
Editor's note
This article was written by Hu Panpan, the head of WeBank's database, and introduced WeBank's architecture evolution from traditional RDBMS to NewSQL since 2014, and the application of TiDB in WeBank's core batch scenarios.
In a blink of an eye, he has been working in Weizhong for nearly seven years. During this period, he has been responsible for the construction and operation of the database platform of WeBank. At the beginning of the establishment of WeBank, the IT infrastructure did not choose the traditional IOE centralized architecture route, but instead chose to adopt a unit-based distributed architecture. Against this background, the evolution of WeBank's database structure has also taken an unusual route.
1. 2014 ~ 2016, the era of two places and three centers
In the first phase of WeBank’s IT construction, based on cost and efficiency considerations, the construction of IDC adopted a two-location three-center architecture (referred to as IDC 1.0 architecture). Two data centers in the same city serve as production centers, and one remote disaster recovery center serves as disaster recovery.
IDC 1.0 architecture

On the basis of IDC 1.0 architecture, our bank designed a unitized distributed architecture based on DCN (DCN, the abbreviation of Data Center Node). A DCN can be understood as a complete self-contained logical unit from the application layer to the middleware layer to the database layer.
Different business products are classified into different types of product DCN; the same business product is allocated to each small DCN product unit through certain calculation rules (such as the hash of the customer number); each DCN unit has An approved user carrying capacity; when the user carrying capacity of a DCN is used up, a new DCN unit expansion can be initiated to achieve horizontal expansion.
In the actual two-site three-center deployment architecture, each DCN will have three roles: same-city master DCN, same-city backup DCN, and remote backup DCN. That is, each DCN also implements a two-site three-center architecture. At the same time, different DCN main shards are cross-deployed between two IDCs in the same city, so that dual-active in the same city can be realized at the granularity of DCN units.
DCN active/standby cross deployment architecture

So, based on this IDC and DCN architecture, how to select the database? How to design the architecture?
Objectively speaking, in 2014, there were not many domestic distributed database products that met financial-level requirements, and the range of options was very limited. After thorough investigation and evaluation, Weizhong finally chose Tencent's database product TDSQL as the core database under the DCN architecture.
Based on TDSQL, we designed the following database deployment architecture:
Database deployment architecture of three centers in two places

It can be seen that the deployment architecture of TDSQL also follows the principle of two places and three centers, which is divided into the main database SET in the same city, the standby database SET in the same city, and the standby database SET in different places. The primary database SET in the same city and the standby database SET in the same city are composed of three data copies (one primary and two standby), and the remote standby database SET is composed of two data copies (one primary and one standby).
SET's internal TDSQL-based strong and consistent data synchronization function for active and standby data can achieve high reliability and zero loss of data.
2. 2016 ~ 2018, Transformation of Multi-Activity Architecture in the Same City
The architecture of IDC 1.0 era basically meets the business development needs of our bank, but there are still the following problems:
The database synchronization between dual centers in the same city is quasi real-time, and data loss may occur in extreme scenarios (RPO in the same city is not 0)
Only the granularity of the DCN sharding unit has been realized, but the real application has not been realized in the same city data center;
When a single DCN or IDC fails, manual intra-city disaster recovery switchover is required, which takes too long (RTO is about two hours)
There are 6 copies of the database in the same city, and the resource cost is high.
Since there is a problem, it must continue to optimize the architecture. So we put forward the second phase of architecture optimization goals:
Realize the multiple activities of the application system in the same city and across data centers;
The same city RPO of the database = 0, and the same city RTO is close to 0;
Reduce the number of database copies and reduce costs.
First of all, we added a new data center in the same city, from two centers in the same city to three centers in the same city (IDC 2.0), which is the prerequisite for realizing the multi-active architecture in the same city.
IDC 2.0 architecture diagram

Based on IDC 2.0, we designed a three-center multi-active solution in the same city, and the application layer and database architecture were adjusted accordingly.
Multi-active architecture in the same city

At the database level, the original dual-center active-standby SET architecture model is adjusted to a single SET three-replica cross-three-center deployment model. The primary node can read and write, and the standby node can read-only. It can achieve intra-city and cross-IDC RPO at the database level. = 0, RTO reaches the second level.
With this as the premise, the application layer can achieve real multiple activities across the same city data center. That is to say, the application layer can deploy a set of peer-to-peer application systems in each of the three data centers in the same city, and access business traffic, which is forwarded by the access layer, and finally to the master node of the database (when read-write separation is turned on, Read traffic can be forwarded to the standby node).
The architecture transformation of multiple active applications in the same city further improves the overall availability and simplifies the disaster tolerance architecture. At the same time, the six copies of the database are reduced to three copies, which greatly reduces the resource cost, and it can be said that the architecture optimization is well completed. Target.
3. From 2018 to 2020, introduce NewSQL database
With the rapid development of business, the number of DCN is also rapidly increasing. The horizontal expansion feature of DCN has well supported the rapid growth of business. However, in some mid- and back-end business scenarios that are not based on the DCN architecture, the single-instance architecture database has gradually encountered capacity or performance bottlenecks.
A more typical scenario is the data storage of security deposits. This scenario belongs to the middle and back office business, and it needs to continuously store transaction behavior data for audit or proof at any time, so it generally cannot be deleted. As the scale of the business increases, the number of deposit certificates will continue to increase.
However, for a single-instance database, it is required that the storage capacity cannot exceed 3 TB. One reason is the limitation of the hardware (the capacity of a single disk of SSD), and the other is that the large capacity of a single instance will bring the database Uncertainty in performance and complexity of operation and maintenance.
According to a more traditional solution, you can choose a middleware-based sub-database sub-table solution to solve this problem.
However, sub-database and sub-table is actually a solution that is not very friendly to business development and DBA. For business development, because sub-database and sub-tables generally have some restrictions and restrictions at the grammar and SQL usage level, it is generally necessary to refactor the code and SQL to adapt to the database usage in the sub-database and sub-table environment; for DBA In other words, the scalability of sub-databases and sub-tables is not so flexible, and daily operations such as DDL are also more complicated, which increases the overall operation and maintenance workload.
We don't want to go back to the old way of sub-library and sub-table, so we are also exploring whether there is a more elegant and advanced solution. Beginning in the second half of 2018, the concept of NewSQL gradually emerged, bringing a new database with a distributed architecture of Share Nothing (basically based on the distributed architecture of Google Spanner).
After thorough investigation and evaluation, we finally chose the domestic open source NewSQL database product TiDB to try. TiDB has the following features that attract us:
TiDB uses a standard Share Nothing architecture, separates computing and storage, and can be scaled horizontally, and is transparent to the business layer.
TiDB uses the MySQL protocol system, which is highly compatible with our current protocol system, reducing business development and migration costs and access thresholds.
TiDB adopts an open source model for operation, the community is relatively active, the version iteration is fast, and some Internet users have begun to use it.
TiDB overall architecture

It can be said that the features of TiDB can solve our needs and bottlenecks very well, but at that time TiDB was still a very new database product with insufficient stability and maturity, so we were also very cautious in conducting sufficient testing and verification. In production, the more marginal business scenarios are first selected for grayscale, and a piece of data is synchronized to TDSQL in quasi-real-time for the bottom line.
The deployment architecture of TiDB in Weizhong is also similar to TDSQL. It takes advantage of the hardware advantages of three computer rooms in the same city and adopts three copies of the same city to deploy across three centers, which can effectively support the application of the same-city multi-active architecture.
TiDB deployment architecture

After nearly two years of operation, we have applied TiDB in various mid- and back-office businesses such as security, intelligent monitoring, data archiving, anti-fraud, anti-money laundering, and historical transaction details inquiry. As the TiDB version gradually matures, the overall stability and operability have also improved a lot.
Looking back, although we took the risk of eating crabs and adopted NewSQL's solution and gave up the solution of sub-database and sub-table, the benefits brought were huge.
At present, TDSQL continues to be the core database, carrying the core system under the DCN architecture; TiDB as a supplement, carrying the middle and back-end systems under the non-DCN architecture that require high capacity and scalability. TiDB, as a supplement to the entire single meta-architecture of Weizhong, makes up for shortcomings at the database level.
4. From 2020 to 2021, the application of NewSQL in core batch scenarios
After more than two years of using the TiDB database, I stepped on a lot of pits and accumulated a lot of experience. TiDB itself has become more mature and stable with version iterations, and has gradually formed an enterprise-level database product.
At the beginning of 2020, we received an optimization request from the loan technology department for the end-of-day batch system of the loan core.
At that time, the end-of-day batch system of the loan core system was deployed inside the business DCN and reused the TDSQL database resources in the DCN with the online system. With the accumulation of transaction data, the batch of loan core systems is facing the following problems:
The batch time continues to increase (nearly three hours before optimization). If the batch needs to be rerun for some reason, there is a relatively large risk of timeout.
Both the batch system and the online system are deployed in the DCN. The high database load caused by the batch system will affect the online system.
Limited by the principle of MySQL's primary and backup replication and the performance bottleneck of a single instance, it is impossible to continue to improve batch efficiency by improving application layer concurrency.
Batch efficiency has gradually become the user capacity bottleneck of a single DCN, rather than the actual number of users.
Loan core batch structure (before optimization)

Based on the above issues, the business department also proposed optimization goals:
Refactoring the entire batch system (including the application layer and the database layer), the overall batch time of the core business Weiwei Loan has been shortened to less than half an hour (within the limited resources).
Completely decouple the resources of the batch system and the online system (including the application layer and the database layer)
The database of the batch system needs to be horizontally scalable.
At first seeing this optimization goal, I felt that it was still challenging. In particular, the batch calculation and processing of hundreds of millions of accounts every day needs to be optimized to be completed within half an hour, and there should be no such capacity.
After evaluation, we finally decided to try to use the NewSQL database TiDB to host the batch system of the loan core (the optimized architecture is shown in the figure below). The batch data is synchronized to the TiDB cluster in near real-time through TDSQL in DCN every day for summary, and then the batch application program performs batch calculation and processing in the TiDB cluster. After nearly a year of continuous optimization, adjustment and grayscale verification, the final project went online smoothly and fully reached the set optimization goal.
Loan core batch structure (after optimization)

The following table shows the time-consuming comparison before and after the core batch optimization of 5 main loan businesses of Weizhong. The optimization effect is very obvious.
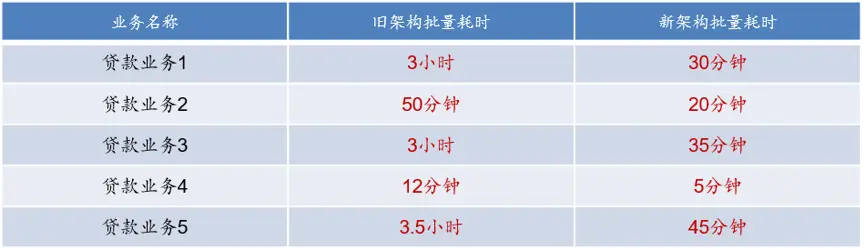
During the implementation of the entire project, many pits were stepped on, and many optimization experiences and lessons were summed up. The main points are as follows:
- Overall reconstruction and optimization of the application SQL model
For batch-applied SQL, carry out SQL batch transformation to improve the efficiency of a single SQL;
Cache frequently accessed hot static data to reduce the number of SQL requests;
Optimize the memory usage and execution plan of complex SQL to reduce the time consumption of SQL.
- Optimization of hot data breakup mechanism based on TiDB
In the database of the Share Nothing architecture, data hotspots are a problem that is often encountered. If the sharding rules or the applied writing rules are unreasonable, it is easy to form a hotspot for a certain database sharding, causing the database response to change. Slow, even suspended animation.
The batch data tables at the core of the loan are imported with hundreds of millions of data volumes, and hot issues are more obvious. In response to the data import of such large tables, we have developed a data table pre-breaking function in conjunction with database vendors, which completely avoids hot issues.
- Optimization of the consistency check mechanism for TDSQL to TiDB data synchronization
The correctness of the data in the core batch of loans is of utmost importance. In the optimized architecture, batch data tables need to be summarized and synchronized from multiple TDSQL sources in near real-time to a TiDB cluster, and the tables are combined. In order to ensure the reliability and accuracy of data synchronization, we have made optimizations on three levels:
Optimized the high-availability architecture of the data synchronization tool to ensure that there is no single point of problem, and after a synchronization node fails, it can be replaced and restored automatically;
Add a full range of monitoring to data synchronization, including synchronization status, synchronization delay, data source survival status, target survival status, etc.;
Add real-time verification of data fragment synchronization at the application layer. For each data segment, the application layer will calculate a CRC check value and synchronize it from the upstream TDSQL to the downstream TiDB. After the data of this segment is synchronized, perform another CRC calculation in the downstream and synchronize it with the upstream. The CRC value of the data is compared; in addition to the fragmentation check, there will be a final consistency check of the number of data rows.
- Establishing and rehearsing the failure SOP plan and the bottoming mechanism
In response to batch interruptions caused by daily server failures or database bugs, a plan for batch breakpoints to continue running was prepared, and regular drills were performed in the production environment;
For scenarios where possible data confusion causes batch re-runs, the rename backup table before batch can be used to quickly batch re-runs.
For extreme disaster scenarios, where the database needs to be rebuilt for batch reruns, the database can be quickly rebuilt and imported through the cold backup data before batch to realize batch reruns.
The application of the TiDB database in the loan core batch system is another supplement and improvement to the entire unitized architecture of Weizhong. We often say that there is no silver bullet for databases, and no database can be applied to all business scenarios. For each scenario, use the most suitable database product and database architecture to maximize the value.
In addition to relational database products, we also use Redis extensively to suit most reading scenarios that require high concurrency and low latency response. On the premise of ensuring the consistency of the architecture as much as possible, we also introduced a small number of database products such as Monggo DB, PostgreSQL, and Oracle according to the actual needs of the business.
In the future, we will also continue to explore in the direction of cloud native database, intelligent operation and maintenance of database, localization of database hardware, application practice of HTAP scenario, etc., and continuously improve and perfect our architecture, which is the application practice of domestic database in financial scenarios. Contribute one's own strength.
The content of this article comes from the article "The Chronicle of WeBank's Database Architecture" under the official account of WeBank's Basic Technology Products Department, TCTP. The author is Hu Panpan, the person in charge of WeBank's database.







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。