
Today, we are happy to release the file system of the Curve project, as well as a new deployment tool. This is also the first beta version of CurveFS, which indicates that with the joint efforts of colleagues in the Curve community, Curve is one step closer to the more usable cloud-native software-defined storage.
Version address:
https://github.com/opencurve/curve/releases/tag/v0.1.0-beta
In the first half of 2021, the Curve team decided to distributed shared file system. Our 161bb072fbec7c Roadmap lists some key features that are planned to be implemented, including:
Provides a user-mode file read and write interface based on FUSE, and is compatible with the POSIX protocol
- Support data storage to object storage system
- Support cloud native deployment, operation and maintenance, and use
- Support multiple file systems
The first release version of CurveFS has currently implemented the above functions, and more functions are still under development. Welcome to try it out.
Why do CurveFS
The NetEase Shufan storage team, which supports the development of multi-domain digital services and open-sourced Curve, first felt the need for a new generation of distributed file system in practice, and got the resonance of the members of the Curve community.
From communicating with NetEase’s internal products and commercial customers of Shufan, the distributed file system used by users is mainly CephFS (used with Kubernetes for PV). In recent years, users have encountered difficulties in the following scenarios. solved problem:
Scenario 1: A machine learning scenario that expects to balance performance and capacity
In a business machine learning scenario, in the process of using CephFS, the training time is expected to be as short as possible, and the training results are expected to be stored for a long time, but the access frequency is very low. Therefore, it is hoped that it can be actively/passively deposited in the capacity storage pool when needed. Migration to performance storage pools can be triggered actively/passively. Active here means that the business can switch the storage type of a certain directory (such as capacity type, performance type) by itself, and passive means that the storage pool switch is triggered by configuring certain life cycle rules (or cache management strategies).
In this scenario, CurveFS can speed up the reading and writing of training samples through multi-level caching (CurveFS client-side memory cache, client-side hard disk cache, CurveBS-based data cache, and CurveBS-based high-performance data pool) to accelerate the reading and writing of training samples, while cold data is placed To the capacity storage pool, that is, the object storage. When users want to train a sample set that has been deposited in the cold data pool, they can actively warm up this part of the data in advance to speed up the training process (or can be passively loaded). This part of the function will be supported in subsequent versions.

Scenario 2: Business B that expects to be quickly and elastically released across clouds
Under normal circumstances, a privatized deployment of a CephFS cluster requires the preparation of multiple storage nodes, which involves a long period of time for machine preparation and shelf operations. It is generally not practical to deploy your own storage cluster in public cloud scenarios, so storage services provided by public clouds are generally used. For businesses that want a unified multi-cloud management, corresponding development needs to be carried out. We expect to be able to deploy to a variety of public clouds with one click and provide a unified use logic for the business.
In this scenario, CurveFS can quickly deploy a distributed shared file system with almost unlimited capacity through existing object storage services, and the deployment process is very simple and fast. In addition, if the performance of the object storage engine cannot meet the demand, CurveFS can also use cloud hard disks such as EBS, ESSD, etc. to speed up reading and writing (both client-side caching and server-side caching can be used).
The storage engine based on object storage is also very convenient for cross-cloud deployment. Operation and maintenance personnel can simply modify a few parameters and use the same set of deployment tools to complete cross-cloud deployment.

Scenario 3: Business C with low-cost and large-capacity requirements
Capacity requirements are the first priority, but the write speed should be fast. Currently, they are all three-copy scenarios, and the cost is slightly higher. I hope to support it. In this scenario, CurveFS can speed up the write speed through the client's memory cache and hard disk cache, and then asynchronously upload it to a low-cost object storage cluster (usually EC erasure codes are used to reduce copy redundancy). For users who do not want to purchase storage servers to deploy storage clusters, it is more cost-effective to use public cloud object storage services to achieve low-cost and large-capacity storage requirements.
Scenario 4: ES middleware automatic separation of hot and cold data
Hot data is stored in high-performance storage hardware, and cold data is stored in low-performance capacity storage hardware. Manual configuration is required, and it is hoped that it can be done automatically in the underlying storage engine. In this scenario, CurveFS can use hot data to be placed in a 3-copy CurveBS cluster, and cold data can be transferred to the object storage cluster after a certain period of time without access according to the configured life cycle rules.
Scenario 5: S3 and POSIX unified access requirements for a certain business
Expect to produce data by mounting the fuse client and access the data through the S3 interface. CurveFS will support the S3 protocol to access files in the file system in the future. It also supports the S3 protocol and the POSIX protocol. In addition, after supporting the S3 protocol, Curve will become a unified storage system that supports block, file, and object storage at the same time, bringing more to users The convenience.
Future planning scenarios:
As a unified storage layer for multiple storage systems (such as HDFS, S3 compatible object storage, etc.), Curve takes over and accelerates access to each system. Curve will subsequently support the takeover of multiple storage systems and perform unified cache acceleration.

Of course, in the process of using CephFS, we also encountered some problems that were difficult to solve by modifying the configuration or simple secondary development. This is also the source of motivation for our self-research:
- In some scenarios, the performance bottleneck is serious: especially in terms of metadata latency, even if multiple MDS+ static directory binding is enabled, the metadata storage pool uses SSD disks, or even the kernel mode client is used, the business still cannot be well satisfied. Appeal
- High availability risk: After the multi-MDS scenario + static directory binding function is turned on, once a main MDS fails, the switching time will be relatively long, and the business will be interrupted during the period
- Metadata load balancing problem: Static directory binding is barely usable, but its operability is insufficient and implementation is difficult; the current availability of dynamic directory migration is poor, which will cause frequent repeated migrations and affect the stability of metadata access
- The implementation logic of metadata lock is complex, difficult to understand, and the learning threshold is too high: the function is comprehensive, but the performance will inevitably be affected. In addition, the maintenance difficulty of developers is greatly increased, the secondary development is difficult, and the analysis of problems is also very difficult
- Balance problem: Ceph uses the crush algorithm to place objects. This algorithm may cause the cluster balance to be not particularly ideal, so it will form a short board effect, resulting in less available cluster capacity and higher costs
CurveFS architecture design
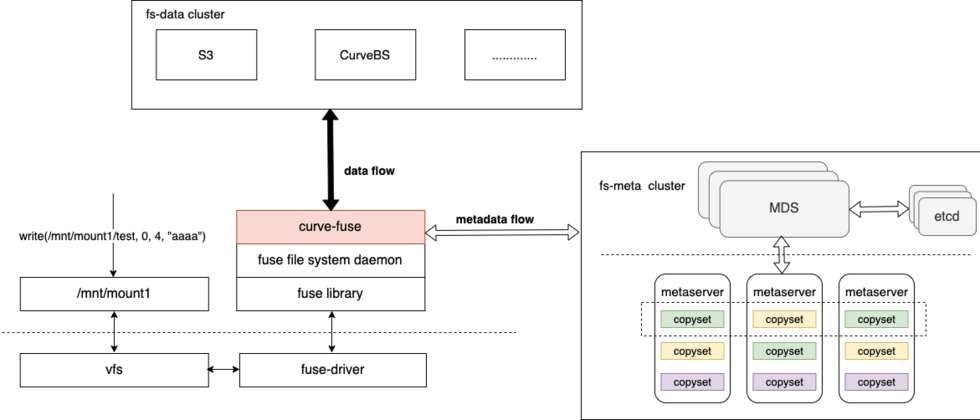
The architecture of CurveFS is shown in the figure below:

CurveFS consists of three parts:
- The client curve-fuse interacts with the metadata cluster to process file metadata addition, deletion, modification, and query requests, and interacts with the data cluster to process file data addition, deletion, modification, and query requests.
The metadata cluster metaserver cluster is used to receive and process metadata (inode and dentry) addition, deletion, and modification requests. The architecture of metaserver cluster is similar to CurveBS, with the characteristics of high reliability, high availability, and high scalability:
MDS is used to manage the cluster topology and resource scheduling.
A metaserver is a data node, and a metaserver corresponds to managing a physical disk. CurveFS uses Raft to ensure the reliability and availability of metadata. The basic unit of the Raft replication group is copyset. A metaserver contains multiple copyset replication groups.
- Data cluster data cluster, used to receive and process file data addition, deletion, modification, and checking. The data cluster currently supports two storage types: object storage that supports the S3 interface and CurveBS (under development).
The main function
Overview
The current version of CurveFS mainly has the following features:
- POSIX compatible: use like a local file system, business can be seamlessly accessed
- High scalability: the scale of metadata cluster can be linearly expanded
- Cache: The client has two levels of memory and disk cache acceleration
- Object storage and CurveBS supporting data storage to S3 interface (under development)
Client
The client of CurveFS realizes a complete file system function by docking with fuse, which is called curve-fuse. Curve-fuse supports data storage in two back-ends, namely S3-compatible object storage and Curve block storage (support for other block storage is also planned). Currently, it supports S3 storage back-end, and it is stored in the CurveBS back-end. In the process of improvement, it is possible to support mixed storage of S3 and Curve blocks in the future, allowing data to flow between S3 and Curve blocks according to the degree of heat and cold. The architecture diagram of curve-fuse is as follows:
curve-fuse architecture diagram

curve-fuse contains several main modules:
- libfuse, docked with its lowlevel fuse api, supports fuse user mode file system;
- Metadata cache, including fsinfo, inode cache, dentry cache, to realize the cache of metadata;
- Meta rpc client, which mainly connects to the metadata cluster, realizes the sending of meta op, timeout retry and other functions;
- S3 client, stores data in s3 by connecting to the S3 interface;
- S3 data cache, this is the cache layer of S3 data storage, as a data cache, accelerate the read and write performance of S3 data;
- The curve client realizes storing data in the Curve block storage cluster by connecting to the Curve block storage SDK;
- Volume data cache, which is the cache layer when data is stored in Curve block storage to accelerate data read and write performance (under development);
curve-fuse has now been docked with a complete fuse module, basically achieving POSIX compatibility, and the current pjdtest test pass rate is 100%.
S3 storage engine support
The S3 client is responsible for converting the read and write semantics of files into the data read and write (upload, download) semantics stored in S3. Considering the poor storage performance of S3, we have cached data at this level: memory cache (dataCache) and disk cache (diskCache). The overall architecture is as follows:

S3ClientAdaptor mainly includes the following modules:
- FsCacheManager: Responsible for managing the cache of the entire file system, including inode to FileCacheManager mapping, reading and writing cache size statistics and control
- FileCacheManager: responsible for managing the cache of a single file
- ChunkCacheManager: Responsible for the caching of a chunk in a single file
- DataCache: The smallest granularity of cache management, corresponding to a continuous data space in a chunk. The data is finally mapped to one or more objects stored in S3 at the DataCache layer for uploading
- diskCache: Responsible for local disk cache management, data persistence can be written to the local disk first, and then asynchronously written to the S3 storage, which can effectively reduce latency and increase throughput
- S3Client: Responsible for calling the back-end S3 storage interface, currently using AWS SDK
MDS
MDS refers to metadata management services. The MDS of CurveFS is similar to the MDS of CurveBS (Introduction to MDS of : 161bb072fbf4fd https://zhuanlan.zhihu.com/p/333878236), which provides centralized metadata management services.
The MDS of CurveFS has the following functions:
- Through the topology sub-module, manage the topo information of the entire cluster and the life cycle management of the entire topo
- Manage the super block information of fs through the fs submodule; provide functions such as file system creation, deletion, mounting and unmounting, and query; responsible for the distribution of inode, dentry and other metadata of fs in the metaserver
- Through the heartbeat submodule, maintain the heartbeat with the metaserver and collect the status of the metaserver
- Dispatch through the dispatch system. The metadata of curvefs uses a consistency protocol to ensure reliability. When a copy is unavailable, the scheduler will automatically recover. The scheduling function is under development
As a centralized metadata management service, its performance, reliability, and availability are also very important.
- performance of is 161bb072fbf636: First, all metadata on the MDS will be cached in the memory to speed up its search. Secondly, after fs is created, MDS will allocate fragments for storing inode and dentry information for fs. In the system, a fragment is called a partition. After the partition allocation is completed, the metadata operation of fs will be sent directly to the metaserver by the client. After that, the metadata management of the inode and dentry of fs does not go through MDS
- in terms of reliability and availability : The metadata of MDS is persisted to etcd, relying on 3 copies of etcd to ensure the reliability of metadata. You can choose to deploy multiple MDS services, but at the same time, one MDS will provide services to the outside world. When the main MDS hangs up for special reasons, it will automatically select a new main MDS in the remaining MDSs through the main selection algorithm to continue to provide Serve
MetaServer
MetaServer is a distributed metadata management system that provides metadata services for clients. File system metadata is sharded and managed. Each metadata shard provides consistency guarantee in the form of three copies. The three copies are collectively called Copyset, and the Raft consistency protocol is used internally. At the same time, a Copyset can manage multiple metadata fragments. Therefore, the metadata management of the entire file system is as follows:

There are two Copysets in the picture, and three copies are placed on three machines. P1/P2/P3/P4 represents the metadata fragments of the file system, where P1/P3 belongs to a file system, and P2/P4 belongs to a file system.
Metadata Management
The metadata of the file system is managed in fragments. Each fragment is called Partition. Partition provides an interface for adding, deleting, modifying, and checking dentry and inode. At the same time, all metadata managed by Partition is cached in memory.
Inode corresponds to a file or directory in the file system, and records corresponding metadata information, such as atime/ctime/mtime. When the inode represents a file, the data addressing information of the file is also recorded. Each Parition manages inodes within a fixed range and is divided according to inodeid. For example, inodeid [1-200] is managed by Partition 1, inodeid [201-400] is managed by Partition 2, and so on.
Dentry is a directory entry in the file system, which records the mapping relationship between file names and inodes. The dentry information of all files/directories in a parent directory is managed by the Partition where the parent directory inode is located.
Consistency
File system metadata fragments are stored in the form of three copies, and the raft algorithm is used to ensure the consistency of the three copies of the data, and the client's metadata requests are all processed by the raft leader. At the specific implementation level, we use the open source braft ( https://github.com/baidu/braft), and multiple replication groups can be placed on one server, namely multi-raft.
High reliability
The guarantee of high availability mainly comes from two aspects. First of all, the raft algorithm guarantees the consistency of the data. At the same time, the raft heartbeat mechanism can also enable the remaining replicas in the replication group to quickly run for the leader and provide services to the outside world in the event of an abnormal raft leader.
Secondly, Raft is based on Quorum's consensus protocol. In the case of three copies, only two copies are needed to survive. However, long-term operation of two copies is also a test of availability. Therefore, we have added a timing heartbeat between Metaserver and MDS. Metaserver will periodically send its own statistical information to MDS, such as: memory usage, disk capacity, replication group information, etc. When a Metaserver process exits, the replication group information is no longer reported to MDS. At this time, MDS will find that some replication groups only have two copies alive, so it will issue a Raft configuration change request through a heartbeat, and try to restore the replication group to the normal three copies. status.
The new deployment tool CurveAdm
In order to improve the convenience of Curve operation and maintenance, we designed and developed the CurveAdm project, which is mainly used to deploy and manage Curve clusters. Currently, the deployment of CurveFS is supported (the support of CurveBS is under development).
project address:
https://github.com/opencurve/curveadm
CurveFS deployment process:
https://github.com/opencurve/curveadm#deploy-cluster
The design architecture of CurveAdm is shown in the figure below:

- CurveAdm is embedded with a SQLite (embedded database, all DBs are a file), which is used to save cluster topology and information related to each service, including serviceId, containerId, etc.
- CurveAdm logs in to the target machine through SSH, executes commands through the Docker CLI, and controls the container. The images used by the container are various releases of Curve, and the default is the latest version.
Compared with the previous ansible deployment tools, CurveAdm has the following advantages:
- CurveAdm supports cross-platform operation, is packaged independently and has no other dependencies, can be installed with one click, and has better ease of use
- The Curve component runs in the container to solve component dependency problems and release adaptation problems
- Use golang development, fast development iteration speed, high degree of customization
- Self-service cluster logs can be collected and packaged and encrypted and uploaded to the Curve team for easy analysis and problem solving
- CurveAdm itself supports one-click self-update, which is convenient for upgrading
The currently supported functions are as follows:

If you are interested in the CurveAdm project, you are welcome to contribute (submit an issue or requirement, develop features, write documentation, etc.).
issues
The current version is the first beta version of CurveFS. It is not recommended to be used in a production environment. The known issues to be resolved are:
- Currently does not support shared read and write (under development)
- Hard disk data cache space management strategy and flow control function
- Random read and write performance issues: This is determined by the characteristics of the S3 engine, and we will further optimize it, such as using concurrent segmented upload, range reading, etc.
- Automatic recovery of abnormal nodes (under development)
- Recycle bin function: accidentally deleted data can be retrieved and restored
- Concurrent read and write feature: in the future, it will support simultaneous read and write of multi-node shared file system
- Monitoring access: use prometheus to collect monitoring information, and use grafana for display
Welcome to submit issues and bugs on GitHub, or add the WeChat account opencurve to invite you to join the group.
follow-up version outlook
The release rhythm of Curve’s overall project is usually a major version every six months and a minor version every quarter. CurveFS is a relatively large new version. The current first version has many incomplete functions and needs to be improved. The next major version is ours. The main development goals are (some adjustments may be made according to actual needs):
- CurveBS storage engine support
- Data cross-engine lifecycle management
- CSI plugin
- Complete deployment tools
- Based on K8s cluster deployment: currently supports the helm deployment method, and will continue to optimize in the future to support higher levels of cloud native operation and maintenance
- Write more read more
- Optimization of operation and maintenance tools (monitoring alarms, problem location)
- Recycle bin
- HDD scene adaptation optimization
- Compatibility with NFS, S3, HDFS, etc.
- Snapshot
If you have relevant demands, you can communicate with us.
What is Curve
Curve positioning
Positioning: An open source cloud native software-defined storage system with high performance, easy operation and maintenance, and support for a wide range of scenarios.
Vision: Easy-to-use cloud-native software-defined storage.
CurveBS Introduction
CurveBS is one of the core components of the Curve cloud-native software-defined storage system. It has the characteristics of high performance, high reliability, and easy operation and maintenance. It can be well adapted to cloud-native scenarios to achieve a storage-computing separation architecture. CurveFS will also support the use of CurveBS as a storage engine in the future. The overall architecture of CurveBS is shown in the following figure:

For detailed design documents, please refer to previous articles:
http://www.opencurve.io/docs/home/
https://github.com/opencurve/curve#design-documentation
https://github.com/opencurve/curve-meetup-slides
https://zhuanlan.zhihu.com/p/311590077
recent planning
- PolarFS adaptation: The docking of single pfsd + single CurveBS volume has been completed, and the feature of multiple pfsd + single CurveBS volume will be supported in the future. Code base: https://github.com/skypexu/polardb-file-system/tree/curvebs_sdk_devio
- ARM64 platform adaptation: basic functional testing has been completed, performance optimization and stability verification will be carried out in the future, code base: https://github.com/opencurve/curve/tree/arm64
- FIO CurveBS engine: Supported, code base: https://github.com/skypexu/fio/tree/nebd_engine
- NVME/RDMA adaptation: adaptation verification and performance optimization will be carried out in the near future
- iSCSI interface support: a wide range of applications and high universality. It is planned to support in the near future
- Raft optimization: Try to optimize Raft's log management, improve I/O concurrency, support follower read, Raft downgrade (3 copies only 1 copy survives and can still serve externally), etc.
For more information about Curve, see:
- Curve project homepage: http://www.opencurve.io/
- Source address: https://github.com/opencurve/curve
- Roadmap:https://github.com/opencurve/curve/wiki/Roadmap_CN
- Technical interpretation collection: https://zhuanlan.zhihu.com/p/311590077






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。