

原创:码农参上(微信公众号ID:CODER_SANJYOU),欢迎分享,转载请保留出处。
提到Java中的垃圾回收,我相信很多小伙伴和我一样,第一反应就是面试必问了,你要是没背过点GC算法、收集器什么的知识,出门都不敢说自己背过八股文。说起来还真是有点尴尬,工作中实际用到这方面知识的场景真是不多,并且这东西学起来也很枯燥,但是奈何面试官就是爱问,我们能有什么办法呢?
既然已经卷成了这样,不学也没有办法,Hydra牺牲了周末时间,给大家画了几张动图,希望通过这几张图,能够帮助大家对垃圾收集算法有个更好的理解。废话不多说,首先还是从基础问题开始,看看怎么判断一个对象是否应该被回收。
判断对象存活
垃圾回收的根本目的是利用一些算法进行内存的管理,从而有效的利用内存空间,在进行垃圾回收前,需要判断对象的存活情况,在jvm中有两种判断对象的存活算法,下面分别进行介绍。
1、引用计数算法
在对象中添加一个引用计数器,每当有一个地方引用它时计数器就加 1,当引用失效时计数器减 1。当计数器为0的时候,表示当前对象可以被回收。
这种方法的原理很简单,判断起来也很高效,但是存在两个问题:
- 堆中对象每一次被引用和引用清除时,都需要进行计数器的加减法操作,会带来性能损耗
- 当两个对象相互引用时,计数器永远不会0。也就是说,即使这两个对象不再被程序使用,仍然没有办法被回收,通过下面的例子看一下循环引用时的计数问题:
public void reference(){
A a = new A();
B b = new B();
a.instance = b;
b.instance = a;
}引用计数的变化过程如下图所示:

可以看到,在方法执行完成后,栈中的引用被释放,但是留下了两个对象在堆内存中循环引用,导致了两个实例最后的引用计数都不为0,最终这两个对象的内存将一直得不到释放,也正是因为这一缺陷,使引用计数算法并没有被实际应用在gc过程中。
2、可达性分析算法
可达性分析算法是jvm默认使用的寻找垃圾的算法,需要注意的是,虽然说的是寻找垃圾,但实际上可达性分析算法寻找的是仍然存活的对象。至于这样设计的理由,是因为如果直接寻找没有被引用的垃圾对象,实现起来相对复杂、耗时也会比较长,反过来标记存活的对象会更加省时。
可达性分析算法的基本思路就是,以一系列被称为GC Roots的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,证明该对象不再存活,可以作为垃圾被回收。

在java中,可作为GC Roots的对象有以下几种:
- 在虚拟机栈(栈帧的本地变量表)中引用的对象
- 在方法区中静态属性引用的对象
- 在方法区中常量引用的对象
- 在本地方法栈中JNI(
native方法)引用的对象 - jvm内部的引用,如基本数据类型对应的Class对象、一些常驻异常对象等,及系统类加载器
- 被同步锁
synchronized持有的对象引用 - 反映jvm内部情况的
JMXBean、JVMTI中注册的回调本地代码缓存等 - 此外还有一些临时性的GC Roots,这是因为垃圾收集大多采用分代收集和局部回收,考虑到跨代或跨区域引用的对象时,就需要将这部分关联的对象也添加到GC Roots中以确保准确性
其中比较重要、同时提到的比较多的还是前面4种,其他的简单了解一下即可。在了解了jvm是如何寻找垃圾对象之后,我们来看一看不同的垃圾收集算法的执行过程是怎样的。
垃圾收集算法
1、标记-清除算法
标记清除算法是一种非常基础的垃圾收集算法,当堆中的有效内存空间耗尽时,会触发STW(stop the world),然后分标记和清除两阶段来进行垃圾收集工作:
- 标记:从GC Roots的节点开始进行扫描,对所有存活的对象进行标记,将其记录为可达对象
- 清除:对整个堆内存空间进行扫描,如果发现某个对象未被标记为可达对象,那么将其回收
通过下面的图,简单的看一下两阶段的执行过程:

但是这种算法会带来几个问题:
- 在进行GC时会产生STW,停止整个应用程序,造成用户体验较差
- 标记和清除两个阶段的效率都比较低,标记阶段需要从根集合进行扫描,清除阶段需要对堆内所有的对象进行遍历
- 仅对非存活的对象进行处理,清除之后会产生大量不连续的内存碎片。导致之后程序在运行时需要分配较大的对象时,无法找到足够的连续内存,会再触发一次新的垃圾收集动作
此外,jvm并不是真正的把垃圾对象进行了遍历,把内部的数据都删除了,而是把垃圾对象的首地址和尾地址进行了保存,等到再次分配内存时,直接去地址列表中分配,通过这一措施提高了一些标记清除算法的效率。
2、复制算法
复制算法主要被应用于新生代,它将内存分为大小相同的两块,每次只使用其中的一块。在任意时间点,所有动态分配的对象都只能分配在其中一个内存空间,而另外一个内存空间则是空闲的。复制算法可以分为两步:
- 当其中一块内存的有效内存空间耗尽后,jvm会停止应用程序运行,开启复制算法的gc线程,将还存活的对象复制到另一块空闲的内存空间。复制后的对象会严格按照内存地址依次排列,同时gc线程会更新存活对象的内存引用地址,指向新的内存地址
- 在复制完成后,再把使用过的空间一次性清理掉,这样就完成了使用的内存空间和空闲内存空间的对调,使每次的内存回收都是对内存空间的一半进行回收
通过下面的图来看一下复制算法的执行过程:
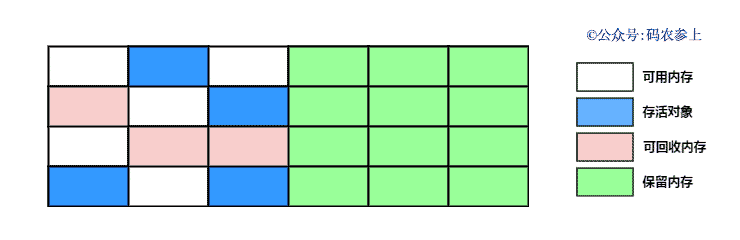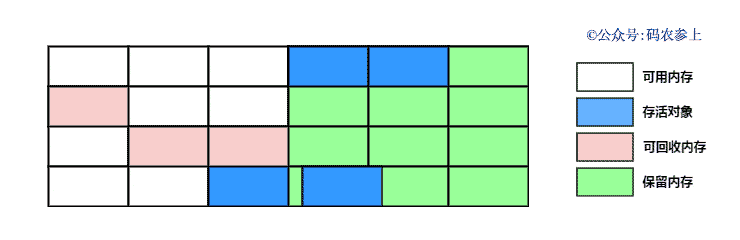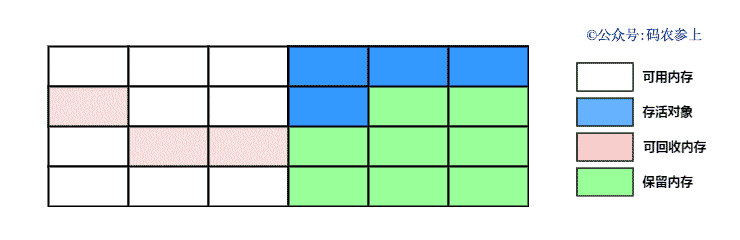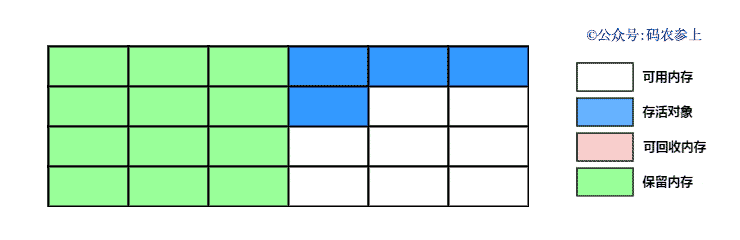
复制算法的的优点是弥补了标记清除算法中,会出现内存碎片的缺点,但是它也同样存在一些问题:
- 只使用了一半的内存,所以内存的利用率较低,造成了浪费
- 如果对象的存活率很高,那么需要将很多对象复制一遍,并且更新它们的应用地址,这一过程花费的时间会非常的长
从上面的缺点可以看出,如果需要使用复制算法,那么有一个前提就是要求对象的存活率要比较低才可以,因此,复制算法更多的被用于对象“朝生暮死”发生更多的新生代中。
3、标记-整理算法
标记整理算法和标记清除算法非常的类似,主要被应用于老年代中。可分为以下两步:
- 标记:和标记清除算法一样,先进行对象的标记,通过GC Roots节点扫描存活对象进行标记
- 整理:将所有存活对象往一端空闲空间移动,按照内存地址依次排序,并更新对应引用的指针,然后清理末端内存地址以外的全部内存空间
标记整理算法的执行过程如下图所示:
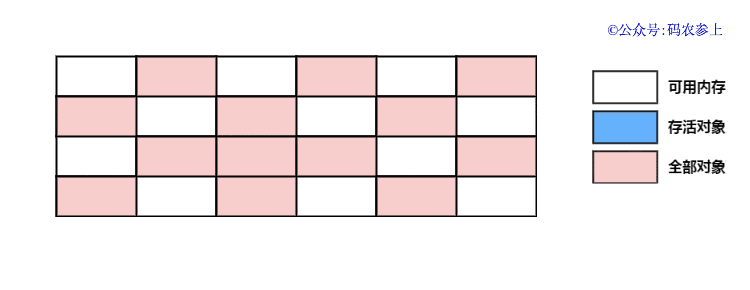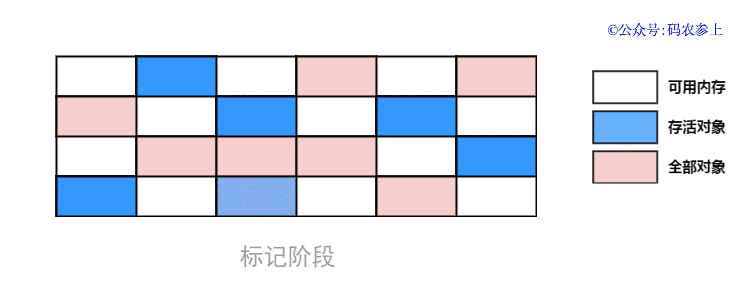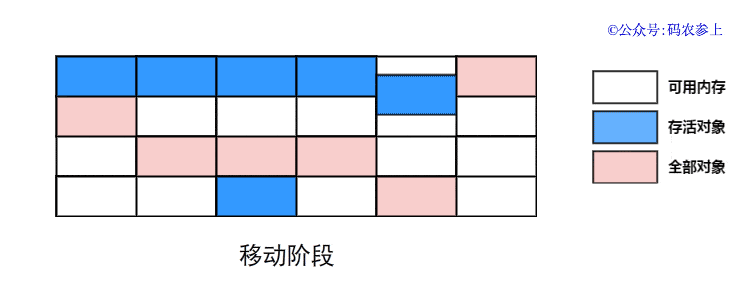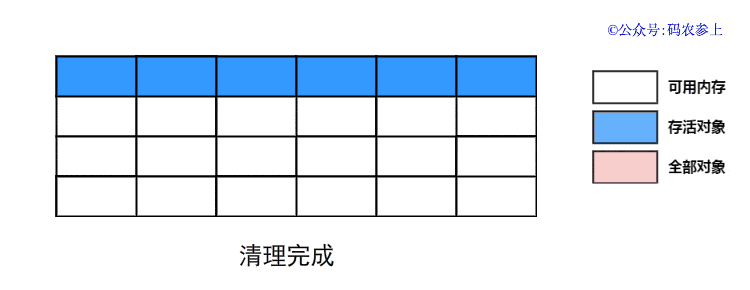
可以看到,标记整理算法对前面的两种算法进行了改进,一定程度上弥补了它们的缺点:
- 相对于标记清除算法,弥补了出现内存空间碎片的缺点
- 相对于复制算法,弥补了浪费一半内存空间的缺点
但是同样,标记整理算法也有它的缺点,一方面它要标记所有存活对象,另一方面还添加了对象的移动操作以及更新引用地址的操作,因此标记整理算法具有更高的使用成本。
4、分代收集算法
实际上,java中的垃圾回收器并不是只使用的一种垃圾收集算法,当前大多采用的都是分代收集算法。jvm一般根据对象存活周期的不同,将内存分为几块,一般是把堆内存分为新生代和老年代,再根据各个年代的特点选择最佳的垃圾收集算法。主要思想如下:
- 新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要复制少量对象以及更改引用,就可以完成垃圾收集
- 老年代中,对象存活率比较高,使用复制算法不能很好的提高性能和效率。另外,没有额外的空间对它进行分配担保,因此选择标记清除或标记整理算法进行垃圾收集
通过图来简单看一下各种算法的主要应用区域:

至于为什么在某一区域选择某种算法,还是和三种算法的特点息息相关的,再从3个维度进行一下对比:
- 执行效率:从算法的时间复杂度来看,复制算法最优,标记清除次之,标记整理最低
- 内存利用率:标记整理算法和标记清除算法较高,复制算法最差
- 内存整齐程度:复制算法和标记整理算法较整齐,标记清除算法最差
尽管具有很多差异,但是除了都需要进行标记外,还有一个相同点,就是在gc线程开始工作时,都需要STW暂停所有工作线程。
总结
本文中,我们先介绍了垃圾收集的基本问题,什么样的对象可以作为垃圾被回收?jvm中通过可达性分析算法解决了这一关键问题,并在它的基础上衍生出了多种常用的垃圾收集算法,不同算法具有各自的优缺点,根据其特点被应用于各个年代。
虽然这篇文章唠唠叨叨了这么多,不过这些都还是基础的知识,如果想要彻底的掌握jvm中的垃圾收集,后续还有垃圾收集器、内存分配等很多的知识需要理解,不过我们今天就介绍到这里啦,希望通过这一篇图解,能够帮助大家更好的理解垃圾收集算法。
最后,提前祝大家国庆小长假愉快,我们下篇见~
作者简介,码农参上(CODER_SANJYOU),一个热爱分享的公众号,有趣、深入、直接,与你聊聊技术。个人微信DrHydra9,欢迎添加好友,进一步交流。

**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。