
最近有读者私聊我时发现有不少应届生和初学者,他们在大数据怎么学,以及大数据怎么面试,简历怎么写等方面有很大的困扰,今天我们就来谈谈关于大数据的一些事。
写在前面:每个人的学习方法可能不一样,只有找到适合自己的才是最好的,以下这些只是我在学习大数据时的一些总结及经验,有不全面的地方还请各位大佬多包涵,互相学习,共同进步,非常感谢!
我之前在知乎回答过类似的问题,有人问大数据工程师的日常工作内容是干嘛?,我当时看到之后就随意回答了下,先说了下大数据日常干嘛,然后又说了下怎么准备大数据的面试,怎么学大数据等等,没想到反响还挺好,截图了部分评论:




今天走心回答一波,把知乎回答的内容再整理下。

1. 大数据学习
大数据怎么学,该学哪些东西,不需要学哪些东西,是大家问的最多的一个问题,也有不少同学问培训机构讲的框架太多了,是否都要掌握,接下来我们逐个解析。
从 2008 年 Hadoop 成为 Apache 顶级项目开始,大数据迎来了体系化的快速发展,到如今已经走过十几个年头,这些年里大数据框架层出不穷,可以用“乱花渐欲迷人眼”形容,框架这么多,应该怎么学?
我们可以思考下整个大数据的流程是什么,从数据采集->数据存储->数据处理->数据应用,再加一个任务调度。每个流程都有很多对应的大数据框架,我们学习其中一两个比较重要,也就是企业用的较多的框架即可。
数据采集:就是把数据从其他平台采集到我们大数据平台,只是负责采集数据,所以对这个流程的框架要求是会用即可,日志采集工具如Flume,大数据平台与传统的数据库(mysql、postgresql...)间进行数据的传递工具如Sqoop,我们会用即可,这种工具上手也很快,没有太复杂的功能。
数据存储:数据存储就比较重要了,大数据如此流行,和大规模分布式数据存储快速发展有很大关系,当然数据存储的框架也比较多,不同的框架,功能不太一样,首先第一个:Hadoop HDFS,分布式文件系统,HDFS的诞生,解决了海量数据的存储问题, 但是一个优秀的数据存储系统需要同时考虑数据存储和访问两方面的问题,比如你希望能够对数据进行随机访问,这是传统的关系型数据库所擅长的,但却不是分布式文件系统所擅长的,那么有没有一种存储方案能够同时兼具分布式文件系统和关系型数据库的优点,基于这种需求,就产生了 HBase、MongoDB等。
数据处理:大数据最重要的环节就是数据处理了,数据处理通常分为两种:批处理和流处理。
- 批处理:对一段时间内海量的离线数据进行统一的处理,对应的处理框架有 Hadoop MapReduce、Spark、Flink 等;
- 流处理:对运动中的数据进行处理,即在接收数据的同时就对其进行处理,对应的处理框架有 Spark Streaming、Flink 等。
批处理和流处理各有其适用的场景,时间不敏感或者硬件资源有限,可以采用批处理;
时间敏感和及时性要求高就可以采用流处理。随着服务器硬件的价格越来越低和大家对及时性的要求越来越高,流处理越来越普遍,如股票价格预测和电商运营数据分析等。
大数据是一个非常完善的生态圈,有需求就有解决方案。为了能够让熟悉 SQL 的人员也能够进行数据处理与分析,查询分析框架应运而生,常用的有 Hive 、Spark SQL 、Flink SQL、Phoenix 等。这些框架都能够使用标准的 SQL 或者 类 SQL 语法灵活地进行数据的查询分析。
这些 SQL 经过解析优化后转换为对应的作业程序来运行,如 Hive 本质上就是将 SQL 转换为 MapReduce 或 Spark 作业,Phoenix 将 SQL 查询转换为一个或多个 HBase Scan。
大数据流处理中使用的比较多的另外一个框架是 Kafka,Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以用于消峰,避免在秒杀等场景下并发数据对流处理程序造成冲击。
数据应用:处理好的数据就可以输出应用了,如可视化展示,推动业务决策,用于推荐算法,机器学习等。
任务调度:复杂大数据处理的另外一个显著的问题是,如何调度多个复杂的并且彼此之间存在依赖关系的作业?基于这种需求,产生了 Azkaban 和 Oozie 等工作流调度框架。
同时针对集群资源管理的需求,又衍生了 Hadoop YARN,资源调度框架。
想要保证集群高可用,需要用到 ZooKeeper ,ZooKeeper 是最常用的分布式协调服务,它能够解决大多数集群问题,包括首领选举、失败恢复、元数据存储及其一致性保证。
以上,在分析大数据处理流程中,我们把常用的框架都说了下,基本上也是大数据中最常用的框架,尽量全部掌握。
以上框架大部分是用Java写的,有部分是用Scala写的,所以我们必须掌握的语言是Java、Scala,以便我们开发相关应用及阅读源码等。
总结
我们总结下重点框架:
- 语言:Java 和 Scala(语言以这两种为主,需要重点掌握)
- Linux(需要对Linux有一定的理解)
- Hadoop(需理解底层,能看懂源码)
- Hive(会使用,理解底层SQL转化原理及优化)
- Spark(能进行开发。对源码有了解)
- Kafka(会使用,理解底层原理)
- Flink(能进行开发。对源码有了解)
- HBase(理解底层原理)
- Zookeeper(会用,最好理解原理)
- Sqoop、Flume、Oozie/Azkaban(会用即可)
如果走数仓方向,需要掌握以下技能:
- 离线数仓建设(搭建数仓,数仓建模规范)
- 维度建模(建模方式常用的有范式建模和维度建模,重点关注维度建模)
- 实时数仓架构(两种数仓架构:Lambda架构和Kappa架构)
不管离线还是实时,重中之重就是:SQL。多找一些SQL题练习!
等工作之后,有时间还需要学习比较流行的 OLAP 查询引擎:
Impala 、Presto、Druid 、Kudu 、ClickHouse 、Doris
如果还有时间,需学习数据质量及数据治理相关的内容!
另还有元数据管理工具:Atlas
数据湖-Data Lake 三剑客:Delta、Hudi、Iceberg
2. 大数据就业方向
因为大数据涉及到的知识相对比较广泛,全部学精难度太大,所以现在企业在招聘的时候会细分大数据岗位,专注于某个方向招聘,所以先解下大数据的都有哪些就业方向,然后你在后续的学习过程中对哪部分比较感兴趣就重点关注那部分
从上帝视角看一张图,了解下大数据所处的位置及与相关岗位的关系

- 数仓工程师 (全称:数据仓库工程师)
数仓工程师日常工作一般是不写代码的,主要以写 SQL 为主!
数仓工程师是大数据领域公司招聘较多的岗位,薪资也较高,需要重点关注!
数据仓库分为离线数仓和实时数仓,但是企业在招聘时大多要求两者都会,进入公司之后可能会专注于离线或实时其中之一。
就目前来说,大多数的企业还是以离线数仓为主,不过未来趋势肯定是实时数仓为主,所以学习时,为了现在能找到工作,需要学习离线数仓,为了以后的发展,需要学习实时数仓。所以,离线和实时都是我们重点掌握的!
需要掌握的技能:
不管离线还是实时,重中之重就是:SQL
SQL 语法及调优一定要掌握,这里说的 SQL 包括 mysql 中的 sql,hive中的 hive sql,spark 中的 spark sql,flink 中 的 flink sql。
在企业招聘的笔记及面试中,一般问的关于 sql 的问题主要是以 hive sql 为主,所以请重点关注!
除 sql 外,还需要重点掌握以下技能,分为离线和实时
离线数仓需要重点掌握的技能:
- Hadoop(HDFS,MapReduce,YARN)
- Hive(重点,包括hive底层原理,hive SQL及调优)
- Spark(Spark 会用及了解底层原理)
- Oozie(调度工具,会用即可)
- 离线数仓建设(搭建数仓,数仓建模规范)
- 维度建模(建模方式常用的有范式建模和维度建模,重点关注维度建模)
实时数仓需要重点掌握的技能:
- Hadoop(这是大数据基础,不管离线和实时都必须掌握)
- Kafka(重点,大数据领域中算是唯一的消息队列)
- Flink(重中之重,这个不用说了,实时计算框架中绝对王者)
- HBase(会使用,了解底层原理)
- Druid(会用,了解底层原理)
- 实时数仓架构(两种数仓架构:Lambda架构和Kappa架构)
- 大数据开发工程师
数据开发工程师一般是以写代码为主,以 Java 和 Scala 为主。
大数据开发分两类,第一类是编写Hadoop、Spark、Flink 的应用程序,第二类是对大数据处理系统本身进行开发,如对开源框架的扩展开发,数据中台的开发等!
需要重点掌握的技能:
- 语言:Java 和 Scala(语言以这两种为主,需要重点掌握)
- Linux(需要对Linux有一定的理解)
- Hadoop(需理解底层,能看懂源码)
- Hive(会使用,能进行二次开发)
- Spark(能进行开发。对源码有了解)
- Kafka(会使用,理解底层原理)
- Flink(能进行开发。对源码有了解)
- HBase(理解底层原理)
通过以上技能,我们也能看出,数据开发和数仓开发的技能重复率较高,所以很多公司招聘时 大数据开发 和 数仓建设 分的没有这么细,数据开发包含了数仓的工作!
- ETL工程师
ETL是三个单词的首字母,中文意思是抽取、转换、加载
从开始的图中也能看出,ETL工程师是对接业务和数据的交接点,所以需要处理上下游的关系
对于上游,需要经常跟业务系统的人打交道,所以要对业务系统比较熟悉。比如它们存在各种接口,不管是API级别还是数据库接口,这都需要ETL工程师非常了解。
其次是其下游,这意味着你要跟许多数据开发工程师师、数据科学家打交道。比如将准备好的数据(数据的清洗、整理、融合),交给下游的数据开发和数据科学家。
需要重点掌握的技能
- 语言:Java/Python(会基础)
- Shell脚本(需要对shell较为熟悉)
- Linux(会用基本命令)
- Kettle(需要掌握)
- Sqoop(会用)
- Flume(会用)
- MySQL(熟悉)
- Hive(熟悉)
- HDFS(熟悉)
- Oozie(任务调度框架会用其中一个即可,其他如 azkaban,airflow)
- 数据分析工程师
在数据工程师准备好数据维护好数仓后,数据分析师就上场了。
分析师们会根据数据和业务情况,分析得出结论、制定业务策略或者建立模型,创造新的业务价值并支持业务高效运转。
同时数据分析师在后期还有数据爬虫、数据挖掘和算法工程师三个分支。
需要重点掌握的技能:
- 数学知识(数学知识是数据分析师的基础知识,需要掌握统计学、线性代数等课程)
- 编程语言(需要掌握Python、R语言)
- 分析工具(Excel是必须的,还需要掌握 Tableau 等可视化工具)
- 数据敏感性(对数据要有一定的敏感性,看见数据就能想到它的用处,能带来哪些价值)
3. 大数据面试
如果让我招大数据工程师,我第一看中的不是技术,而是你有没有独立思考的能力,给你一个你毫不熟悉的项目,能不能快速理清业务逻辑,能不能将需求完整的复述一遍,因为这太重要了,我司目前招进来两个大数据初级,不知道是跨行业的原因,还是其他,需求始终理解的差那么一点,也可能是我们的业务比较复杂。但是需求理解不到位,技术在厉害也是没用
但是话又说回来,需求这东西你没办法提前复习啊,只有需求来了才知道要干什么,所以面试时只能考察技术及你的过往项目经历,通过你之前做的项目看你对这个项目的理解情况,这主要看和面试官有没有眼缘,没有具体标准,因为每个人做的项目可能不一样,你项目中会的地方多说一点,不会的少说一点或者干脆不说,面试官感觉你说得好,你就有希望

但是技术是有标准的,问你某个技术点,你会就是会,不会就是不会
但是在学技术的时候要多思考,这个技术点为什么这样实现,有什么好处,多思考会让大脑越来越灵活,就比如Flink支持精准一次处理语义,但是大家深入思考下flink的精准处理是怎么实现的,有人说是通过两阶段提交协议实现的,对,是通过这个协议,那再深入思考下,这个协议的主要内容是什么,底层的算法是怎么实现的,这样一步步的向下思考,你就会发现一个新世界。
以上说这么多,其实就两点,面试主要考察技术和项目。项目也是非常重要的,通过项目一方面可以考察你的技术掌握情况,另一方面考察你对项目的理解情况,如果你连自己简历中的项目都不太熟悉,说的磕磕绊绊,那么你进到公司后,怎么能短时间内快速熟悉业务呢。
所以,简历中一定要写项目,并且对项目要非常熟悉!
五分钟学大数据公众号对话框发送:面试,会有一份带解析的超全大数据面试题!
4. 大数据简历
对于许多应届生来说,有不少是带着学生思维来撰写简历,不仅于求职加分无益,还给自己挖了许多坑。败在简历关,等于一场马拉松摔输在了起跑线,还没开始就结束了。
简历的大忌:
- 海投简历
不要一份简历原封不动地发送给数十家企业。这样的结果往往是石沉大海。
求职讲求“人岗匹配”,即面试者个人素质与职位要求高度一致。要针对岗位要求适当修改简历,提升岗位匹配度。
- 简历毫无重点
一篇优秀的简历,应该是懂得“舍弃”的简历。你不需要将自己大学几年来所有的事件经历都罗列上去,而是应该根据企业和岗位的需求进行取舍,选取出最匹配的经历大篇幅呈现出来,其他经历大可一笔带过甚至干脆不谈。
简历怎么写:
重点来啦!!!
写简历一定要用四大原则和STAR法则!
什么是四大原则,什么是STAR法则,接下来我们就逐项解析:
四大原则:
- 关键词原则
关键词原则指的是,多使用一些行业术语或专业词汇放入你的经历描述中,凸显出你的专业性以及对该行业的熟悉程度。
- 动词原则
动词是一个句子的灵魂所在,也是面试官判断你的个人经历是否真实的重要标准之一。在经历描述中,要着重注意动词的挑选,最准确的动词才能够传达出你的经历价值。
比如表明自己行为的动词“从事”“积累”“得到”,似乎是所有工作中都用得到,但根本看不出这份经历的独特性。
为了展现你的经历真实与价值,足够专业化的动词才是加分项。
- 数字原则
多用数字其实是简历很好的加分项,数字的意义是将你的经历量化。丰富的数字比华丽的形容词要更有说服力。
数字一般可以用于三种维度:价值,时间,数量。
牢记,能够量化的内容都量化,用数据展现你丰厚的经历。
- 结果原则
许多同学在经历描述时会忽略自己经历的最终成果,但结果是证明你经历价值的重要依据之一。
STAR法则
Situation 项目背景
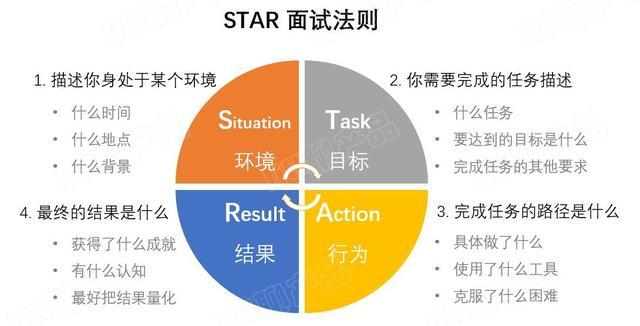
介绍一下你所处的平台和团队有多优秀,以证明你曾经的被认可程度。
Task 项目目标
介绍一下你们此项活动的具体目标与设想,有时可以和上一部分进行合并。
Action 你做了什么
说明你在团队中做出了怎样的努力,充当了怎样的角色,发挥了什么样的作用,以此展现你的个人实力和在团队中的成长与历练。这一部分往往是最重要的。
Result 得到怎样的结果
说明你最终取得了怎样的工作成果,表述时可以参照上部分的“四大原则”。
五分钟学大数据公众号对话框发送:简历,会有几十份大数据简历模板供你参考!
最后给大家一些高逼格的关键词和动词,仅供娱乐:

注:以下词语简历及面试时可以用,但是别太过!
高逼格名词:生命周期,价值转化,强化认知,资源倾斜,完善逻辑,抽离透传,复用打法,商业模式,快速响应,定性定量,关键路径,去中心化,结果导向,垂直领域,归因分析,体验度量,信息屏障,资源整合
高逼格动词:复盘,赋能,加持,沉淀,倒逼,落地,串联,协同,反哺,兼容,包装,重组,履约,响应,量化,布局,联动,细分,梳理,输出,加速,共建,支撑,融合,聚合,集成,对标,聚焦,抓手,拆解,抽象,摸索,提炼,打通,打透,吃透,迁移,分发,分装,辐射,围绕,复用,渗透,扩展,开拓,皮实,共创,共建,解耦,集成,对齐,拉齐,对焦,给到,拿到,死磕
你们对这些词有什么看法呢。

最后,来一个面试官的死亡提问:
你这个问题的底层逻辑是什么?顶层设计在哪?最终交付价值是什么?过程的抓手在哪?如何保证回答闭环?你比别人的亮点在哪?优势在哪?你的思考和沉淀是什么?这个问题换成我来问是否会不一样?你的独特价值在哪?

讨论
你是因为什么原因而从事大数据工作呢,因为大学学的这个专业?大数据比较热门而学?大数据工资高转行学?欢迎在评论区留下你的留言!






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。