
Looking back, starting from best practices
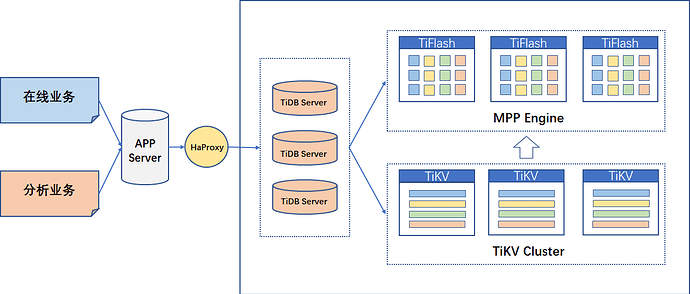
As an HTAP database, TiDB can process OLTP online services and OLAP analysis services from the user side at the same time. For analysis requirements, the optimizer will automatically route the request to the TiFlash node in the column; for online requests, the optimizer will automatically route the request to the TiKV in the row. For the HTAP database, we are most concerned about whether the analytical queries that take up a lot of resources will affect the online OLTP business. In response to this problem, TiDB isolates TiKV and TiFlash at the physical layer, which avoids this problem. Condition.
Reflection, the pain of best practice structure
By means of resource isolation, we have resolved the mutual influence between businesses. However, in order to achieve more flexible and efficient applications, there are still certain problems in the above architecture:
- HAProxy does not have high-availability features for the time being
- For TiDB Server, there is no isolation between TP business and AP business
For the above two problems, we can use the following two solutions to avoid the above risks.
HAProxy's high-availability solution
In a production environment, we generally do not use HaProxy alone as DNSRoundRobin. Any single-point non-high availability structure will lead to the unavailability of the system. HaProxy itself is a stateless service. For stateless services, we can use multiple services to avoid the availability risk of a single node. In addition, on top of HaProxy, we can use Keepalived's detection script to float VIP to an available node to complete a single-entry high-availability structure.

TP and AP isolation scheme
In the HTAP scenario, we have isolated OLTP and OLAP query requests by storing data on TiKV and TiFlash at the physical level, truly achieving storage engine-level isolation. On the computing engine, the isolation-read parameter can also be set at the TiDB instance level to achieve engine isolation. Configure the isolation-read variable to specify that all queries use a copy of the specified engine. The optional engine is "TiKV", "TiDB" and "TiFlash" (where "TiDB" represents the internal memory table area of TiDB, which is mainly used to store some TiDB system tables, users cannot actively use them).
Regardless of whether the front end is highly available for HAProxy, HAProxy cannot determine what the isolation-read engine isolation mechanism of TiDB Server is when it comes to roundrobin endpoints. This may cause an awkward situation. HAProxy may route the OLTP query request to the node with isolation-read set to TiFlash, making it impossible for us to process the request in the best posture. In other words, some of the analytical queries that we force to use hint to use TiFlash may be routed to the node with isolation-read set to TiKV, and the SQL request throws an exception.
Starting from the functional point, we need to redefine the HTAP database:
- I hope that the storage layer data is separated, and the OLTP and OLAP businesses do not affect each other
- I hope that the requests of the computing layer are separated, and the OLTP and OLAP requests do not affect each other
Change, demand-driven architecture transformation
Retrofit based on HAProxy
In order to solve the routing of TiDB Server in the computing layer, we can use two sets of HAProxy to physically distinguish the TiDB Server cluster. One set of HAProxy cluster is used to manage TiDB Server whose isolation-read is TiKV, and the other set of HAProxy cluster is used to manage TiDB Server whose isolation-read is Tiflash. For high availability considerations, we still need to make high availability on the HaProxy cluster. In this way, the following architecture can be abstracted:
From the perspective of the overall architecture, such a set of architecture design basically meets our needs. The computing layer TiDB Server is physically isolated, and the front-end Proxy is also highly available. However, such a structure is still flawed:

- The structure is relatively complex, so that in order to ensure the high availability of the system, the relative physical node cost is relatively high
- The export of Proxy is not uniform, two sets of Keepalived are required to maintain two VIPs, and coding operations are required in the business logic
If such a structure is adopted, from the perspective of cost reduction, we can mix nodes. We can consider deploying two sets of keepalived clusters on a set of three-node machines, which are physically isolated by virtual_router_id. Or directly deploy a set of keepalived cluster, instead of using the VIP that comes with keepalived, deploy two sets of vrrp scripts in a set of keepalived, and maintain independent VIPs in their respective detection scripts. HAProxy we can also use keepalived machines for deployment, and make a set of 2 (3 Keepalived + 3 * Haproxy) structure. Such an improved cluster architecture can reduce the machine cost to the same level as maintaining a normal cluster, but it still cannot reduce the complexity of the architecture, nor can it change the invariance brought about by the two entrances.
Use ProxySQL to implement SQL routing
Looking at it now, what we need is a TP/AP separated Proxy. From the demand point of view, it matches MySQL's read-write separation, or to be clear, our demand is that we need a SQL routing tool.
Presumably, students who have been in contact with MySQL will know about ProxySQL. ProxySQL is an open source middleware product based on MySQL and a flexible MySQL proxy tool. As a powerful rule engine middleware, ProxySQL provides us with many features:
- Flexible and powerful SQL routing rules can load SQL requests intelligently.
- Stateless service, convenient high-availability management solution.
- Automatically perceive the monitoring status of nodes, and quickly eliminate abnormal nodes.
- Convenient SQL monitoring, analysis and statistics.
- The configuration library is based on SQLite storage, and the configuration can be modified online and loaded dynamically.
- Compared with MySQL query cache, it has a more flexible cache function, which can cache multi-dimensional control statements in the configuration table.
In my opinion, ProxySQL is a product that is so powerful that there are no extra features. Each of its features can actually hit the pain points of users and meet their needs. If there are any shortcomings, all I can think of is the performance degradation caused by the routing function, but such degradation still exists in other proxy tools or even worse.
As a "large size" MySQL, can TiDB fit ProxySQL well? The answer is yes. We can simply replicate ProxySQL's MySQL read-write separation solution to perform TP/AP SQL request routing operations. Even speaking, the various powerful functions introduced above are still applicable in TiDB, and to some extent, they make up for the deficiencies of the TiDB ecosystem.

Full link high availability
For a database system, any link may become a point of failure, so no service can exist in the form of a single point. Any component of TiDB Cluster is highly available and scalable. ProxySQL can also configure highly available clusters. For the high availability of ProxySQL, there are currently two popular solutions:
- Multiple independent ProxySQL
- Highly available cluster using ProxySQL
ProxySQL itself is a stateless service, so multiple independent ProxySQL on the front end itself is a guarantee of availability. However, because multiple ProxySQL are independent, related configuration files cannot be interconnected. Changes to any configuration cannot be automatically synchronized, which is risky for management. If the cluster version of ProxySQL is highly available, the watchdog process in order to ensure the cluster status may itself be a load to the cluster.
As in the previous section, for a set of clusters, we expect to have an entrance. The front-end ProxySQL itself has multiple entries. We can use Keepalived + haproxy to balance the load of an endpoint, or worry about the large performance degradation caused by multi-level proxy (HAProxy + ProxySQL), we can maintain Keepalived's probing script to control VIP. For companies with stricter network supervision, the VRRP protocol may be closed, then you can choose Zookeeper service registration and discovery to maintain the state of ProxySQL, and manage the VIP of the cluster in Zookeeper.
Each company has its own solution architecture for a unified entry high-availability solution for multiple endpoints. As far as I am concerned, compared to Keepalived + HAProxy or load balancing in Keepalived scripts, I prefer to use zookeeper to manage the state of the cluster. We need to carefully plan Keepalived's scoring system. In order to reduce the performance degradation of HAProxy, we may need to manage another set of VIPs in the script or close the Keepalived service on the failed node. Of course, what scheme to use must be matched with our own technology stack, and only what suits us is the best practice.
In the above architecture, TP and AP requests are connected to the back-end TiDB Cluster through the APP program. As the only entrance to the program, Keepalived's probing program will select an available ProxySQL and create a VIP on it. This VIP will serve as the only entry point for the application to interface with TiDB Cluster. In the ProxySQL cluster, according to the pattern configuration of TP and AP configured in the Router Table (mysql_query_rules), the query request between TP and AP is automatically routed in the configured TP_GROUP and AP_GROUP.
In summary, such an architecture can solve our previous pain points:

- The application and the database cluster use a unique interface.
- Simple high-availability structure, through a set of keepalived and a set of Proxy clusters to achieve high availability.
- TP/AP requests can be automatically routed to the corresponding computing node TiDB Server.
Practice, seek results from cases
A demo system was deployed to simply show the running process and results of the entire architecture.
The following is a list of components on the node:

Install TiDB
Slightly, please refer to the official document (TiDB database quick start guide).
Install ProxySQL
You can choose to install ProxySQL using rpm. But in order to unify the installation location, I usually use the source code to compile and install, and then use rpmbuild to mark the installation package and deploy it to other nodes. For compilation and installation, please refer to the INSTALL.md document.
Modify the proxy.cfg file, modify datadir="/opt/tidb-c1/proxysql-6033/data".
Use the following command to start ProxySQL, or configure the systemd file to start.
/opt/tidb-c1/proxysql-6033/proxysql -c /opt/tidb-c1/proxysql-6033/proxysql.cfg
Configure ProxySQL
Since in this example, I used three independent ProxySQL for high-availability load, I need to do the same configuration on these three machines. If you choose the high availability that comes with ProxySQL, you only need to configure it on one machine.
[root@r31 proxysql-6033]# mysql -uadmin -padmin -h127.0.0.1 -P6032 --prompt 'admin>'## set server infoinsert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.232.31',14000);insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.232.32',14000);insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.232.33',14000);insert into mysql_servers(hostgroup_id,hostname,port) values(20,'192.168.232.34',14000);insert into mysql_servers(hostgroup_id,hostname,port) values(20,'192.168.232.35',14000);load mysql servers to runtime;save mysql servers to disk;## set userinsert into mysql_users(username,password,default_hostgroup) values('root','mysql',10);load mysql users to runtime;save mysql users to disk;## set monitoring userset mysql-monitor_username='monitor';set mysql-monitor_password='monitor';load mysql variables to runtime;save mysql variables to disk;## set sql router rule## this is just a demoinsert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)values(1,1,'^select.*tikv.*',10,1),(2,1,'^select.*tiflash.*',20,1);load mysql query rules to runtime;save mysql query rules to disk;Configure Keepalived
The installation of Keepalived refers to keeaplived-install, which is the same as the installation of ProxySQL. It is recommended to compile and install the rpm package or directly copy the keepalived binary.
The configuration file script of Keepalived is as follows:
global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0}vrrp_script check_proxysql { script 'killall -0 proxysql || systemctl stop keepalived' interval 2 weight 10}vrrp_script test_script { script 'echo `date` >> /tmp/aaa' interval 1 weight 1}vrrp_instance proxysql_kp { state MASTER interface ens33 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1888 } virtual_ipaddress { 192.168.232.88 } track_script{ check_proxysql ##test_script }}Verify ProxySQL
I opened the general log on five TiDB Servers to record SQL statements.
Two tables are created in TiDB Cluster:
- test.t_tikv(idi int), data from 1-1000
- test.t_tiflash(idi int), data from 1-1000
Use a simple loop to perform stress testing at the front end:
for i in `seq 1000`; do mysql -uroot -P6033 -h192.168.232.88 -pmysql -e "select * from test.t_tikv where idi = $i"; donefor i in `seq 1000`; do mysql -uroot -P6033 -h192.168.232.88 -pmysql -e "select * from test.t_tiflash where idi = $i"; doneTiDB Server log filters the number of keywords "select * from test.t_tikv where idi =". It can be seen that according to the TiKV SQL configured in the routing table, 1,000 more scattered routes are routed to TiDB-1, TiDB-2, and TiDB-3 nodes.

Easter egg, the audit function you want
Database auditing is a system for monitoring database access behavior. It can provide a basis for determining the responsibilities of an incident after a database security incident occurs. The audit log is extracted into the real-time data warehouse for risk control processing, which can detect risks in time and recover losses to the greatest extent. Audit logs are very important in some important financial and order trading systems.
How to capture audit log
Like many users now, I have encountered the need for audit. Many open source databases like MongoDB do not provide free audit functions. The audit function is particularly important for many financial scenarios. In order to complete the audit function, we usually have two ways:
- Parse semantics in source code
- Data flow collection
The so-called source code semantic analysis is actually the function of manually adding audit to the source code. We can modify the source code and place some of the variable information we want to capture into a local file. But this method may cause a lot of waiting and affect the performance of the database. By performing this write operation asynchronously, the performance degradation can be slightly alleviated.
Another method of data flow collection is slightly better than that of variable placing. The idea of traffic monitoring is to build a bypass system that is relatively independent of the database, intercept the traffic through tools such as packet capture or probes, and print the database-specific requests to a local file. This method itself is not linked to the database, and the audit log is obtained asynchronously.
Capture audit log in TiDB
At present, there are two main types of auditing on TiDB. One is to purchase the audit plug-in provided by the original manufacturer, and the other is to enable the General log function. You can view the SQL statement in the TiDB log. It should be noted that since we use HAProxy on the front end, we need to configure the forwardfor parameter to capture the client's IP. The General log will record all requests including select in the TiDB log. According to previous tests, there will be a performance loss of about 10%-20%. The recorded SQL statements including time or IP and other information may not meet our needs, and sorting out the audit from the TiDB log is also a relatively large project.
Obtain audit log in ProxySQL
The needs of Audit are very common. For example, MongoDB, the community version of open source database does not provide audit function is also more common. From the perspective of the entire link, there are two nodes that can obtain a complete audit, one is the database side, and the other is the proxy side. ProxySQL can provide us with an audit function. When we specify the MySQL_enventslog_filename parameter, we set to enable the audit function. In the audit file, we can capture all the SQL audit of the ProxySQL entry.
In my environment, the audit log in the following format can be captured, which basically meets most of the needs of users:
Interception of audit by probe
You can make a probe through systemtap and hang it on proxySQL. According to some ProxySQL keywords, for example, run, execute, query, init, parse, MySQL, connection, etc., try to trace the call stack and parameters of these functions. By printing these parameters, you can get the IP and Statement when processing the request. If these functions cannot track the audit information, you can consider using brute force to track all the functions of ProxySQL (match by function("*")). Navigate to the specified function based on the result. But this method requires a more powerful server during development.
Currently, the audit logs that can be tracked through Unreal are as follows:
>>>>>>>>>>>>>>>>>>>[ function >> ZN10Query_Info25query_parser_command_typeEv ] [ time >> 1622953221 ] this={.QueryParserArgs={.buf="select ?", .digest=2164311325566300770, .digest_total=17115818073721422293, .digest_text="select ?", .first_comment=0x0, .query_prefix=0x0}, .sess=0x7f1961a3a300, .QueryPointer="select 1113 192.168.232.36", .start_time=2329486915, .end_time=2329486535, .mysql_stmt=0x0, .stmt_meta=0x0, .stmt_global_id=0, .stmt_info=0x0, .QueryLength=11, .MyComQueryCmd=54, .bool_is_select_NOT_for_update=0, .bool_is_select_NOT_for_update_computed=0, .have_affected_rows=0, .affected_rows=0, .rows_s ######The query point can be captured, the text of the query, the user's client IP, and the function name and time can be directly written in the background through the script of systemtap.
The use of plug-in probes can greatly reduce the waiting of Proxy or Database to write logs, thereby minimizing the impact on database performance, and basically neglecting the performance loss caused by auditing.







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。