
Preface
DM supports online execution of DDL statements for sub-databases and tables (commonly known as Sharding DDL). In the previous article, we introduced the pessimistic mode, that is, when an upstream sub-table executes a certain DDL, the migration of this sub-table will be suspended, waiting for others All sub-tables have executed the same DDL before the DDL is executed downstream and data migration continues.
The advantage of the pessimistic coordination mode is that it can ensure that the data migrated downstream is error-free and can be compatible with most DDL statements. The disadvantage is that it will suspend data migration and is not conducive to gray-scale changes to upstream and significantly increase incremental data replication. Delay. Some customers may spend several months executing DDL on a single shard and only change the structure of other shards when satisfied. Under the pessimistic synchronization setting, the DML events of the test shards will be backlogged, and will not work normally after synchronization is restored. At the same time, the pessimistic mode also requires that all shards must execute DDL in the same order, otherwise it will cause the task to report an error and suspend.
For this reason, DM provides a new optimistic coordination mode. The DDL executed on a sub-table is automatically modified into a DDL statement compatible with other sub-tables and then immediately applied to the downstream, without blocking the migration of any DML executed by the sub-table. optimistic coordination mode is suitable for upstream grayscale update and release scenarios, or scenarios that are sensitive to synchronization delays in the process of upstream database table structure changes.
<center>The comparison between pessimistic and optimistic coordination<center>

principle
All DML of DM worker will be directly synchronized downstream (except in case of error).
DM worker embeds a small TiDB (commonly known as the schema tracker), which is used to record the table structure of each upstream sub-table. When receiving DDL from the upstream, it will update the table structure according to the execution result of the DDL in the schema tracker Transfer to the DM master. The DM master merges the received table structures of different shards into a DML composite structure compatible with all shards, that is, the union of different shard table structures (this process is similar to the JOIN statement in the SQL statement), and then according to the synthesis The difference between the table structure and the table structure sent by DM worker obtains the corresponding DDL statement (that is, the difference between the synthesized table structure and the original table structure), which is synchronized to the downstream.

(For specific design, please refer to [DM: Manage DDLs on Sharded Tables by Maximizing Schema Compatibility]
rule
The rule of optimistic DDL table structure merging is simply to define a partial order relationship for column attributes, sort the same column of different tables, and select the maximum element in the partial order relationship. For incomparable columns, an error is returned
- null < not null
- no default < default(x)
- varchar(x) < varchar(y), where x< y
- utf8 < utf8mb4
- char < varchar
- tinyint < smallint < mediumint < bigint
- …
For the column that does not exist or is deleted, we set it as the smallest column
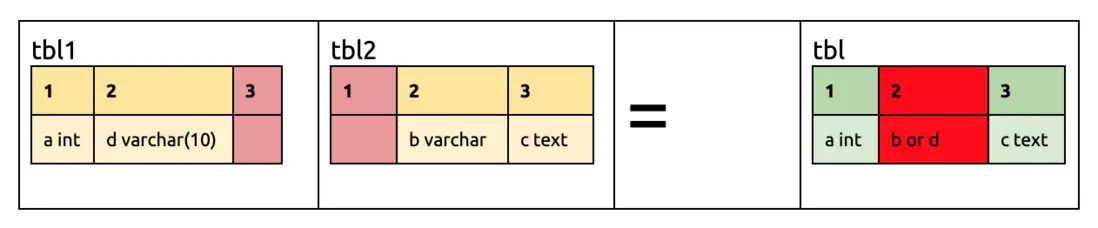
As the initial table structure is the same.

tbl2 adds the third column. The first two columns are the same; the third column of tbl1 is empty, so keep the third column of tbl2.

tbl2 deletes the first column. The second column is the same; the first column of tbl2 is empty, so keep the first column of tbl1. The third column of tbl1 is empty, so keep the third column of tbl2

tbl1 changes the second column to varchar(10), since varchar(5) <varchar(10), keep the second column of tbl1

tbl1 renames the second column. Now the names of the second column of tbl1 and tbl2 are different and cannot be compared. DM cannot determine the final table structure, so the task will report an error
example
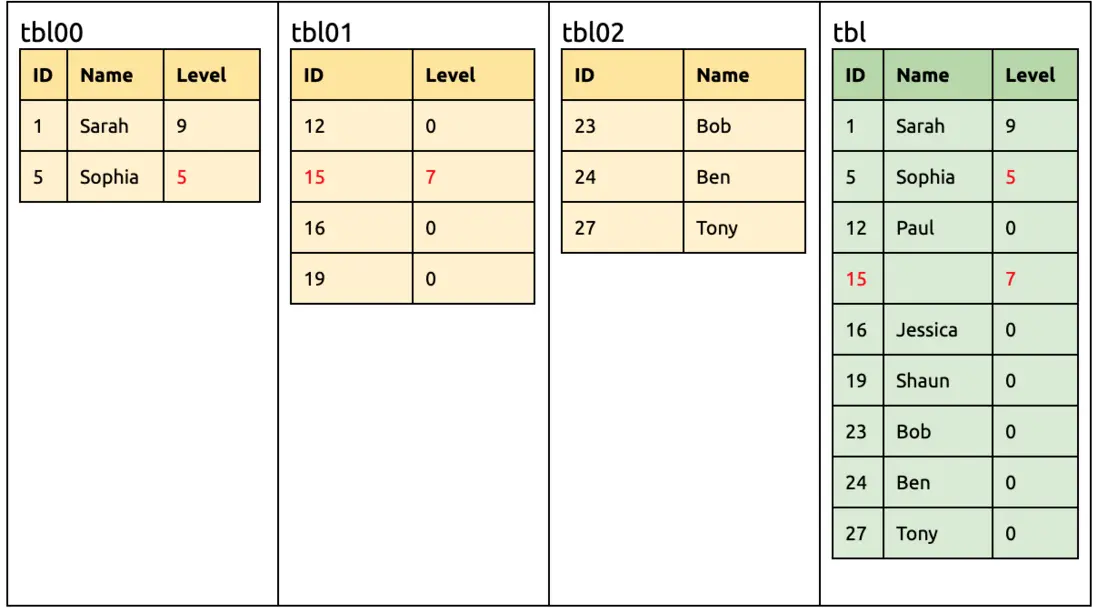
Three shards are merged and synchronized to TiDB

① Add a column of Level in the upstream.
alter table tbl00 add column Level int unsigned not null;

The union of tbl00, tbl01, and tbl02 tblMerge is {ID,NAME,Level}
The difference between tblMerge and tbl is {Level}, so DDL is add column Level
At this time, the downstream TiDB is ready to accept DML from tbl00 with Level and DML from tbl01 and tbl02 without Level, so when it synchronizes to the downstream, it will automatically rewrite it into the form of the specified default value.
alter table tbl add column Level int unsigned not null default 0;

At this time, various DMLs can be synchronized to the downstream without modification.
update tbl00 set Level = 9 where ID = 1;
insert into tbl02 (ID, Name) values (27, 'Tony');

② Add a column of Level to tbl01 as well.
alter table tbl01 add column Level int unsigned not null;

The union of tbl00, tbl01, and tbl02 tblMerge is {ID,NAME,Level}
The difference between tblMerge and tbl is {}, so DDL is empty
At this time, the downstream already has the same Level column, so the DM master does not take any action after the comparison.
③ Delete a column of Name in tbl01.
alter table tbl01 drop column Name;

The union of tbl00, tbl01, and tbl02 tblMerge is {ID,NAME,Level}
The difference between tblMerge and tbl is {Level}, so DDL is empty
At this time, the downstream still needs to receive DMLs containing Name from tbl00 and tbl02, so they are not deleted immediately, but a default value is also added to this column.
alter table tbl alter column Name set default “”;
Similarly, various DMLs can still be synchronized directly downstream.
insert into tbl01 (ID, Level) values (15, 7);
update tbl00 set Level = 5 where ID = 5;
④ Add a column of Level to tbl02.
The union of tbl00, tbl01, and tbl02 tblMerge is {ID,NAME,Level}
The difference between tblMerge and tbl is {Level}, so DDL is empty
alter table tbl02 add column Level int unsigned not null;

At this time, all shards already have the Level column, so you can remove it as a compatible default value.
alter table tbl alter column Level drop default;
⑤⑥ Delete one column of Name in tbl00 and tbl02.
alter table tbl00 drop column Name;
alter table tbl02 drop column Name;

The union of tbl00, tbl01, tbl02 tblMerge is {ID,Level}
The difference between tblMerge and tbl is -{Name}, this difference is signed, so DDL is drop column Name
At this point, the Name column has disappeared from all shards, so it can be safely removed downstream.
alter table tbl drop column Name;

limit
uses the "optimistic coordination" mode to have certain risks, and the following guidelines need to be strictly followed:
- Before and after executing the DDL of each batch, make sure that the structure of each sub-table is agreed upon.
- When performing grayscale DDL, it is best to focus on only one sub-meter to test.
After the grayscale is completed, try to migrate to the final schema with the simplest and direct DDL on other sub-tables, instead of re-executing each step of the grayscale test that is right or wrong.
- For example: ADD COLUMN A INT; DROP COLUMN A; ADD COLUMN A FLOAT; has been executed in a sub-table, and ADD COLUMN A FLOAT can be executed directly in other sub-tables, and there is no need to execute all three DDLs.
- Pay attention to observe the DM migration status when executing DDL. When a migration error is reported, it is necessary to determine whether this batch of DDL will cause data inconsistency.
For a more detailed introduction, please refer to official website document






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。