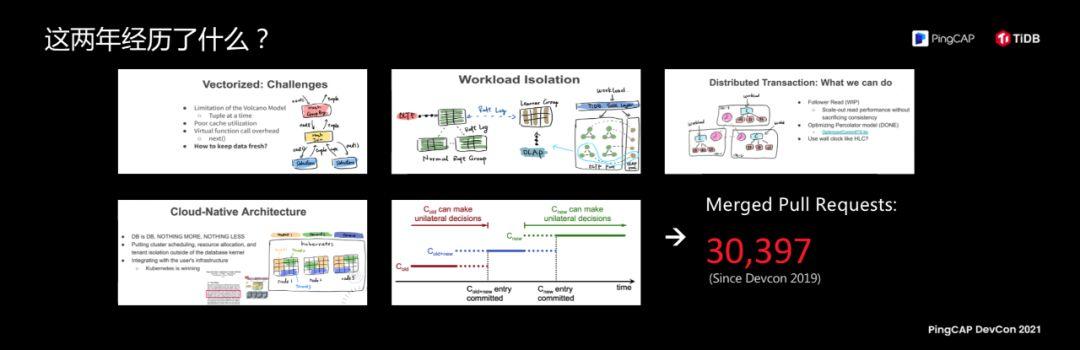
In the two years from 2019 to the present, what have we experienced behind these is a merger of more than 30,000 PRs in two years. People always grow. What is the difference between me two years ago and me now? The hairstyle has not changed, and the T-shirts are also the same. What has changed is that TiDB has merged more than 30,000 PRs. Looking back at my PPT two years ago, I was thinking about a question, what is the competitiveness or core advantage of TiDB? Many databases say that their core advantages are good performance and multiple functions. So, what are the advantages of TiDB?

Two years ago, there was a page in my PPT called Everything is Pluggable. I think it has a special taste. TiDB The real advantage of 16108bf4b23cf7 lies in the openness of technology. opening of the 16108bf4b23cf8 architecture means that more connections can be generated, and more connections mean faster iteration speed and more possibilities.
Why is the core advantage of TiDB's system openness? You can take a few seconds to think about it. This angle of thinking has allowed me to slowly become a philosopher over the past two years. This perspective is: What is the most essential difference between a stand-alone database and a distributed database? Where is the root of the pain and happiness of engineers working as distributed databases? What is our real enemy? What kind of problems are we going to solve? How do we solve these problems?
As a designer of a system, when the system of thinking, I think our real enemy is complexity. TiDB is a software with millions of lines of code that runs on 3 machines, and it is still the same code when running on 30, 300, and 30,000 servers. Imagine that the complexity of 3 machines is the same as the complexity of 30,000 machines?
What is the most complex system we have seen in our lives? It is a living life, and life is the most complex system. Including everyone interacting with this world every day, we have no way to predict tomorrow. When we look at a complex system like life, we look into the human life as a fertilized egg at the very beginning. The cell keeps dividing, which is very simple. Looking down on DNA, permutations and combinations, I think that from the perspective of life and oneself, we can really find a solution to the complexity of confrontation. This is simple.

Here is a sentence from Teacher Chopin, really difficult to make the system simple, and simple means beautiful . TiDB's design philosophy in this regard is still a bit different from many conventional practices. I just mentioned a sentence, where is the root of our happiness and pain? Just now I mentioned that we are a different company. Technically, think deeply about what is the difference between us and other databases? I think the most fundamental difference lies in the core design concept. When you understand the core design concept of TiDB and then look at the technical architecture design of TiDB, you will naturally be able to figure out many specific technical problems, and you can also think of why we did this.
This is a usual thinking on the left, 1) I want to make a database, 2) What will I do when I make a distributed database, 3) I try to slice the tables on these databases, partition tables, and put different partitions in It is distributed on different servers.
We have never made a database in the past, but we have a crazy idea. The idea is that we want to make a distributed database. We started by defining the smallest flow unit of data, like the cells in the animation we just saw. In the same way, we define the division, merger, movement, replication, and reproduction of these cells. uses these rules to give these cells life with the most simple, orthogonal, and self-consistent rules, so that these cells can grow into a database, which is the core concept of . What is the essential difference between a stand-alone database and a distributed database? A distributed database can grow on one machine.
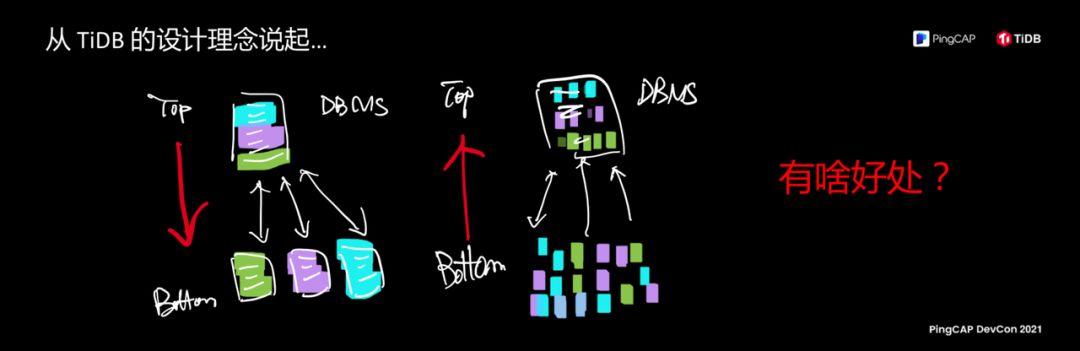
The picture on the left explains it. Normally, it is designed like this. Almost all databases are designed from top to bottom. TiDB is a bottom-up design. First define the underlying cell and let it grow into a database. .

The next question, let everyone think for a few seconds, and pave the way for everyone. The nouns on the left, two places and three centers, live in different places, cross-regional data distribution capabilities, local affairs, dynamic hot spots, real-time online statistics, read-only surface. What do these functions have in common?
Q: If I want to implement these functions, how should I implement them? What is the common ground behind these functions? Is there a key point that all abilities can be immediately possessed after solving this point? Is there such a thing?

The answer is revealed. All these technical terms and all the things that users just mentioned rely on a capability that is " scheduling ". I just mentioned that question, a single-machine database, a single-machine system and What is the most essential difference between distributed systems? The answer I gave is the schedulable capability, which is the main capability that distinguishes it from a stand-alone system. Scheduling capability is the foundation of openness. An open architecture cannot allow this database to remain unchanged. This change is like remodeling itself into a database that is more suitable for user scenarios. If there is no such capability, a distributed system If it becomes meaningless, you cannot say that you are an open system.
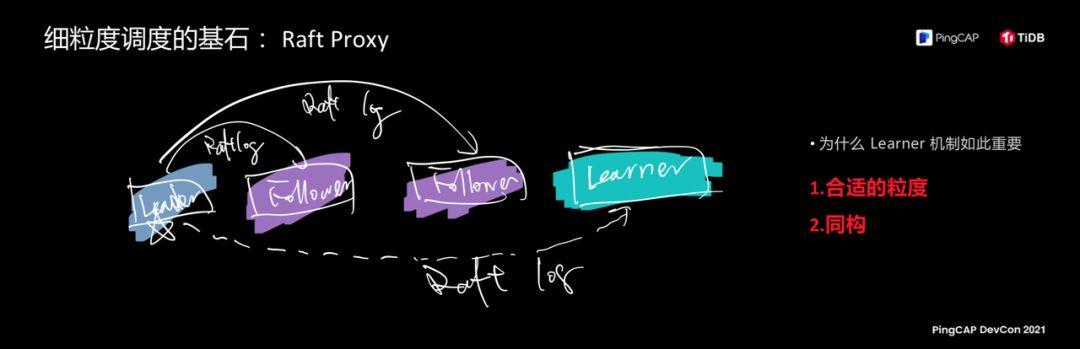
Therefore, this is actually the core and most shining value of TiDB in the technical architecture. Today we talk about technology, what we have done in terms of schedulability, this is a big game, not a feature, this is a concept, we look at what this concept will look like in the past, present and in the future. Friends who are familiar with Raft Proxy technology, in the underlying architecture, the cell I mentioned just now is a replication group based on the Raft replication protocol. This is actually the most fine-grained unit of our entire scheduling. We give it self on these data replication groups. The ability to multiply, divide, merge, and move. There is a Learner in the picture on the right, and the user will smile. It is appropriate to choose such a unit as a cell. The behavior of each cell is the same, and it is isomorphic.
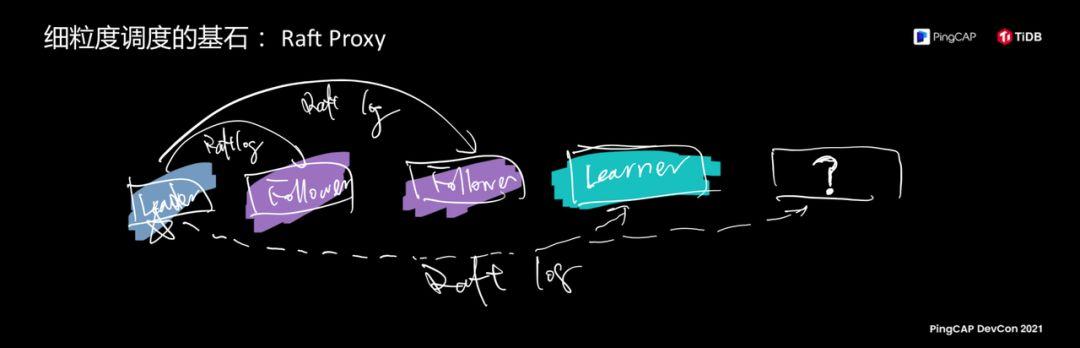
Let’s fly again. It turns out that the first time that Learner’s technology was cited, we wanted to find an application scenario for it. This application scenario is TiFlash. It was originally just a small experiment in our brain. Can I make it replicate on this cell? Small piece, let it do something else? At that time, we felt that the AP was not very capable and needed the data structure of the underlying data storage column storage. We put this architecture on the replica to allow it to support column storage, so TiDB has HTAP On this basis, a small team has built the entire Real-Time HTAP system in less than two years.
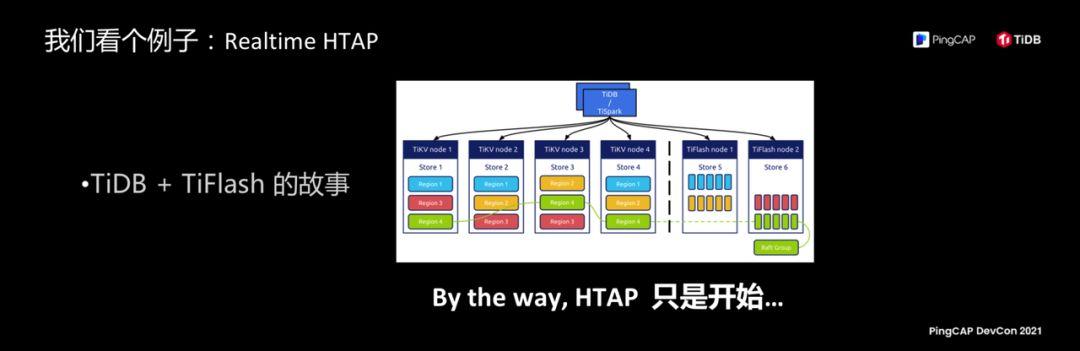
Why did it happen so quickly? TiFlash is an excellent example of the concept of schedulability, and there are many strange ideas in my mind, Real-Time HTAP, TiFlash is just the beginning of .
The finest-grained scheduling capability and schedulable scheduling capability. Let's look further up. Some friends are familiar with Foreign Data Wrapper (FDW), but TiDB does not yet support Foreign Data Wrapper. This function is easier to understand. Let TiDB use other data sources as an internal table for querying. For example, when this function is supported, I can use Redis as an external table in TiDB and MySQL The data serves as an external table, which can be correlated and analyzed with HBase.
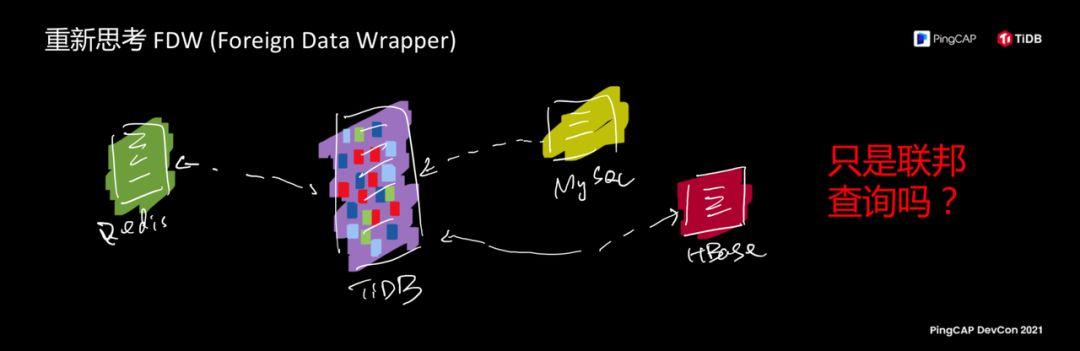
However, does FDW only mean "federal queries"? I am thinking about why this feature is? Because when I was looking at this feature, I thought about the nature of the database. What is the nature of the software like a database? When you put aside all data structures, storage capabilities, and all functions, what exactly is stored in the database? database separates all the concepts I just mentioned. It only does two things. One is to store real data, and the other part is called an index. The database is nothing more than data and indexes. . According to the idea just now, the entire database is regarded as a container for data and indexes. The concept of index is actually a special mapping table relationship. An index is also a table. The content you want to index corresponds to the mapping relationship on the data.
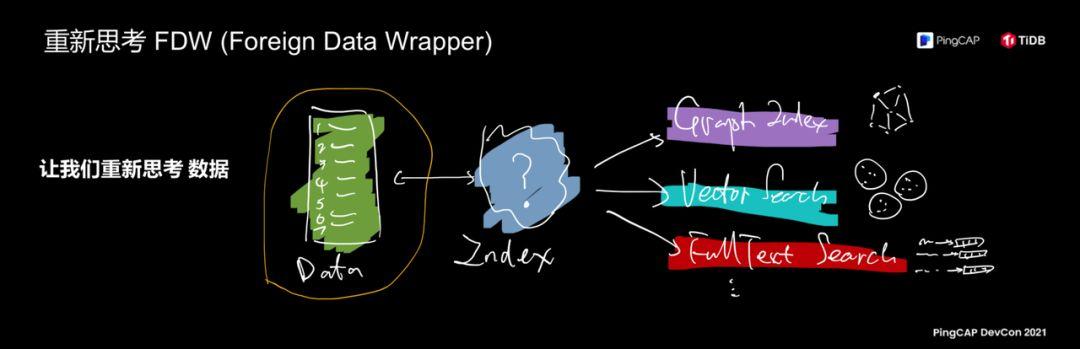
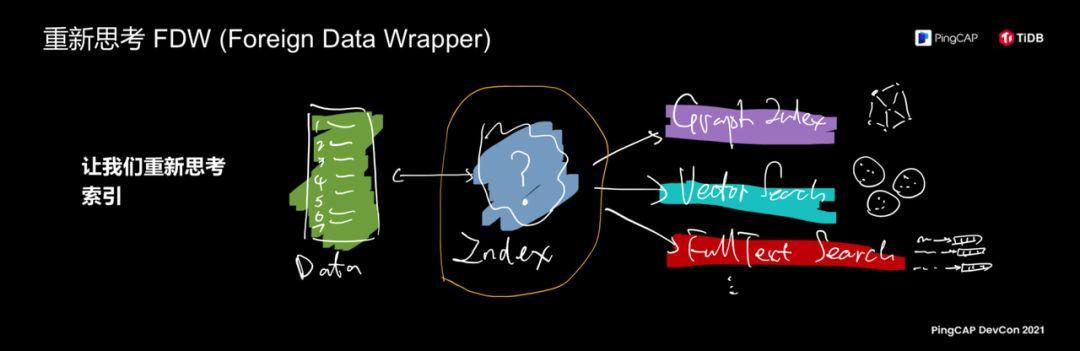
Then we will rethink FDW following this idea. On the right is my soul painting style, which is a bit difficult to understand. Today’s trends in the entire database industry, one of which is the emergence of databases in various subdivisions, graph databases, vector search databases, full-text search databases, and TiDB. Turn the capabilities of these databases into its indexing capabilities? For example, I have a table that stores user relationships and user information. Everyone knows that the search and query on a relationship is better with a graph model. If it is a traditional data structure, for example, I use an index to query. Very slow, using the graph model can greatly speed up this performance. If you think about it from this perspective, TiDB's index can be connected to these other databases, allowing other databases to serve as TiDB indexes, and at the same time providing users with a unified interface, does it feel like opening the door to the new century?
The theme of today's conference is Open × Connect × Foresight.
I think it’s particularly interesting that this "×" number , I don’t know how much possibility these things can bring to the ecology of TiDB, anyone trying to estimate its value is arrogant, we can What we do is to lay these foundations for developers. This is the part of the index.
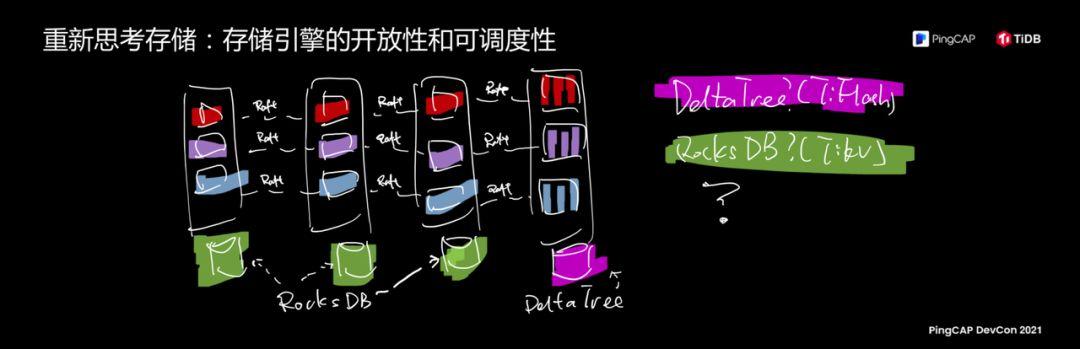
Let's look down again. One of the essence of databases is data and the other is indexing. Now we look at data. The first association with data is the storage engine. The storage of data is the most critical topic. Students who are familiar with the overall system architecture of TiDB are certainly not unfamiliar with the soul-painting picture on the left. I mentioned earlier that TiDB actually splits the data into countless small cells internally, and each cell is a copy. Group, split, merge, move. But at the physical level, we are now using Real-time HTAP based on Database. The bottom layer of TiKV is Rocks DB, and the storage engine used by TiFlash is named Delta tree, two engines.
Can there be more?
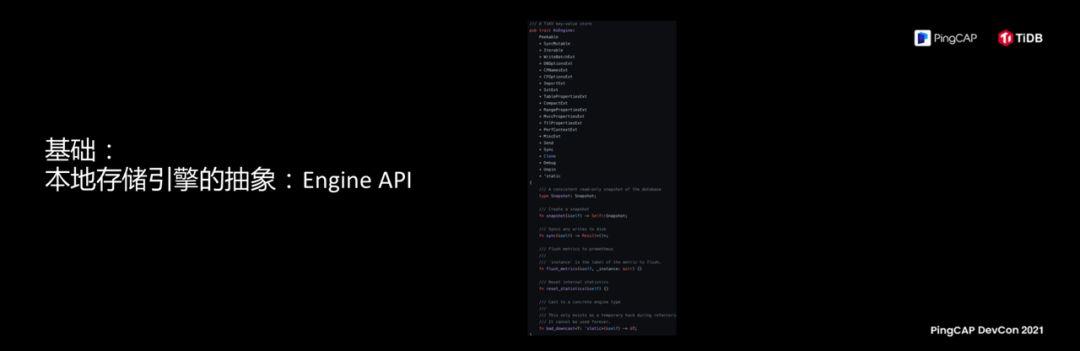
To reflect the ability of openness and schedulability in storage, a basic premise is to abstract the storage engine. If you are familiar with the code of TiDB, if you look at its code repository, you will find a very interesting folder called Engine API , this thing is particularly interesting, I put the code directly, which means that we are trying to abstract the capabilities of the storage itself, this abstraction is a basis.
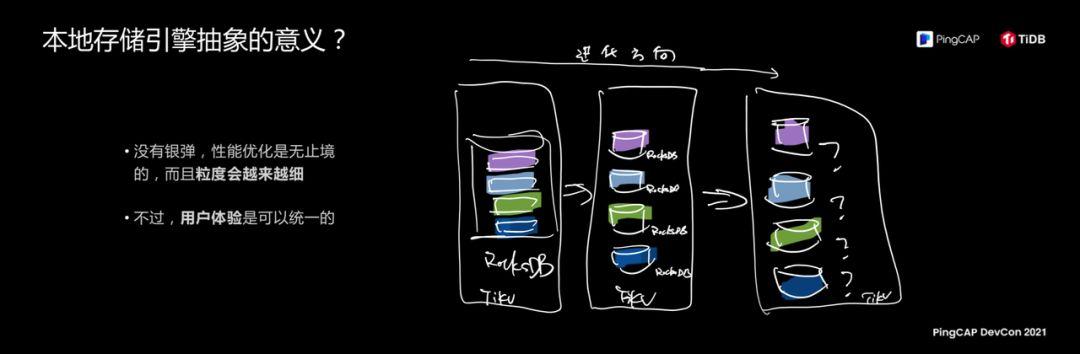
What is the meaning of this abstract? Why do we do this? My judgment on the future is why, in general, the person in charge of database technology always talks about performance and function, and why are we discussing philosophy today? Because I think from a longer dimension, when your software maintains high-speed iteration capabilities, it is a dynamic evolutionary process. What is the end of evolution?
Let's look at performance first. In the development process of TiDB, each version has maintained a 100% performance improvement speed. It can be maintained to 6.0, and 7.0 is a 100% increase every time. Future optimization is endless. I personally think that I will not say that a new hardware and algorithm has been invented to solve the performance problems of all application scenarios in the world. The granularity will become finer and finer. There are some optimizations for certain specific scenarios, such as storage The user's association and relationship is the best model of the graph. But one thing is that I don’t think the user has to care about what kind of database structure he is using, which piece of data is using which data structure, these are not important.
The figure on the right reveals a huge thing TiDB is doing. The amount of information is very large. What we do, the abstraction of Engine API just now allows us to do one thing. Friends who are familiar with TiDB know that we are in a storage node. The above is to share a storage engine. Now we are slowly slicing each piece of data so that each cell can have its own storage engine. This thing has been done in our laboratory. The effect is very good. I was shocked at the time. .
In the next step of development, when I split the cell storage of the data, it doesn’t matter whether the next step is a Delta tree. For example, I have some data that is only accessed once a year in a business scenario, but I can’t lose it. And I don’t want to use SSD for storage. Can I use S3 storage on the cloud? Even a piece of data in a table is extremely hot, and the consistency requirements are not so high. Can I use the form of this piece of data in the memory? Make a transformation. What's more interesting is that all these transformations are dynamic and transparent to the business. Recall the concepts of schedulability and cells I just mentioned.
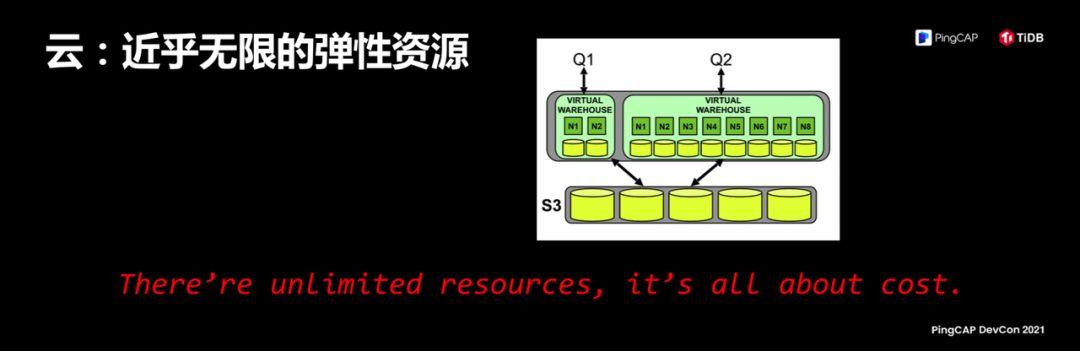
I said all of these technologies are aimed at one thing, we need to build a foundation, I just said a final and distributed systems, distributed systems can dispatch its core strengths, this basis, I believe you can probably Guess what, I need to have a near-infinite elastic resource pool, which is the cloud. Regarding the importance of cloud, I think the entire industry is still underestimating it. Now I talk about cloud every day, but I think cloud is actually the most important cornerstone for building a new generation of software in the future.
I think there is a good saying about cloud. What do I think of cloud as a software engineer? I used unlimited resources, like a pile of wood, how can I put it together, how much money can I put together. The picture on the right is the architecture of Flink. Flink is a very interesting product. It has a variety of news on the market, but I first noticed it in 2016. When it published its first paper, I saw that This paper is one of my favorite papers in recent years. The greater significance of that paper is that it has created a new kind of software design idea, created a new species, basic software based on cloud services, It is the first, but definitely not the last. TiDB is one of the leading software in this field.

The core idea of , 16108bf4b24066 openness is embodied in pluggability, storage and computing are pluggable and schedulable, borrowing today’s theme "×" and multiplying it by the scheduling capability, it can be scheduled after being pluggable, fine-grained, coarse-grained Scheduling, multiplied by the almost unlimited resources on the cloud, what does it mean?
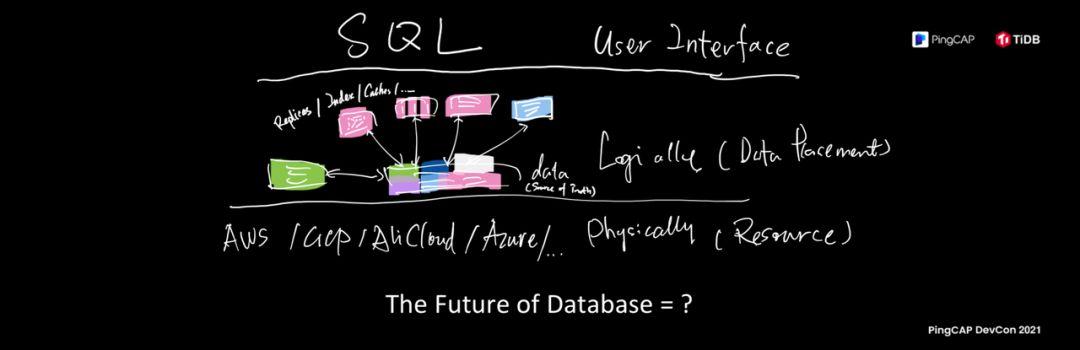
Looking back at my topic today, The Future Database, what is the ultimate Future, This picture is what my ideal database looks like : Various resource pools at the bottom, various clouds, public clouds, Private cloud, hybrid cloud; the middle logic layer above is the data platform. Different users have different business data and have different requirements for the database. The database will automatically reshape itself according to the needs of users; in different granularities, from the copy Distribution We do global cross-data center deployment. This capability is not too expensive for TiDB. I just said scheduling capability and indexing. We can introduce various types of indexes through FDW in the future. A small brain hole is opened, and the database of the graph is used as the index of TiDB, and its shape is changed according to the needs of users.

So, boldly predict that the formula just now "pluggability × scheduling capacity × almost unlimited resources on the cloud =?", database as an independent software form I think it will be subverted, and mean the entire database "data" "Service platformization" will rise . Many of our next generations are parents. The next generation of children may be at the age of writing programs. They may not know what is CPU, what is memory, what is disk, and what is operating system. You may see cloud services one by one. For example, when you want to use a database, it seems that there is a TiDB thing. After I tie the credit card, I can directly use a SQL interface to operate it, and I don’t need to know what an index is. What is Delta tree.
Let’s look back at the three keywords of our conference today. open, connected, and foreseen. Only an open architecture can have more connections, and more connections can make us have a better future. This is my technology about TiDB today. And the sharing of design ideas.





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。