

background
The previous articles are all about the previously mentioned low-code platform.

This large project takes low code as the core, including editor front-end, editor back-end, C-end H5, component library, component platform, back-end management system front-end, back-end management system back-end, statistical service, self-developed CLI nine systems .
Today, let’s about the 161c9334f2a665 statistical service: the main purpose is to realize the sub-channel statistics of the H5 page (in fact, it is not only the sub-channel statistics, the core is to create a custom event statistics service, but there is currently a demand for sub-channel statistics. ) To view the specific PV situation of each channel. (The details will be reflected on the url, with the page name, id, channel type, etc.)
Let's put down the overall flow chart first:
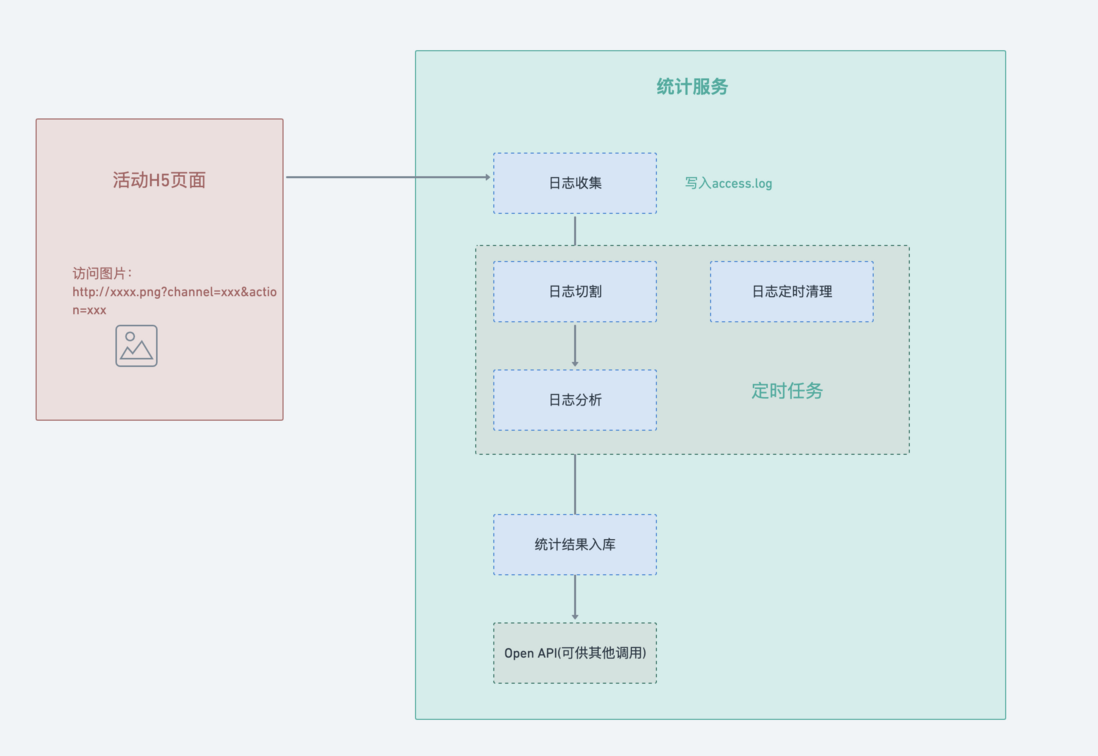
Log collection
Common log collection methods include manual burying and automatic burying. Here we do not focus on how to collect logs, but how to send the collected logs to the server.
In common burying schemes, sending burying requests through pictures is often adopted, and it has many advantages:
- No cross-domain
- small volume
- Able to complete the entire HTTP request + response (although the response content is not required)
- No blocking during execution
Here is the scenario in nginx put on a 1px * 1px still pictures, and then by accessing the picture ( http://xxxx.png?env=xx&event=xxx ), and Buried data on query on the parameters, in order to bury data point falls nginx log.
iOS will limit the length of the url of the get request, but we don’t send too much data in the real scenario, so this solution is temporarily adopted.
Here is a brief explanation of why the query key picture address is designed like this. If it is purely for statistical channels and works, it is very likely that key will be designed as channel , workId , but as mentioned above, we want to make a custom event For statistical services, the scalability of the fields should be considered, and the fields should have more general semantics. So referring to the design of many statistical services, the fields used here are:
- env
- event
- key
- value
After each visit to the page, nginx will automatically record the log to access_log .
With the log, let's see how to split it.
Log split
Why split the log
access.log log does not split by default, the more will accumulate more, system disk space will be consumed more and more in the future may face a log write fails, abnormal service issues.
Too much content in the log file makes it difficult to troubleshoot and analyze subsequent problems.
Therefore, the log split is necessary and necessary.
How to split the log
Our core idea of splitting the log here is: access.log rename it to a new log file, and then clear the old log file.
Depending on the traffic conditions (the greater the traffic, the faster the log files accumulate), split by day, hour, and minute. You can split access.log into a folder by day.
log_by_day/2021-12-19.log
log_by_day/2021-12-20.log
log_by_day/2021-12-21.logBut the above copy -> empty operation must be automatically processed, here you need to start a scheduled task, at a fixed time every day (I am here at 00:00 every day) to process.
Timed task
In fact, timed tasks will not only be used during log splitting, but will be used for log analysis and log clearing later. Here is a brief introduction. Eventually, splitting, analysis and clearing will be integrated.
linux built cron process is timed to handle the task. In node , we generally use node-schedule or cron to handle timing tasks.
Here is cron :
/**
cron 定时规则 https://www.npmjs.com/package/cron
* * * * * *
┬ ┬ ┬ ┬ ┬ ┬
│ │ │ │ │ │
│ │ │ │ │ └ day of week (0 - 6) (Sun-Sat)
│ │ │ │ └───── month (1 - 12)
│ │ │ └────────── day of month (1 - 31)
│ │ └─────────────── hour (0 - 23)
│ └──────────────────── minute (0 - 59)
└───────────────────────── second (0 - 59)
*/The specific usage will not be explained.
coding
With the above reserves, I will write this piece of code below. First, I will sort out the logic:
1️⃣ Read the source file access.log
2️⃣ Create a split folder (need to be created automatically if it does not exist)
3️⃣ Create log file (day dimension, need to be created automatically if it does not exist)
4️⃣ Copy source log to new file
5️⃣ Clear access.log
/**
* 拆分日志文件
*
* @param {*} accessLogPath
*/
function splitLogFile(accessLogPath) {
const accessLogFile = path.join(accessLogPath, "access.log");
const distFolder = path.join(accessLogPath, DIST_FOLDER_NAME);
fse.ensureDirSync(distFolder);
const distFile = path.join(distFolder, genYesterdayLogFileName());
fse.ensureFileSync(distFile);
fse.outputFileSync(distFile, ""); // 防止重复,先清空
fse.copySync(accessLogFile, distFile);
fse.outputFileSync(accessLogFile, "");
}Log analysis
Log analysis is to read the files that have been split in the previous step, and then process and store them in accordance with certain rules. Here is a very important point to mention: node readFile when dealing with large files or unknown memory file size, it will break the V8 memory limit. It is this situation that is taken into account, so the way to read the log file here should be: createReadStream Create a readable stream to readline read and process line by line
readline
readline module provides an interface for reading data one line at a time from the readable stream. It can be accessed in the following ways:
const readline = require("readline");readline is also very simple: create an interface instance and pass in the corresponding parameters:
const readStream = fs.createReadStream(logFile);
const rl = readline.createInterface({
input: readStream,
});Then listen to the corresponding event:
rl.on("line", (line) => {
if (!line) return;
// 获取 url query
const query = getQueryFromLogLine(line);
if (_.isEmpty(query)) return;
// 累加逻辑
// ...
});
rl.on("close", () => {
// 逐行读取结束,存入数据库
const result = eventData.getResult();
resolve(result);
});line and close events are used here:
lineevent: whenever the input stream receives end-of-line input (\n, \r or \r\n), the'line' event will be triggeredcloseevent: This event is generally triggered at the end of the transmission
Analyze log results line by line
Knowing the readline , let us analyze the log results line by line.
First look at the format of the log in access.log

We take one of the lines to analyze:
127.0.0.1 - - [19/Feb/2021:15:22:06 +0800] "GET /event.png?env=h5&event=pv&key=24&value=2 HTTP/1.1" 200 5233 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36" "-"We want to get is url of query part, is what we in h5 data in a custom.
It can be matched by regular:
const reg = /GET\s\/event.png\?(.+?)\s/;
const matchResult = line.match(reg);
console.log("matchResult", matchResult);
const queryStr = matchResult[1];
console.log("queryStr", queryStr);The print result is:
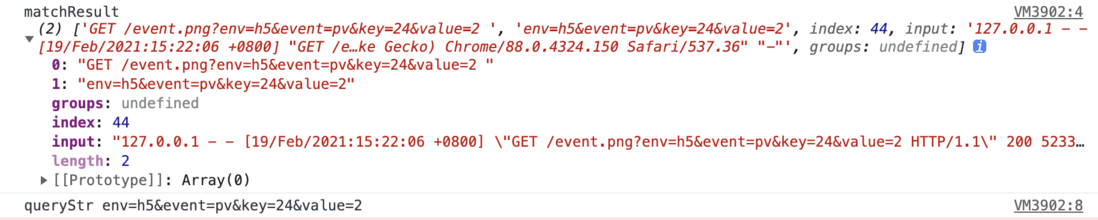
queryStr can be processed by node in querystring.parse() :
const query = querystring.parse(queryStr);
console.log('query', query)
{
env: 'h5',
event: 'pv',
key: '24',
value: '2'
}All that is left is to accumulate the data.
But how to do accumulation, we have to think about it. At the beginning, we said that we should do sub-channel statistics. Then the final result should clearly see two data:
- Data from all channels
- Separate data for each channel
Only this kind of data is valuable for operations, and the quality of the data directly determines the intensity of subsequent deployment in each channel.
Here I refer to the Google Analytics of multi-channel funnel , and record the data of each dimension from top to bottom, so that you can clearly know the situation of each channel.
The specific implementation is not troublesome, let's first look at the useful data just obtained from a link:
{
env: 'h5',
event: 'pv',
key: '24',
value: '2'
}env here represents the environment. The statistics here are all from the h5 page, so env is h5 , but for expansion, this field is set.
event represents the name of the event, here is mainly for statistics visits, so it is pv .
key is the work id.
value is the channel code, currently mainly include: 1-WeChat, 2-Xiaohongshu, 3- Douyin.
Let's take a look at the results of the final statistics:
{
date: '2021-12-21',
key: 'h5',
value: { num: 1276}
}
{
date: '2021-12-21',
key: 'h5.pv',
value: { num: 1000}
}
{
date: '2021-12-21',
key: 'h5.pv.12',
value: { num: 200}
}
{
date: '2021-12-21',
key: 'h5.pv.12.1',
value: { num: 56}
}
{
date: '2021-12-21',
key: 'h5.pv.12.2',
value: { num: 84}
}
{
date: '2021-12-21',
key: 'h5.pv.12.3',
value: { num: 60}
}2021-12-21 was intercepted. Let me analyze the wave for everyone:
1️⃣ h5: The total number of custom events reported on the h5 page that day is 1276
2️⃣ h5.pv: where all pv (that is, h5.pv) is 1000
3️⃣ h5.pv.12: The pv whose work id is 12 has a total of 200
4️⃣ h5.pv.12.1: The pv of the WeChat channel whose work id is 12 is 56
5️⃣ h5.pv.12.2: The pv of the Xiaohongshu channel whose work id is 12 is 84
6️⃣ h5.pv.12.2: The pv of the TikTok channel whose work id is 12 is 60
In this way, you can clearly get the access status of a certain work in a certain channel on a certain day, and then use these data as the support to make a visual report, and the effect will be clear at a glance.
Statistic result storage
At present, this part of the data is placed in mongoDB . Regarding the use of mongoDB node , I will not go into it. If you are unfamiliar, please refer to my other article Koa2+MongoDB+JWT Actual Combat--Restful API Best Practice
Post model here:
/**
* @description event 数据模型
*/
const mongoose = require("../db/mongoose");
const schema = mongoose.Schema(
{
date: Date,
key: String,
value: {
num: Number,
},
},
{
timestamps: true,
}
);
const EventModel = mongoose.model("event_analytics_data", schema);
module.exports = EventModel;Log deletion
As the page continues to be accessed, log files will increase rapidly, and the value of log files that exceed a certain period of time is not very large, so we need to clear log files regularly.
This is actually relatively simple, traversing the files, because the file names are named after the date (format: 2021-12-14.log ), so as long as the time interval is judged to be greater than 90 days, the log file will be deleted.
Post the core implementation:
// 读取日志文件
const fileNames = fse.readdirSync(distFolder);
fileNames.forEach((fileName) => {
try {
// fileName 格式 '2021-09-14.log'
const dateStr = fileName.split(".")[0];
const d = new Date(dateStr);
const t = Date.now() - d.getTime();
if (t / 1000 / 60 / 60 / 24 > 90) {
// 时间间隔,大于 90 天,则删除日志文件
const filePath = path.join(distFolder, fileName);
fse.removeSync(filePath);
}
} catch (error) {
console.error(`日志文件格式错误 ${fileName}`, error);
}
});Timing task integration
At this point, the log splitting, analysis and clearing are all finished, now we need to integrate them cron
First, create a timed task:
function schedule(cronTime, onTick) {
if (!cronTime) return;
if (typeof onTick !== "function") return;
// 创建定时任务
const c = new CronJob(
cronTime,
onTick,
null, // onComplete 何时停止任务
true, // 初始化之后立刻执行
"Asia/Shanghai" // 时区
);
// 进程结束时,停止定时任务
process.on("exit", () => c.stop());
}Then each stage is processed in a different time stage (timing split -> timing analysis -> timing deletion)
Timed split
function splitLogFileTiming() {
const cronTime = "0 0 0 * * *"; // 每天的 00:00:00
schedule(cronTime, () => splitLogFile(accessLogPath));
console.log("定时拆分日志文件", cronTime);
}Timed analysis and storage
function analysisLogsTiming() {
const cronTime = "0 0 3 * * *"; // 每天的 3:00:00 ,此时凌晨,访问量较少,服务器资源处于闲置状态
schedule(cronTime, () => analysisLogsAndWriteDB(accessLogPath));
console.log("定时分析日志并入库", cronTime);
}Timed delete
function rmLogsTiming() {
const cronTime = "0 0 4 * * *"; // 每天的 4:00:00 ,此时凌晨,访问量较少,服务器资源处于闲置状态
schedule(cronTime, () => rmLogs(accessLogPath));
console.log("定时删除过期日志文件", cronTime);
}Then call it in order at the application entrance:
// 定时拆分日志文件
splitLogFileTiming();
// 定时分析日志并入库
analysisLogsTiming();
// 定时删除过期日志文件
rmLogsTiming();Summarize
Ok, here, a simple statistical service is complete.






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。