
今天,我们很高兴地发布Curve项目的文件系统,以及全新的部署工具。这也是CurveFS的第一个beta版本,预示着在Curve社区同仁的共同努力之下,Curve距离更好用的云原生软件定义存储又前进了一步。
版本地址:
https://github.com/opencurve/...
2021年上半年Curve团队立项决定做分布式共享文件系统,我们的Roadmap列出了一些打算实现的关键特性,其中包括:
提供基于FUSE的用户态的文件读写接口,并且兼容POSIX协议
- 支持数据存储到对象存储系统
- 支持云原生部署、运维、使用
- 支持多文件系统
CurveFS的首发版本当前已实现上述功能,更多的功能仍在开发当中,欢迎试用体验。
为什么要做CurveFS
支持多领域数字业务发展,将Curve开源的网易数帆存储团队,在实践中先一步感受到了新一代分布式文件系统的需求,并得到了Curve社区成员的共鸣。
从跟网易内部产品以及数帆商业化客户沟通,用户使用的分布式文件系统主要是CephFS(配合Kubernetes做PV使用),在近几年的使用过程中,用户在如下几个场景遇到了难以彻底解决的问题:
场景1:期望兼顾性能和容量的机器学习场景
某业务机器学习场景下,在使用CephFS过程中,训练耗时期望尽量短,训练结果期望长期保存,但访问频次很低,因此希望可以主动/被动沉淀到容量型存储池,需要用到的时候可以主动/被动触发迁移到性能型存储池。这里的主动是指业务可以自行切换某个目录的存储类型(如容量型、性能型),被动是指通过配置一定的生命周期规则(或缓存管理策略)来触发存储池切换。
CurveFS在这个场景下,可以通过多级缓存(CurveFS client端内存缓存、client端硬盘缓存,基于CurveBS的数据缓存,基于CurveBS的高性能数据池)来加速训练样本的读写,而冷数据则放到容量型的存储池也即对象存储上。当用户想要训练某个已经沉淀到冷数据池的样本集时,可以提前主动预热这部分数据来加速训练过程(也可以被动加载)。这部分功能会在后续版本中支持。

场景2:期望快速跨云弹性发布的业务B
正常情况下,私有化部署一个CephFS集群要准备多台存储节点,涉及到较长时间的机器准备、上架等操作。而在公有云场景部署一个自己的存储集群一般是不太实际的,因此一般使用公有云提供的存储服务。对于想要多云统一管理的业务,则需要进行相应的开发。我们期望可以做到一键部署到多种公有云上,对业务提供统一的使用逻辑。
CurveFS在这个场景下可以通过已有的对象存储服务快速的部署一套几乎无容量上限的分布式共享文件系统,而且部署过程非常简单快速。另外如果对象存储引擎的性能无法满足需求,CurveFS还可以通过云硬盘如EBS、ESSD等来加速读写(既可以做client端缓存,又支持做服务端缓存)。
基于对象存储的存储引擎,跨云部署也非常方便,运维人员简单的修改几个参数就可以使用同一套部署工具搞定跨云部署。

场景3:低成本大容量需求的业务C
容量需求是首要的,但写入速度要快,目前都是3副本场景,成本稍高,希望能支持。CurveFS在这个场景下,可以通过客户端的内存缓存、硬盘缓存来加速写入速度,之后异步上传到低成本的对象存储集群(通常采用EC纠删码来降低副本冗余)。对于不想采购存储服务器部署存储集群的用户来说,使用公有云的对象存储服务来实现低成本大容量的存储需求是比较合算的。
场景4:ES中间件冷热数据自动分离
热数据放在高性能的存储硬件,冷数据放在低性能容量型存储硬件,需要手工配置,希望能自动化在底层存储引擎做掉。CurveFS在这个场景下,可以通过热数据放在3副本的CurveBS集群中,冷数据根据配置好的生命周期规则,到达一定时间没有访问后,转存到对象存储集群中。
场景5:某业务S3和POSIX统一访问需求
期望通过挂载fuse客户端生产数据,通过S3接口访问数据。CurveFS后续会支持S3协议访问文件系统中的文件,同时支持S3协议和POSIX协议,另外支持S3协议后,Curve将成为一个同时支持块、文件、对象存储的统一存储系统,为用户带来更多的便利。
未来规划场景:
Curve作为多种存储系统(如HDFS、S3兼容对象存储等)的统一存储层,接管并加速各系统访问。Curve后续将支持接管多种存储系统,并进行统一的cache加速。

当然我们在使用CephFS过程中还遇到了一些难以通过修改配置,或者简单的二次开发解决掉的问题,这也是促使我们自研的动力来源:
- 部分场景下性能瓶颈严重:尤其是元数据时延方面,即使启用了多MDS+静态目录绑定、元数据存储池使用SSD盘、甚至使用内核态客户端等前提下,仍然不能很好的满足业务诉求
- 可用性风险高:多MDS场景+静态目录绑定功能开启后,一旦某个主MDS故障,切换时间会比较长,期间业务会中断
- 元数据负载均衡问题:静态目录绑定勉强可用,但可运维性不足,实施困难;动态目录迁移目前可用性较差,会造成频繁的反复迁移,影响元数据访问的稳定性
- 元数据锁实现逻辑复杂、难以理解、学习门槛过高:功能全面,但性能难免会受影响,另外开发人员维护难度大增,二次开发困难,遇到问题分析起来也很吃力
- 均衡性问题:Ceph通过crush算法来放置对象,该算法可能导致集群均衡性不是特别理想,故而会形成短板效应,导致集群可用容量较少,成本升高
CurveFS架构设计
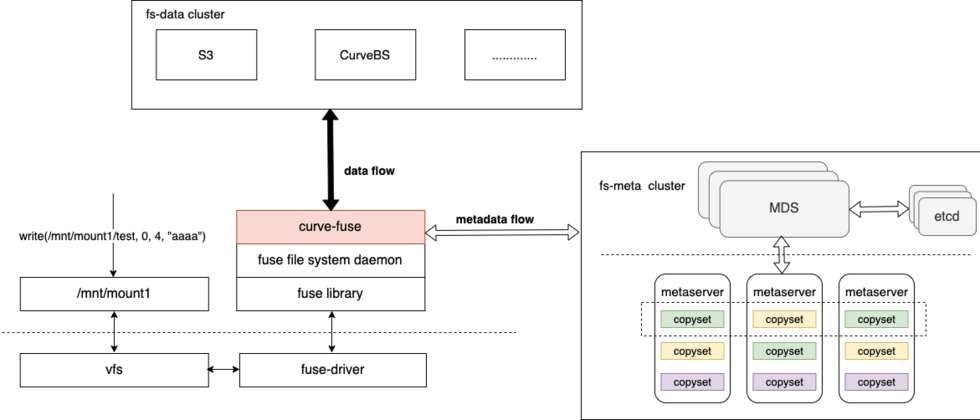
CurveFS的架构如下图所示:

CurveFS由三个部分组成:
- 客户端curve-fuse,和元数据集群交互处理文件元数据增删改查请求,和数据集群交互处理文件数据的增删改查请求。
元数据集群metaserver cluster,用于接收和处理元数据(inode和dentry)的增删改查请求。metaserver cluster的架构和CurveBS类似,具有高可靠、高可用、高可扩的特点:
MDS用于管理集群拓扑结构,资源调度。
metaserver是数据节点,一个metaserver对应管理一个物理磁盘。CurveFS使用Raft保证元数据的可靠性和可用性,Raft复制组的基本单元是copyset。一个metaserver上包含多个copyset复制组。
- 数据集群data cluster,用于接收和处理文件数据的增删改查。data cluster目前支持两存储类型:支持S3接口的对象存储以及CurveBS(开发中)。
主要功能
概述
当前版本CurveFS主要具有如下特性:
- POSIX兼容: 像本地文件系统一样使用,业务可以无缝接入
- 高可扩:元数据集群规模可以线性扩展
- 高速缓存:客户端有内存和磁盘两级缓存加速
- 支持数据存储到S3接口的对象存储和CurveBS(开发中)
Client
CurveFS的client通过对接fuse,实现完整的文件系统功能,称之为curve-fuse。curve-fuse支持数据存储在两种后端,分别是S3兼容的对象存储和Curve块存储中(其他块存储的支持也在计划中),目前已支持S3存储后端,存储到CurveBS后端尚在完善中,后续还可能支持S3和Curve块混合存储,让数据根据冷热程度在S3与Curve块之间流动。curve-fuse的架构图如下:
curve-fuse架构图

curve-fuse包含几个主要模块:
- libfuse,对接了其lowlevel fuse api,支持fuse用户态文件系统;
- 元数据cache,包含fsinfo, inode cache, dentry cache, 实现对元数据的缓存;
- meta rpc client, 主要对接元数据集群,实现meta op的发送,超时重试等功能;
- S3 client, 通过对接S3接口,将数据存储在s3中;
- S3 data cache, 这是S3数据存储的缓存层,作为数据缓存,加速S3数据的读写性能;
- curve client 通过对接Curve块存储SDK,实现将数据存储在Curve块存储集群中;
- volume data cache,这是当数据存储在Curve块存储中的缓存层,以加速数据读写性能(开发中);
curve-fuse现已对接完整的fuse模块,基本实现POSIX的兼容,目前pjdtest测试通过率100%。
S3存储引擎支持
S3 client负责将文件的读写语义转换成S3存储的数据读写(upload,download)语义。考虑到S3存储性能较差,我们在这一层对数据做了级缓存:内存缓存(dataCache)和磁盘缓存(diskCache),整体架构如下:

S3ClientAdaptor主要包含以下几个模块:
- FsCacheManager:负责管理整个文件系统的缓存,包括inode到FileCacheManager的映射、读写cache大小统计和控制
- FileCacheManager:负责管理单个文件的缓存
- ChunkCacheManager:负责单个文件内某个chunk的缓存
- DataCache:缓存管理的最小粒度,对应一个chunk内一段连续的数据空间。数据最终在DataCache这一层映射为S3存储的一个或多个对象,进行upoload
- diskCache:负责本地磁盘缓存管理,数据持久化可以先写到本地磁盘上,再异步的写到S3存储上,能够有效的降低时延,提高吞吐
- S3Client:负责调用后端的S3存储接口,目前使用的是AWS的SDK
MDS
MDS是指元数据管理服务,CurveFS的MDS类似于CurveBS的MDS(CurveBS的MDS介绍:https://zhuanlan.zhihu.com/p/...),提供中心化的元数据管理服务。
CurveFS的MDS有以下功能:
- 通过topology子模块,管理的整个集群的topo信息,以及整个topo的生命周期管理
- 通过fs子模块,管理fs的super block信息;提供文件系统的创建,删除,挂卸载,查询等功能;负责fs的inode、dentry等元数据在metaserver的分布
- 通过heartbeat子模块,维持和metaserver的心跳,并收集metaserver的状态
- 通过调度系统进行调度。curvefs的元数据使用一致性协议保证可靠性,当出现某副本不可用的时候,调度器会自动的进行recover。调度功能正在开发中
作为一个中心化的元数据管理服务,其性能、可靠性、可用性也十分重要。
- 在性能上:首先,MDS上元数据都会全部缓存在内存里,加速其查找。其次,在fs创建之后,MDS会为fs分配用来保存inode、dentry信息的分片,在系统中,一个分片被称为一个partition。完成partition分配之后,fs的元数据操作会由client直接发向metaserver。此后的fs的inode、dentry的元数据管理并不经过MDS
- 在可靠性和可用性上:MDS的元数据持久化到etcd中,依靠3副本的etcd保证元数据的可靠性。可以选择部署多个MDS服务,但是同时之后有一个MDS对外提供服务,当主MDS因为特殊原因挂掉之后,会在自动的在剩下的MDS中,通过选主算法选择一个新的主MDS继续提供服务
MetaServer
MetaServer是分布式元数据管理系统,为客户端提供元数据服务。文件系统元数据进行分片管理,每个元数据分片以三副本的形式提供一致性保证,三个副本统称为Copyset,内部采用Raft一致性协议。同时,一个Copyset可以管理多个元数据分片。所以,整个文件系统的元数据管理如下所示:

图中共有两个Copyset,三个副本放置在三台机器上。P1/P2/P3/P4表示文件系统的元数据分片,其中P1/P3属于一个文件系统,P2/P4属于一个文件系统。
元数据管理
文件系统的元数据进行分片管理,每个分片称为Partition,Partition提供了对dentry和inode的增删改查接口,同时Partition管理的元数据全部缓存在内存中。
Inode对应文件系统中的一个文件或目录,记录相应的元数据信息,比如atime/ctime/mtime。当inode表示一个文件时,还会记录文件的数据寻址信息。每个Parition管理固定范围内的inode,根据inodeid进行划分,比如inodeid [1-200] 由Partition 1管理,inodeid [201-400] 由Partition 2管理,依次类推。
Dentry是文件系统中的目录项,记录文件名到inode的映射关系。一个父目录下所有文件/目录的dentry信息由父目录inode所在的Partition进行管理。
一致性
文件系统元数据分片以三副本形式存储,利用raft算法保证三副本数据的一致性,客户端的元数据请求都由raft leader进行处理。在具体实现层面,我们使用了开源的braft(https://github.com/baidu/braft),并且一台server上可以放置多个复制组,即multi-raft。
高可靠
高可用的保证主要来自两个方面。首先,raft算法保证了数据的一致性,同时raft心跳机制也可以做到在raft leader异常的情况下,复制组内的其余副本可以快速竞选leader,并对外提供服务。
其次,Raft基于Quorum的一致性协议,在三副本的情况下,只需要两副本存活即可 。但是长时间的两副本运行,对可用性也是一个考验。所以,我们在Metaserver与MDS之间加入了定时心跳,Metaserver会定期向MDS发送自身的统计信息,比如:内存使用率,磁盘容量,复制组信息等。当某个Metaserver进程退出后,复制组信息不再上报给MDS,此时MDS会发现一些复制组只有两副本存活,因此会通过心跳下发Raft配置变更请求,尝试将复制组恢复到正常三副本的状态。
全新的部署工具 CurveAdm
为了提升 Curve 的运维便利性,我们设计开发了 CurveAdm 项目,其主要用于部署和管理 Curve 集群,目前已支持部署 CurveFS(CurveBS 的支持正在开发中)。
项目地址:
https://github.com/opencurve/...
CurveFS部署流程:
https://github.com/opencurve/...
CurveAdm 的设计架构如下图所示:

- CurveAdm内嵌一个 SQLite(嵌入式数据库,所有 DB 为一个文件),用于保存集群的topology与每个service相关信息,包括serviceId、containerId等
- CurveAdm通过SSH登录目标机器,通过Docker CLI执行命令,对容器进行操控,容器所用镜像为Curve各个发行版,默认为latest最新版本
CurveAdm与之前的ansible部署工具相比较,具有如下几个优点:
- CurveAdm 支持跨平台运行,独立打包无其他依赖,可以一键安装,易用性较好
- Curve组件运行在容器里,解决组件依赖问题和发行版适配问题
- 使用golang开发,开发迭代速度快,可定制化程度高
- 可自助收集集群日志并打包加密上传给Curve团队,便于分析解决问题
- CurveAdm 本身支持一键自我更新,方便升级
目前已支持功能如下所示:

如果你对CurveAdm项目感兴趣,欢迎参与贡献(提交issue或需求、开发功能、编写文档等等)。
待解决问题
当前版本是CurveFS的第一个beta版本,不建议在生产环境使用,已知待解决的问题有:
- 暂不支持共享读写(开发中)
- 硬盘数据缓存空间管理策略、流控功能
- 随机读写性能问题:这是S3引擎的特点决定的,我们会进一步优化,比如采用并发分片上传、range读等
- 异常节点自动恢复功能(开发中)
- 回收站功能:误删数据可以找回并恢复
- 并发读写特性:后续会支持多节点共用文件系统同时读写
- 监控接入:使用prometheus收集监控信息,使用grafana进行展示
欢迎在GitHub上提交issue和bug,或者添加微信号opencurve邀请您入群交流。
后续版本展望
Curve整体项目的发布节奏通常为每半年一个大版本,每个季度一个小版本,CurveFS为一个比较大的全新版本,当前首发版本还有很多功能不完备,需要继续完善,下个大版本我们的主要开发目标为(可能会根据实际需求进行部分调整):
- CurveBS存储引擎支持
- 数据跨引擎生命周期管理
- CSI插件
- 部署工具完善
- 基于K8s集群部署:目前已经支持helm部署方式,后续将继续优化,支持更高等级的云原生运维级别
- 多写多读
- 运维工具优化(监控告警、问题定位)
- 回收站
- HDD场景适配优化
- NFS、S3、HDFS等兼容性
- 快照
如果有相关诉求可以与我们沟通交流。
Curve是什么
Curve的定位
定位:高性能、易运维、支持广泛场景的开源云原生软件定义存储系统。
愿景:好用的云原生软件定义存储。
CurveBS介绍
CurveBS是Curve云原生软件定义存储系统的核心组件之一,其具备高性能、高可靠、易运维等特点,可以与云原生场景良好适配实现存算分离架构。CurveFS后续也会支持使用CurveBS作为存储引擎,CurveBS的总体架构如下图所示:

详细的设计文档可参考往期文章:
http://www.opencurve.io/docs/...
https://github.com/opencurve/...
https://github.com/opencurve/...
https://zhuanlan.zhihu.com/p/...
近期规划
- PolarFS适配:已完成单pfsd+单CurveBS卷的对接,后续会支持多pfsd+单CurveBS卷特性,代码库:https://github.com/skypexu/po...
- ARM64平台适配:已完成基本功能测试,后续会进行性能优化和稳定性验证,代码库:https://github.com/opencurve/...
- FIO CurveBS engine:已支持,代码库:https://github.com/skypexu/fi...
- NVME/RDMA适配:近期会进行适配验证以及性能优化
- iSCSI接口支持:使用范围比较广泛,普适性较高,计划近期支持
- Raft优化:尝试优化Raft的日志管理、提升I/O并发度、支持follower读、Raft降级(3副本只有1副本存活仍然可对外服务)等
Curve更多信息详见:
- Curve项目主页:http://www.opencurve.io/
- 源码地址:https://github.com/opencurve/...
- Roadmap:https://github.com/opencurve/...
- 技术解读合集:https://zhuanlan.zhihu.com/p/...






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。