
This article is written by Ctrip's technical team and introduces Ctrip's self-developed real-time label processing platform for international business dynamics. Among them, the tag persistence scenario needs to solve the persistent storage, update, and query services of business tags. TiDB meets the needs of different business scenarios to access business feature data by supporting the query features of different scenarios.
about the author
Weiyi, a senior data developer at Ctrip, pays attention to big data-related technologies, and has a strong interest in big data real-time computing and stream batch integration;
Hzhou, Ctrip is a senior data developer, pays attention to big data related technologies, and has a strong interest in system architecture and real-time processing;
Rongjun, Ctrip's big data architecture development, focuses on offline and real-time big data products and technologies.
background
In the international business, because of the many markets faced, the complex and diverse products and businesses, the many launch channels, and the high drainage costs, more refined management and optimization of businesses and products are required to meet the needs of market launch and operation and reduce costs , Improve operational efficiency and increase conversion rate. For this reason, we propose to develop a dynamic real-time label processing platform for Ctrip's international business (hereinafter referred to as CDP) to solve the problems of "Grow Revenue" and "Reduce Costs" for Trip business growth, as shown in Figure 1-1.
Figure 1-1 The business problems that CDP needs to solve
Because Trip data sources are relatively wide, both own data and external data; data forms are also very diverse, including structured data, semi-structured and unstructured data; data processing forms include offline data processing and online data Processing; how to process these data through the system to form understandable data and labels for business systems, operations, and markets has become an urgent business and system problem for the CDP platform. Simply sum up, the system mainly needs to solve the following four problems:
Data collection and management

Mainly enrich different data sources, including three parts. The first party data comes from itself, UBT logs, platform data, customer service processing data, and APP installation data. Second-party data, data from other brands in the group, such as SC, Travix, etc. Third-party data comes from the websites of our partners, such as meta delivery platforms.
ID match
Different data sources have different ID tags. For example, the data from the APP side will have a unified ClientID primary key, and there will be a set of tags associated with it. Data from different business systems will have corresponding IDs and tags corresponding to them. The IDs of these tag bodies are derived from different systems and platforms. Some of the IDs between platforms may not have an association relationship with each other, and some have a certain association relationship, but they are not one-to-one correspondence, but business systems often need to be combined with each other when used. Therefore, it is necessary to have an ID that can be connected in series from data collection to service label creation to final use. This is the biggest difficulty. If not, then we need a very complete ID Mapping, which can be converted between different IDs, so that users can concatenate tags between different entities.
Business labeling model
Some tags are used for scenario decision-making, such as the most popular products in the market, the most popular tourist destinations, and so on. Many companies wanted everything when they made labels in the early days, and they laid hundreds of statistical labels, but these labels cannot be used directly. Moreover, when hundreds of labels are smashed at the product or operation personnel, because there is no focus, the business personnel will be "smashed" at once. Therefore, it is important to provide a truly effective label. In this process, the understanding of the business becomes particularly important, and the system needs to establish a corresponding business label model according to the business scenario.
Use of labels
Do docking with systems that use tags, such as messaging systems, third-party platforms, and internal platforms. Let these business labels maximize to help the business generate performance. The difficulty is how does CDP connect with the platform that uses it.
To solve the above problems, the system must improve its data processing capabilities, because the processed data needs to be immediately applied to the business system, EMD, PUSH, etc. use scenarios, to the timeliness, accuracy, stability and flexibility of the data processing system Sexuality puts forward higher requirements.
In the past, our existing CRM data was calculated through the data warehouse T+1 and imported into the ES cluster storage. The front-end passed in the query conditions and assembled the ES query conditions to query the eligible data. There are currently hundreds of tags that are online, and more than 50% of them are used for queries, which can meet the needs of some tag data screening scenarios that do not require high data timeliness, such as the selection of target users for marketing activities. Because it is offline calculation, the data timeliness is poor, relying on the calculation of the underlying offline platform, and the index of the ES, the query response speed is relatively slow.
Based on the above problems, the new system hopes to improve the timeliness of data processing while meeting the requirements of business flexibility during data processing. For data processing logic and data update logic, message data can be consumed through dynamic system configuration rules ( Kafka or QMQ) dynamically update tags, the business layer only needs to care about the logic of data filtering and conditional queries.
2. System design
Based on business needs, we divide the scenarios of business data label filtering into two categories:
Trigger scenes in real time
According to business needs, configure dynamic rules, subscribe to the change messages of the business system in real time, filter out the data that meets the conditions of the dynamic rules, and push it to downstream business parties through messages.
Tag persistence scenario
The real-time business change messages of the business system are processed according to business needs into business-related feature data and stored persistently in the storage engine. The business assembles query conditions according to needs to query engine data, mainly OLAP (analysis) and OLTP (online query). Class query.
In order to solve the above problems, we have designed and developed a set of "real-time dynamic label processing system". The business side only needs to configure the submission task according to the basic operator rules, and the system will automatically interpret the execution rules and perform data processing operations according to the configuration requirements. Currently, it supports The basic operators include Stream (streaming data access currently supports QMQ and Kafka), Priority (priority judgment), Join, Filter (filtering), Sink (data output, currently supports TiDB, Redis, QMQ), etc. It will be introduced in detail in the overall design to improve data processing and development efficiency and reduce development costs through rules and dynamic calculations.
Streaming data adopts Kappa-like architecture, label persistence adopts Lambda-like architecture, and the system architecture is like
Figure 2-1.
Figure 2-1 CDP system architecture
The output of the system to the company is mainly the self-operated channels in the docking station, such as the messaging system, sending short messages, mailboxes, and advertisements. The main process in the station assembles the front-end business process according to the characteristics of CDP.
Three, real-time trigger

For dynamically triggered scenarios, it is necessary to solve dynamic rule configuration, rule analysis, the generation of dynamic calculation nodes (operators, hereinafter referred to as operators) within the rules, the interdependence of operators (DAG), and the processing of data joins.
In order to solve real-time streaming data processing, we introduced a data processing method similar to the Kappa architecture, made some adjustments, and adopted the active Push method, because the data in this scenario is mainly applied to active touch scenarios such as Push/EDM. As a result The data does not need to land, we directly push it to the message queue subscribed to by the application through the QMQ message channel.
Figure 3-1 Kappa data processing architecture
This solves the problem of timeliness of messages and also solves the problem of timeliness of rules. Modifying rules can take effect without restarting the task. The calculation results are actively pushed, which saves the process of data storage and query, improves the timeliness of data, and saves storage space.
Figure 3-2 CDP real-time trigger data processing architecture
The rule engine design adopts Json format to transfer parameters, the operator is designed in two layers, the upper layer is a dynamic business operator supported by fixed business logic, mainly including Stream, Priority, Join, Filter, Sink, and the lower layer is some basics used by fixed business operators. Operators can be freely combined to meet the needs of real-time message processing business logic processing.
Some basic concepts involved in the rule engine are described as follows:
Stream

Message source access, mainly Kafka and QMQ, structured Json data. The data structure, data type, and source of all access message sources need to be entered and managed, and the company’s Kafka and QMQ message registration management mechanism is borrowed to realize the whole process. .
Priority
Priority judgment, for example, the main process is generally arranged in the order of search page, list page, fill-in page, and payment page. Because the traffic is reduced one by one, the traffic is more important as it goes. In some business scenarios, it needs to be based on these traffic. The order of importance and priority judgment can meet the needs of these business scenarios.
Join
Join operator, currently only supports using Redis as the Join right table. If the Join conditions are not met, the data in the right table is NULL, and the left table data is output by default. If you need the right table data, you need to specify the output field.
Filter
The filter operator can directly filter the upstream data, or filter the upstream data and the data after Redis Join. Only the passed data will flow into the following operator, otherwise the processing of this piece of data will end.
Sink
The output of calculation results supports configuration mode, currently supports message queue mode (QMQ), database (TiDB, MySQL, etc.).
Basic operator
Basic atomic operators cannot be split, such as +, -, *, /, >, <, =, >=, <= and in, not in, like, rlike, IS_NULL, IS_NOT_NULL, etc.
Custom function
Supports the use of custom functions in the calculation process. Users can customize data processing functions and register them in the production system. The currently supported functions are as follows:
String functions: CONCAT, CONCAT_WS, HASH, IFNULL, IS_NOT_BLANK, IS_NOT_NULL, IS_NULL, LIKE, LOWER, UPPER, REGEXP, REPLACE, SUBSTR, UPPER, URL_EXTRACT_PARAMETER, etc.
Time function: CURRENT_TIMESTAMP, FROM_UNIXTIME
JSON function: JSON_EXTRACT
DAG
DAG is a kind of "graph", the application of graph computing model has a long history, as early as the last century, it was applied to the realization of database system (Graph databases). Any graph contains two basic elements: nodes (Vertex) and edges (Edge). Nodes are usually used to represent entities, while edges represent relationships between entities.
Since DAG calculation is a very complex system, we mainly draw on Spark’s DAG calculation idea to simplify the DAG calculation process to meet the needs of our real-time computing business scenarios. Before introducing the DAG calculation method, let’s introduce DAG calculation in Spark. Basic ideas and concepts.
In Spark, DAG is an abstraction of the distributed computing model, which is called Lineage in the technical term-descent. RDD forms an end-to-end computing path through dependencies and compute attributes.
Dependencies are divided into two categories, Narrow Dependencies and Wide Dependencies (Figure 3-3).
Narrow Dependencies means that each partition of the parent RDD can be used by at most one partition of the child RDD, which means that a partition of a parent RDD corresponds to a partition of a child RDD or multiple partitions of a parent RDD correspond to a partition of a child RDD, that is It is said that a partition of a parent RDD cannot correspond to multiple partitions of a child RDD.
Wide Dependencies means that the partition of the child RDD depends on multiple partitions or all partitions of the parent RDD, which means that there is a partition of a parent RDD corresponding to multiple partitions of a child RDD. Shuffle is required in Spark, which Spark calls Shuffle Dependency, as the basis for stage division.
Figure 3-3 Narrow Dependencies and Wide Dependencies
In Spark, the stage division method is calculated from the back to the front. When it encounters ShuffleDependency, it will be disconnected, and when it encounters NarrowDependency, it will be added to the stage. The number of tasks in each stage is determined by the number of partitions in the last RDD of the stage. As shown in Figure 3-4.
Figure 3-4 Division of Spark Stage
RDD operators in Spark are divided into two categories:
Transformations: data transformation, such as map, filter, flatMap, join, groupByKey, reduceByKey, sortByKey, repartition, etc., this type of operator uses lazy evaluation, that is, the transformation operation does not start before the real calculation, only in Spark will actually start the calculation when the Action operation is executed. The conversion operation will not be executed immediately, but the relevant information of the operation to be executed is recorded internally and executed when necessary.
Actions: Data materialization operations, calculation triggers, such as collect, count, foreach, first, saveAsHadoopFile, etc.
Each Stage contains a set of TaskSets, and data is transferred between Tasks in the way of Pipeline.
According to the needs of business label data processing, and borrowing from Spark's ideas, CDP has simplified the DAG calculations, as follows:
In CDP's DAG, the division of DAG is directly calculated from the front to the back, and there is no need to split the stage. All DAG Tasks are in the same stage (All in one Stage) as shown in Figure 3-5, and are concurrently scalable , No need for DAGScheduler.
Operators are divided into two categories in CDP:
Operator: Data processing operation operators, such as Stream, Priority, Join, Filter, and Sink, are configured by basic atomic operators. This type of operator uses agerevaluation (early evaluation), that is, the Operator will start as soon as the data enters. Trigger data processing operations, so there is no need to cache state data, which can effectively improve data processing efficiency.
Edge: Describe the relationship between Operators, that is, the topological relationship.
Figure 3-5 CDP All in one Stage
Fourth, label persistence



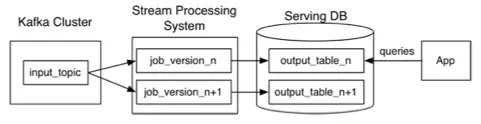
The scenario of label persistence needs to solve the persistent storage, update, and query services of business labels, use distributed high-availability relational database (TiDB) to store business persistent labels, and use real-time triggering of dynamic rule configuration in the scene to consume business System data change messages are processed using the real-time trigger method mentioned in the third section of this article to update the persistent label storage data to ensure the timeliness of business persistent labels, and query features for different scenarios through TiDB (mainly OLAP and OLTP) Support to meet the needs of different business scenarios to access business feature data.
In order to solve the needs of label persistence scenarios, drawing on the idea of Lambda data processing architecture, the new data is sent to different channels according to different sources. The full amount of historical data is converted through a data batch processing engine (such as Spark) and then written in batches. To the data persistence storage engine (TiDB). Incremental data business applications are sent to Kafka or QMQ message queues in the form of messages. Through the real-time data processing method mentioned in the real-time trigger scenario in Section 3 of this article, the data is incrementally written after the data is processed according to the logic rules of tag persistence. To the persistent storage engine (TiDB), this solves the problem of timeliness of data.
TiDB has two major persistent storage methods, one is TiKV in Row mode, which supports real-time online query scenarios (OLTP) better, and TiFlash in Column mode, which supports better analytical query scenarios (OLAP). TiDB data storage automatically solves the data synchronization problem of these two engines internally, and the client query selects the query method according to its own needs.
Figure 4-1 Lambda architecture
Figure 4-2 CDP persistence process
There are two main scenarios for accessing persistent tags. One is to connect with the existing CRM system, and select eligible business data online based on the characteristics of the business. The query conditions in this scenario are not fixed, and the returned result set depends on the filter conditions. , The data storage engine has relatively high requirements for data calculation and processing capabilities, that is, the OLAP scenario that we often mention in the field of data processing. Another scenario is that the online business queries whether it meets the specific business requirements based on the unique identifier related to the business label passed in from the front end, or returns the specified characteristic value to meet the needs of business processing, and requires a ms-level response, which corresponds to the OLTP scenario.
Five, business applications


5.1 Real-time trigger scenario application
In many business scenarios of Trip, it is necessary to clean, integrate, calculate and process multiple business input data before applying feedback to the business scenarios to promote business growth. For example, some of the trip product lines promoted return visits, promoted first orders, promoted repurchase, coupon expiration, APP new user contact, and other scenarios such as App Push and Email mail marketing and messaging, which improved the exposure and conversion efficiency of Trip products.
Take a Trip product to promote a return visit to the APP Push push message as an example, the process from page browsing behavior to triggering sending can be divided into several parts:
1) Browsing behavior occurs;
2) CDP obtains and processes target behavior log data in real time and sends it to the sending channel;
3) The sending channel completes the pre-sending processing of the message;
4) Send different content messages according to different browsing behaviors for the product.
According to the business needs of the product in real-time promotion scenarios, and the operators supported by CDP's real-time trigger scenarios, filter tasks are configured to dynamically filter out the data required by the product in the promotion scenarios, and different tags are labeled according to different browsing depths, and the push channel is based on the depth The label pushes different content to different clients. The specific CDP configuration operator business logic is shown in Figure 5-2.
Figure 5-2 Logic diagram of triggering a return visit for a certain Trip product of CDP
Through CDP to trigger scene configuration in real time, the system can dynamically generate tasks according to the configuration, without additional code development, and the configuration can be dynamically modified and take effect dynamically, without compiling and restarting tasks. At present, this method is more time-efficient, more flexible, and more stable from the perspective of operating effects, and has lower development and test costs. It does not need to go through the process of code development, compilation, testing, and release.
5.2 Tag persistence

In the first section, we mentioned that data from different business systems will have corresponding IDs and tags. We will persist these tags while establishing the mapping relationship between these IDs according to business needs. If it is a one-to-one mapping We will directly store the Mapping relationship. If it is a many-to-many relationship, we will implement the ID Mapping relationship according to the first, latest, all mapping relationship, etc. according to business needs, so that users can concatenate the characteristics of different IDs when filtering.
At present, CDP has launched the business feature tag library after real-time cleaning, conversion and integration of the business system related to Ctrip's international business. The system provides related data query and calculation services through API. At present, CDP is deeply integrated with Trip's various business systems to provide data and service support for the business feature tag library for international business growth.







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。