
I. Introduction
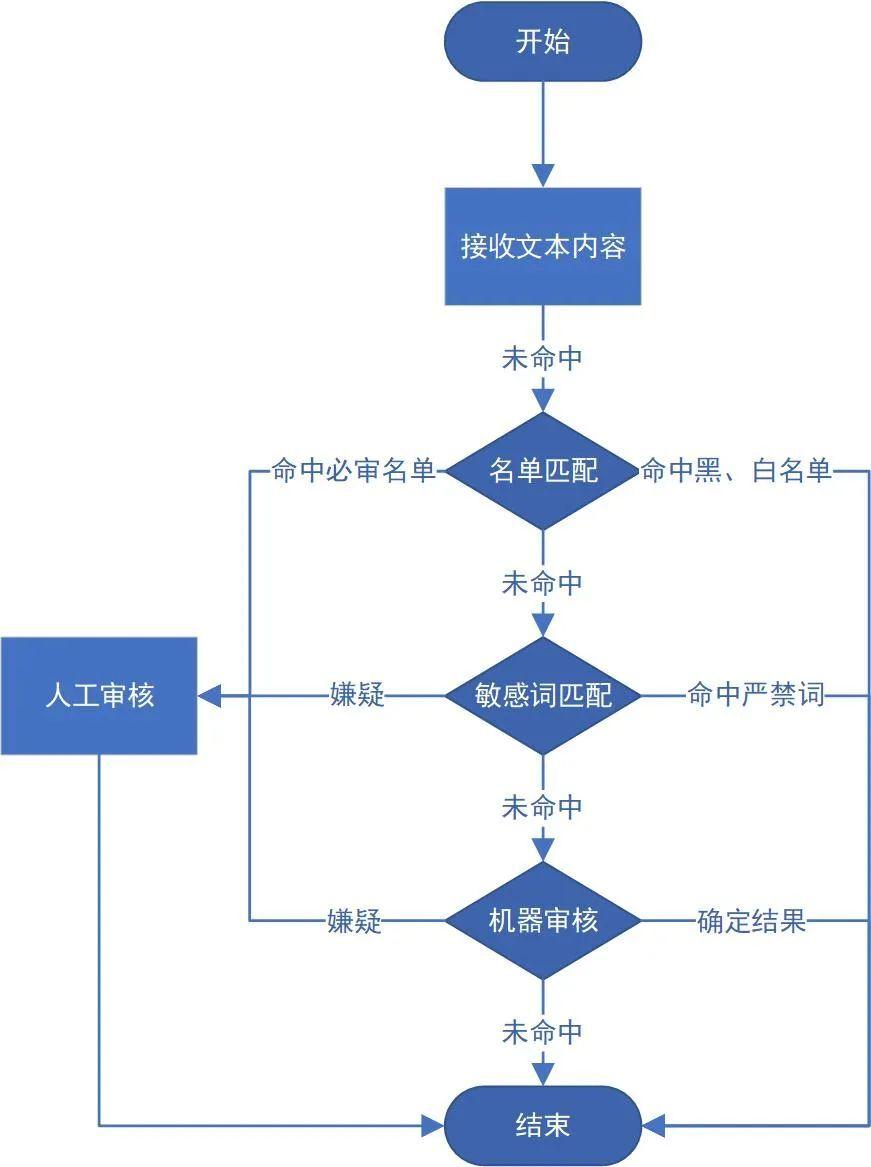
DiTing system is vivo's content review platform, which guarantees the sustainable and healthy development of vivo's Internet products. Diting supports the review of multiple content types, but the main content of daily review is text. The following figure is a complete text review process, including list matching, sensitive word matching, AI machine review, and manual review. The text to be reviewed needs to go through the three processes of list matching, sensitive word matching, and AI machine review in sequence. If the result is suspicious, manual review is required, otherwise a definite result will be given directly.
The sensitive word matching function can quickly match the sensitive words in the text. The average time of the algorithm is 50ms. Because of its simple, fast, direct, and flexible features, it has become a weapon for reviewers to fight spam. However, netizens in the era of information explosion are very "excellent." They have continuously invented various new words and homophones to bypass sensitive word detection. For example, some users will use words such as "啋 Piao" and "Cai Piao" to circumvent the sensitive word "lottery". Among them, "啋 Piao" is not only a homophone, but also contains polyphonic characters. Conventional pattern matching algorithms can hardly guarantee a complete hit. . This not only brings challenges to operating rules, but also places requirements on the accuracy of matching algorithms and missed kill rates.
This article will start with the selection of the algorithm and introduce the sensitive word matching algorithm of the DiTing system in combination with two actual scenarios. Among them, the second section introduces the idea of selecting the underlying algorithm, and the third section introduces two practical scenarios to improve the accuracy of sensitive words and reduce the missed kill rate.
2. Algorithm selection
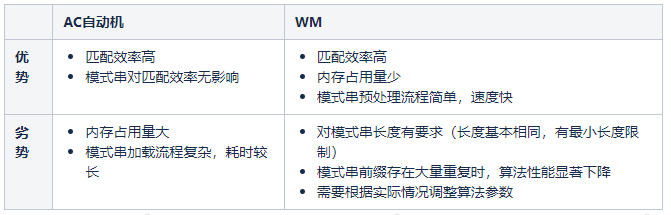
The sensitive word matching function relies on the pattern matching algorithm. The definition of pattern matching is that, given a substring, find all the substrings that are the same as the substring in a certain string. The given substring is called the pattern string, and the matched string is called the target string. Algorithms for matching based on multiple pattern strings are called multi-pattern matching algorithms. The current mature multi-pattern matching algorithms include AC automata and WM.
2.1 Comparison of multi-pattern matching algorithms
Diting’s sensitive word matching business has the following characteristics:
1) The volume of the lexicon is large, and a million-level lexicon (pattern string) needs to be maintained and loaded;
2) Sensitive words have strong relevance to business characteristics and national policies, and it is impossible to uniformly agree on characteristics such as length and prefix.
The WM algorithm has certain requirements on the length and prefix of the pattern string, which may affect the use of services. Although the AC automata takes a long time to load and a large memory footprint, the sensitive words are not loaded frequently and the server has sufficient memory resources, so we finally chose the AC automata as the underlying algorithm.
2.2 Introduction to AC Automata Algorithm
The AC automata algorithm (Aho-Corasick algorithm) is a string search algorithm that can match the target string with all pattern strings at the same time. The algorithm has a time complexity similar to linear under the condition of amortization. The matching principle of AC automata has two core concepts: Trie dictionary tree , Fail pointer . Let's take the pattern string set {"she", "he", "shers", "his", "era"} as an example to introduce these two concepts.
When the AC automata algorithm starts, all the pattern strings need to be loaded into the memory to construct a Trie dictionary tree. For example, the following figure is {"she", "he", "shers", "his", "era"} , each node in the tree represents a character, from the root node to a certain The path of a node can represent a pattern string, and the red node represents the end of a string. For example, the three nodes on the rightmost subtree in the figure can represent the pattern string "era". Starting from the root node of the dictionary tree, a certain pattern string can be found quickly. In addition, the pattern strings with the same prefix will be merged into the same subtree. For example, the middle subtree represents the pattern strings "he" and "his", and these two strings are respectively a branch of the "h" node. The AC automata can save the number of matches when searching for such strings.
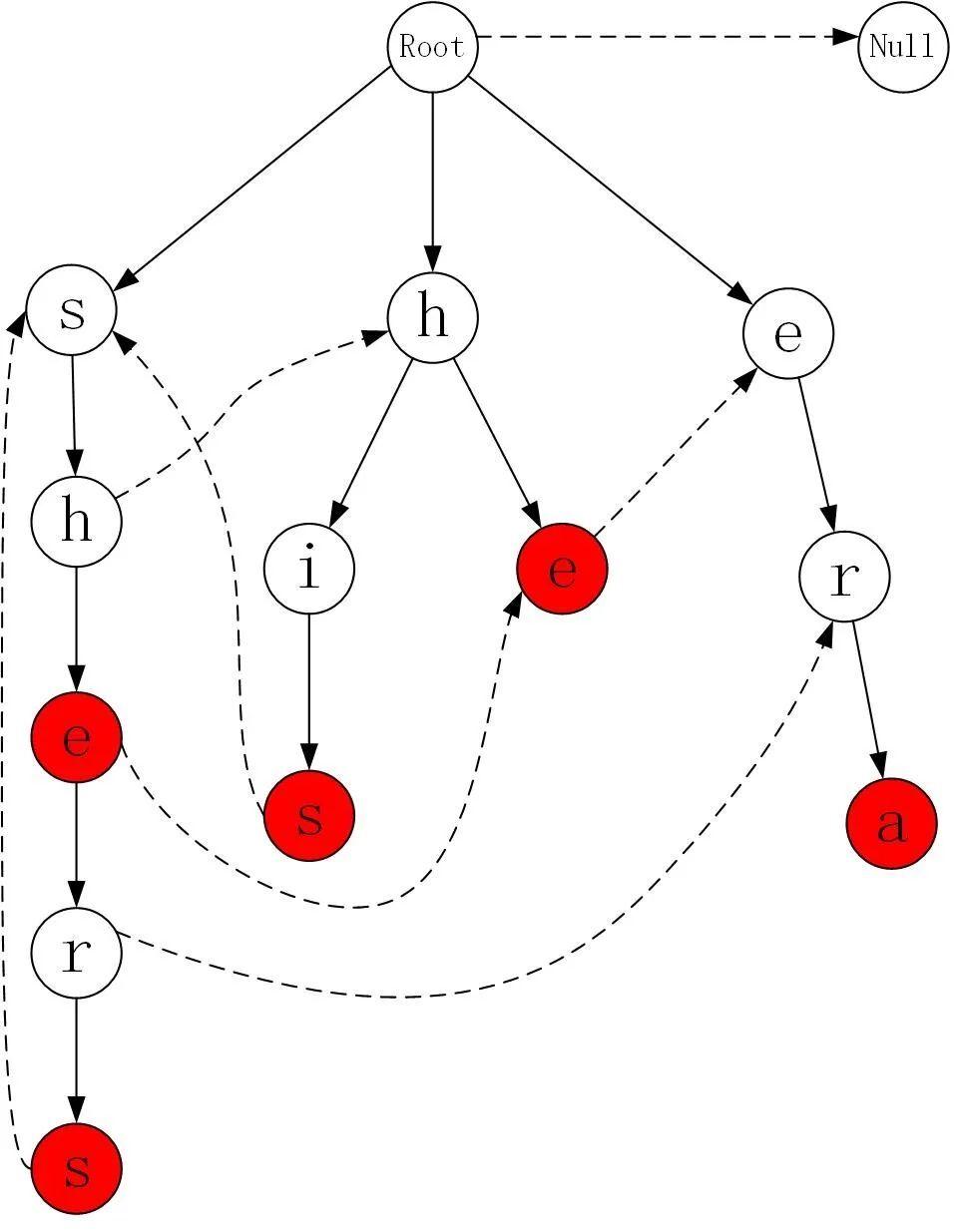
On the basis of the Trie tree, the AC automaton adds Fail pointer for each node. The above figure uses dotted lines to draw the Fail pointers of some nodes. For nodes without dotted lines, their Fail pointer points to the root node. When the algorithm fails to match a node, it can use the pointer to transfer to other branches that contain the same prefix to continue matching. For example, when matching the target string " shis ", for the first two characters " sh ", the Trie dictionary tree matches the left word count " h " node, because the child node of this node is " ", does not match the next character of the target string " i ", so the algorithm transfers to the "h" node of the intermediate subtree through the Fail pointer to continue matching, and finally hits the string " his ".
The aforementioned Trie dictionary tree and Fail pointer form the data model of the AC automaton. When the AC automaton matches the target string, it will take out the characters from the target string in order, starting from the root node of the Trie dictionary tree, looking for the node matching the character in the sub-nodes, and if it can find the node, then transfer to this node , If not found, then transfer to the node pointed to by the Fail pointer. When the state transitions to the red node in the graph, a pattern string is hit. The following figure shows the matching process merashisnx

Third, the practice of Ditending System
Diting System builds a set of sensitive word matching services based on the AC automata algorithm. It uses sensitive words as pattern strings and text content as target strings, which can match commonly used Chinese and English sensitive words. However, the actual business has many subdivided scenarios. The ordinary AC automata algorithm can no longer meet the needs of business use. Therefore, we explored two matching methods: combination sensitive word matching and pinyin sensitive word matching, which are introduced below.
3.1 Combining sensitive words
Conventional sensitive word matching algorithms usually match a single word or short sentence, but certain words do not violate the rules when they appear alone, and can be judged as violations only when they appear with several specific words at the same time. For example, " Macau ", " gambling ", " website ", these words, appearing alone are no problem, but in this sentence: " welcome to log on to the official website of Macau " , Is the illegal gambling advertisement. For such a scenario, we have implemented a "combined sensitive word" matching scheme. The operator can configure these words into a combination " Macau + gambling + website ". Only when these three words appear at the same time, the sensitive word service Only then will this combination be judged as a hit.
The matching algorithm for combining sensitive words is still based on the AC automata algorithm. Since the AC automata can only judge the hits of a single word, we divide the combined sensitive words into single sensitive words and maintain the mapping relationship between each sensitive word and the combination. After the AC automata algorithm runs, there is only a certain combination Only when the corresponding sensitive words all hit, can the combination of sensitive words hit. To this end, we need to add some pre- and post-processing steps to the AC automata. The specific steps are as follows:
- Divide the combined sensitive words into single sensitive words, and record the mapping relationship between the sensitive words and the combination;
- Add the split combination of sensitive words to the Tire tree of the AC automaton;
- Run AC automata to match text;
- Traverse the matching results, and map the matching results to the corresponding combination according to the mapping relationship;
- Record the hits of the combination and get the final matching result.

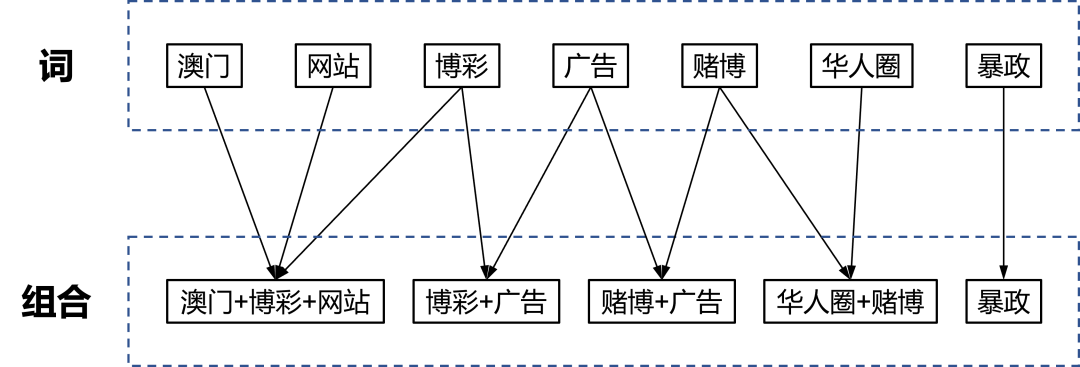
Assuming that existing combination of sensitive words " Macau + Gaming + website ", " betting + advertising ", " Chinese circle + gambling ", " gambling + advertising ", as well as general sensitive words " tyranny " , in step 1, we will be a combination of sensitive words into individual sensitive words: " Macau ", " website ", " betting ", " advertising ", " gambling ", " Chinese circle ", " tyranny ", and establish the mapping relationship shown in the figure. After you add these words to the AC automaton, the text " Welcome Macao XX gaming official website to" match will hit a single sensitive words " Macau ", " website ", " betting ." In step 4, the algorithm maps the matched words to the combination and marks the corresponding word hits. For example, according to " betting ", the combination " Macau + gambling + website ", " betting + advertising " can be taken, and then marking the two combinations of " betting hits. Step 5 will determine whether the combination is a hit according to the word hits in each combination. Because Macau + gambling + website " in step 4 are all marked as hits, it can be judged as a hit. The combination hits.
3.2 Pinyin sensitive words
In the high reviews, barrage and other creative freedom in the scene, some users in order to avoid machine audits, will use some polyphone, homophone to express sensitive words, such as "Xiao ticket" to represent " lottery " etc. . Due to the many variations of polyphones and homophones, it is very difficult to list all the homophones of a word. Therefore, we have implemented a matching scheme for pinyin-sensitive words, converting Chinese text into pinyin and matching again. By matching sensitive words by pronunciation, we can ensure that all homophones are hit, and we can directly configure the pinyin of sensitive words, such as " CAI PIAO " , You can hit " ticket ", " lottery ", " pick drift " and other words.
3.2.1 Matching process
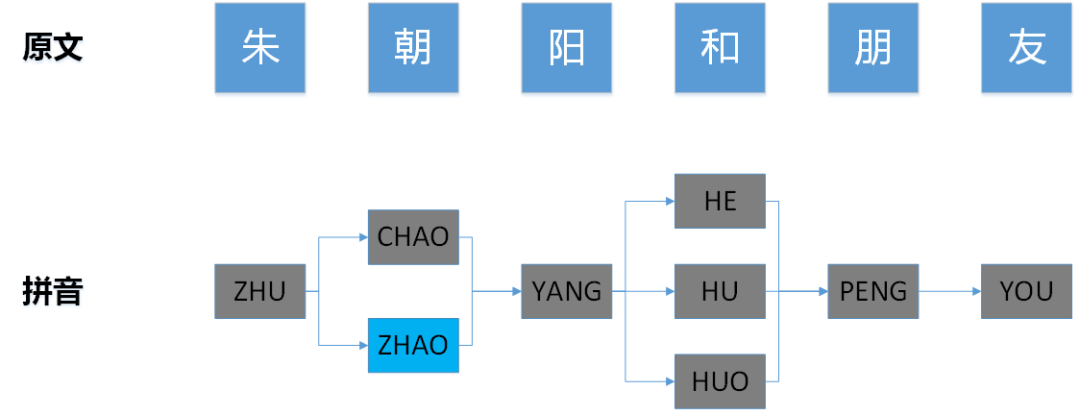
The conventional AC automata algorithm matches character by character, so each node on the Trie tree stores a character, but pinyin-sensitive words need to be matched according to syllables, so we change the node data type of the Trie tree from char to String. Example:

The key to matching pinyin-sensitive words is to accurately convert Chinese characters into pinyin, which is especially important in the scenario of polyphonic characters. Since the pronunciation of polyphonic characters is affected by context, the existing technical conditions are difficult to ensure that polyphonic characters can be accurately converted into pinyin. As mentioned above, the homophone "啋 Piao" is a user-made word, and the algorithm cannot be accurate. It is possible to convert to two different results: CAI PIAO " and " XIAO PIAO If the pinyin conversion is not accurate, the pinyin-sensitive words cannot be accurately hit.
Therefore, we do not rely on algorithms to recognize the pronunciation of polyphonic characters, but list all the pronunciations of the text content to match it again, so as to avoid the problem of inaccurate pinyin conversion.
The following figure shows the corresponding relationship between text content and pinyin. Due to the existence of polyphonic characters, the array storing pinyin has been expanded from one-dimensional to two-dimensional, which is more like a "picture" data structure, which is called a pinyin map in the following. There are multiple paths between the start node and the end node of the pinyin graph. These paths correspond to all permutations and combinations of polyphonic characters. In order to avoid missing kills, we need to use AC automata to match all these paths.

It can be seen from the matching process in the second section that the target string is a one-dimensional array, so the AC automaton usually adopts a sequential traversal method when matching text. In Pinyin-sensitive words, since the target string is stored in a two-dimensional array, which is a data structure similar to a "graph", it is no longer suitable for sequential traversal, so the traversal algorithm of graphs is required.
Among graph traversal algorithms, the most commonly used are depth-first traversal (DFS) and breadth-first traversal (BFS). Since words are contextually related, in order to make the algorithm more in line with human thinking habits, we chose DFS. The DFS algorithm uses the stack to store node information. After the current branch traversal is completed, the information in the stack is used to trace back to the previous branch to continue the traversal. Since the status bits of the Trie tree are related to the nodes of the Pinyin map, the Trie tree also needs to be backtracked synchronously during DFS backtracking. Therefore, the status bits of the Trie tree and the node information of the Pinyin map need to be saved to the DFS stack together. The following figure shows the matching process of pinyin-sensitive words.

3.2.2 Termination conditions and pruning strategy
The termination condition of DFS is when all nodes have been traversed, and the algorithm will ensure that each node will only be traversed once. However, the DFS traverses backtracking at the branch, so the node that usually ends is not the end of the text to be matched, and it is very likely that the matching of the AC automata has not been completed.
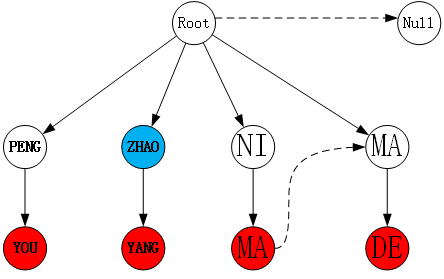
For example, in the matching process shown in the figure below, the left picture is based on the text "Zhu Chaoyang and friends" to be matched, and the right picture is based on the pinyin sensitive words "PENG YOU", "ZHAO YANG", "NI MA", Trie tree constructed by "MA DE". The pinyin graph on the left is traversed using the DFS algorithm. The last node visited by the algorithm is the blue node " ZHAO ". At this time, all nodes in the pinyin graph have been traversed once and the DFS termination condition has been reached. However, the status bit on the Trie tree in the right figure is at the position of the blue node " ZHAO ", and it has not reached the end state. If the matching is stopped at this time, the sensitive word " ZHAO YANG " will not be hit, so the algorithm It should continue to run until the AC automaton fails to match.
Therefore, the appropriate termination condition is: All nodes in the and the AC automaton fails to match .
Since the algorithm requires a combination of state DFS and AC automatic machine to determine the termination condition, so there will be spelling FIG case traversed many times a node and a path, when to be matched text polyphone when the increase in the number, DFS traversal path The number will increase in the form of a Cartesian product. There will be some repetitions in these paths, so appropriate pruning strategies need to be adopted during the traversal process to avoid searching for some repetitive paths. For example, in the traversal situation shown in the left figure below, the two nodes "PENG" and "you" on path ② have been traversed by path ①, and the corresponding AC automata state bit (refer to the right figure) prefix does not include the current traversed node " HU ", so PENG " has nothing to do with path ②, so there is no need to search again. We can design a pruning strategy for this scenario, and the path that needs to be pruned needs to meet two conditions:
1) First, the next node of the current node has been traversed;
2) The state of the AC automaton corresponding to the next node has nothing to do with the current node.
We mark a branch path length B for each node in the Pinyin graph, which represents the path length between the current node and the last branch node. For example, the branch path length corresponding to the node "PENG" is B = 2 (from " HU "to" PENG "), the node" YOU "branch path length. 3 = B (" HU ", " PENG "," YOU "). In the state machine of the AC automaton, the depth D of each node on the Trie tree is recorded. For example, the depth of the " PENG " node in the D =1, and the depth of the YOU D =2. The characters passing through the path from the root node of the Trie tree to a certain node are connected to form the pattern string corresponding to the node. Therefore, the depth of the node D the length of the pattern string. When D <B, it indicates that the length of the pattern string currently being matched is shorter than the branch path length of the current node in the Pinyin diagram, so the current pattern string has nothing to do with the current path.
To sum up, the conditions required for pruning are:
1) The next node in the pinyin graph has been traversed;
2) The branch path length of the pinyin diagram B> the depth D of the Trie tree node.


Fourth, summary and outlook
The Diting system is based on AC automata to realize the matching of ordinary sensitive words, combined sensitive words, and pinyin-sensitive words. Among them, combined sensitive words and pinyin-sensitive words can also be combined into pinyin combined sensitive words, covering most of the text review scenes and reducing The pressure of machine review and human review. In addition, when the policy wind changes, the sensitive word matching function provides a means for operating colleagues to quickly change the review strategy, making Diting's text review capabilities more flexible. At present, Diting Online has configured more than 1 million sensitive words, which greatly protects the company's content security.
In the future, we will continue to optimize the ability to match sensitive words in combination with business usage scenarios to improve accuracy and hit rate. On the one hand, we can implement the logic of "not" in a certain way, so that bad cases can be eliminated when configuring sensitive words, and the accuracy of hits can be improved. On the other hand, we can achieve fuzzy hits of sensitive words and improve the hit rate of sensitive words.
Author: vivo internet server team-Liang Kangwu





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。