

背景
之前的几篇文章都是关于之前提到的低代码平台的。

这个大的项目以 low code 为核心,囊括了编辑器前端、编辑器后端、C 端 H5、组件库、组件平台、后台管理系统前端、后台管理系统后台、统计服务、自研 CLI 九大系统。
今天就来说一下其中的统计服务:目的主要是为了实现 H5 页面的分渠道统计(其实不仅仅是分渠道统计,核心是想做一个自定义事件统计服务,只是目前有分渠道统计的需求),查看每个渠道具体的 PV 情况。(具体会在 url 上面体现,会带上页面名称、id、渠道类型等)
先放一下整体流程图吧:
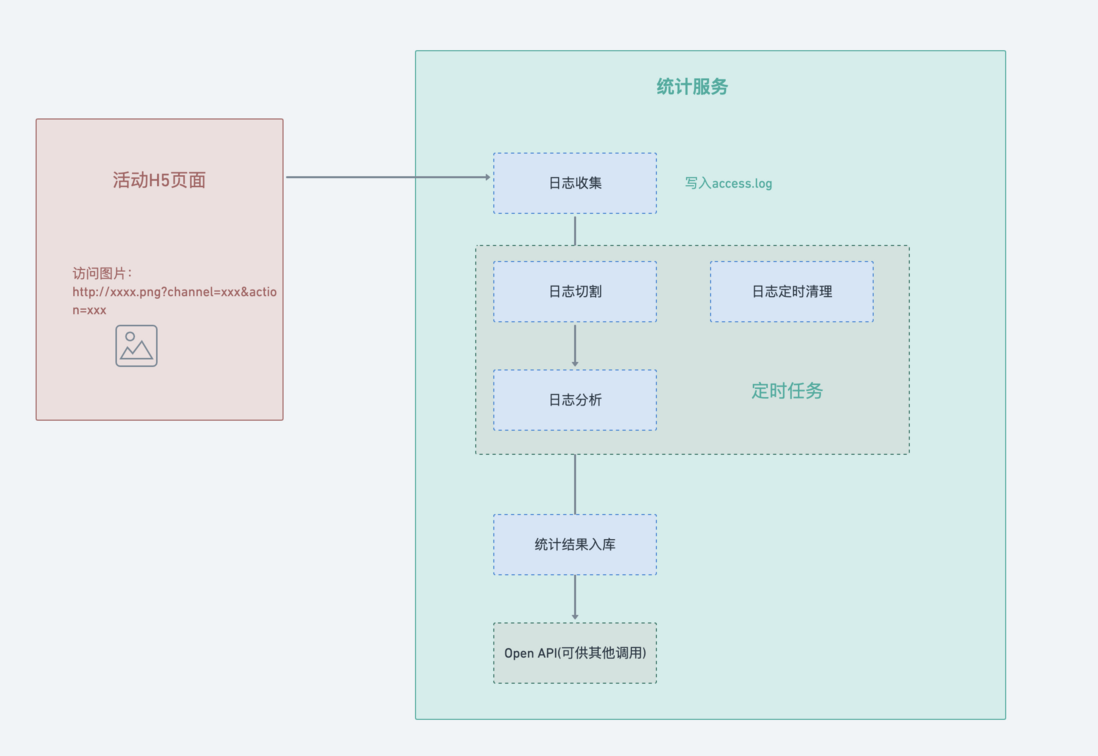
日志收集
常见的日志收集方式有手动埋点和自动埋点,这里我们不关注于如何收集日志,而是如何将收集的日志的发送到服务器。
在常见的埋点方案中,通过图片来发送埋点请求是一种经常被采纳的,它有很多优势:
- 没有跨域
- 体积小
- 能够完成整个 HTTP 请求+响应(尽管不需要响应内容)
- 执行过程无阻塞
这里的方案就是在 nginx 上放一张 1px * 1px 的静态图片,然后通过访问该图片(http://xxxx.png?env=xx&event=xxx),并将埋点数据放在query参数上,以此将埋点数据落到nginx日志中。
iOS 上会限制 get 请求的 url 长度,但我们这里真实场景发送的数据不会太多,所以目前暂时采用这种方案
这里简单阐述一下为什么图片地址的query key 要这么设计,如果单纯是为了统计渠道和作品,很有可能会把key设计为channel、workId这种,但上面也说到了,我们是想做一个自定义事件统计服务,那么就要考虑字段的可扩展性,字段应更有通用语义。所以参考了很多统计服务的设计,这里采用的字段为:
- env
- event
- key
- value
之后每次访问页面,nginx就会自动记录日志到access_log中。
有了日志,下面我们来看下如何来对其进行拆分。
日志拆分
为何要拆分日志
access.log日志默认不会拆分,会越积累越多,系统磁盘的空间会被消耗得越来越多,将来可能面临着日志写入失败、服务异常的问题。
日志文件内容过多,对于后续的问题排查和分析也会变得很困难。
所以日志的拆分是有必要也是必须的。
如何拆分日志
我们这里拆分日志的核心思路是:将当前的access.log复制一份重命名为新的日志文件,之后清空老的日志文件。
视流量情况(流量越大日志文件积累的越快),按天、小时、分钟来拆分。可以把access.log按天拆分到某个文件夹中。
log_by_day/2021-12-19.log
log_by_day/2021-12-20.log
log_by_day/2021-12-21.log但上面的复制 -> 清空操作肯定是要自动处理的,这里就需要启动定时任务,在每天固定的时间(我这里是在每天凌晨 00:00)来处理。
定时任务
其实定时任务不仅在日志拆分的时候会用到,在后面的日志分析和日志清除都会用到,这里先简单介绍一下,最终会整合拆分、分析和清除。
linux中内置的cron进程就是来处理定时任务的。在node中我们一般会用node-schedule或cron来处理定时任务。
这里使用的是cron:
/**
cron 定时规则 https://www.npmjs.com/package/cron
* * * * * *
┬ ┬ ┬ ┬ ┬ ┬
│ │ │ │ │ │
│ │ │ │ │ └ day of week (0 - 6) (Sun-Sat)
│ │ │ │ └───── month (1 - 12)
│ │ │ └────────── day of month (1 - 31)
│ │ └─────────────── hour (0 - 23)
│ └──────────────────── minute (0 - 59)
└───────────────────────── second (0 - 59)
*/具体使用方式就不展开说明了。
编码
有了上面这些储备,下面我就来写一下这块代码,首先梳理下逻辑:
1️⃣ 读取源文件 access.log
2️⃣ 创建拆分后的文件夹(不存在时需自动创建)
3️⃣ 创建日志文件(天维度,不存在时需自动创建)
4️⃣ 拷贝源日志至新文件
5️⃣ 清空 access.log
/**
* 拆分日志文件
*
* @param {*} accessLogPath
*/
function splitLogFile(accessLogPath) {
const accessLogFile = path.join(accessLogPath, "access.log");
const distFolder = path.join(accessLogPath, DIST_FOLDER_NAME);
fse.ensureDirSync(distFolder);
const distFile = path.join(distFolder, genYesterdayLogFileName());
fse.ensureFileSync(distFile);
fse.outputFileSync(distFile, ""); // 防止重复,先清空
fse.copySync(accessLogFile, distFile);
fse.outputFileSync(accessLogFile, "");
}日志分析
日志分析就是读取上一步拆分好的文件,然后按照一定规则去处理、落库。这里有一个很重要的点要提一下:node在处理大文件或者未知内存文件大小的时候千万不要使用readFile,会突破 V8 内存限制。正是考虑到这种情况,所以这里读取日志文件的方式应该是:createReadStream创建一个可读流交给 readline 逐行读取处理
readline
readline 模块提供了用于从可读流每次一行地读取数据的接口。 可以使用以下方式访问它:
const readline = require("readline");readline 的使用也非常简单:创建一个接口实例,传入对应的参数:
const readStream = fs.createReadStream(logFile);
const rl = readline.createInterface({
input: readStream,
});然后监听对应事件即可:
rl.on("line", (line) => {
if (!line) return;
// 获取 url query
const query = getQueryFromLogLine(line);
if (_.isEmpty(query)) return;
// 累加逻辑
// ...
});
rl.on("close", () => {
// 逐行读取结束,存入数据库
const result = eventData.getResult();
resolve(result);
});这里用到了line和close事件:
line事件:每当 input 流接收到行尾输入(\n、\r 或 \r\n)时,则会触发 'line' 事件close事件:一般在传输结束时会触发该事件
逐行分析日志结果
了解了readline 的使用,下面让我们来逐行对日志结果进行分析吧。
首先来看下access.log中日志的格式:

我们取其中一行来分析:
127.0.0.1 - - [19/Feb/2021:15:22:06 +0800] "GET /event.png?env=h5&event=pv&key=24&value=2 HTTP/1.1" 200 5233 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36" "-"我们要拿到的就是url的query部分,也就是我们在h5中自定义的数据。
通过正则匹配即可:
const reg = /GET\s\/event.png\?(.+?)\s/;
const matchResult = line.match(reg);
console.log("matchResult", matchResult);
const queryStr = matchResult[1];
console.log("queryStr", queryStr);打印结果为:
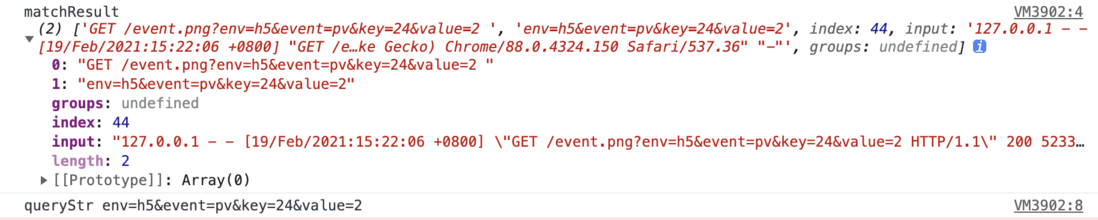
queryStr可通过node中的querystring.parse()来处理:
const query = querystring.parse(queryStr);
console.log('query', query)
{
env: 'h5',
event: 'pv',
key: '24',
value: '2'
}剩下的就是对数据做累加处理了。
但如何去做累加,我们要想一下,最开始也说了是要去做分渠道统计,那么最终的结果应该可以清晰的看到两个数据:
- 所有渠道的数据
- 每个渠道单独的数据
只有这样的数据对于运营才是有价值的,数据的好坏也直接决定了后面在每个渠道投放的力度。
这里我参考了 Google Analytics中的多渠道漏斗的概念,由上到下分维度记录每个维度的数据,这样就可以清晰的知道每个渠道的情况了。
具体实现也不麻烦,我们先来看下刚刚从一条链接中得到的有用数据:
{
env: 'h5',
event: 'pv',
key: '24',
value: '2'
}这里的env代表环境,这里统计的都是来源于h5页面,所以env为h5,但是为了扩展,所以设置了这个字段。
event表示事件名称,这里主要是统计访问量,所以为pv。
key是作品 id。
value是渠道 code,目前主要有:1-微信、2-小红书、3-抖音。
再来看下最终统计得到的结果吧:
{
date: '2021-12-21',
key: 'h5',
value: { num: 1276}
}
{
date: '2021-12-21',
key: 'h5.pv',
value: { num: 1000}
}
{
date: '2021-12-21',
key: 'h5.pv.12',
value: { num: 200}
}
{
date: '2021-12-21',
key: 'h5.pv.12.1',
value: { num: 56}
}
{
date: '2021-12-21',
key: 'h5.pv.12.2',
value: { num: 84}
}
{
date: '2021-12-21',
key: 'h5.pv.12.3',
value: { num: 60}
}这是截取了2021-12-21当天的数据,我给大家分析一波:
1️⃣ h5:当天 h5 页面的自定义事件上报总数为 1276
2️⃣ h5.pv:其中 所有 pv(也就是 h5.pv)为 1000
3️⃣ h5.pv.12:作品 id 为 12 的 pv 一共有 200
4️⃣ h5.pv.12.1:作品 id 为 12 的在微信渠道的 pv 为 56
5️⃣ h5.pv.12.2:作品 id 为 12 的在小红书渠道的 pv 为 84
6️⃣ h5.pv.12.2:作品 id 为 12 的在抖音渠道的 pv 为 60
这样就能清楚的得到某一天某个作品在某条渠道的访问情况了,后续再以这些数据为支撑做成可视化报表,效果就一目了然了。
统计结果入库
目前这部分数据是放在了mongoDB中,关于node中使用mongoDB就不展开说了,不熟悉的可以参考我另外一篇文章Koa2+MongoDB+JWT 实战--Restful API 最佳实践
这里贴下model吧:
/**
* @description event 数据模型
*/
const mongoose = require("../db/mongoose");
const schema = mongoose.Schema(
{
date: Date,
key: String,
value: {
num: Number,
},
},
{
timestamps: true,
}
);
const EventModel = mongoose.model("event_analytics_data", schema);
module.exports = EventModel;日志删除
随着页面的持续访问,日志文件会快速增加,超过一定时间的日志文件存在的价值也不是很大,所以我们要定期清除日志文件。
这个其实比较简单,遍历文件,因为文件名都是以日期命名的(格式:2021-12-14.log),所以只要判断时间间隔大于 90 天就删除日志文件。
贴一下核心实现:
// 读取日志文件
const fileNames = fse.readdirSync(distFolder);
fileNames.forEach((fileName) => {
try {
// fileName 格式 '2021-09-14.log'
const dateStr = fileName.split(".")[0];
const d = new Date(dateStr);
const t = Date.now() - d.getTime();
if (t / 1000 / 60 / 60 / 24 > 90) {
// 时间间隔,大于 90 天,则删除日志文件
const filePath = path.join(distFolder, fileName);
fse.removeSync(filePath);
}
} catch (error) {
console.error(`日志文件格式错误 ${fileName}`, error);
}
});定时任务整合
到这里,日志的拆分、分析和清除都说完了,现在要用cron来对他们做整合了。
首先来创建定时任务:
function schedule(cronTime, onTick) {
if (!cronTime) return;
if (typeof onTick !== "function") return;
// 创建定时任务
const c = new CronJob(
cronTime,
onTick,
null, // onComplete 何时停止任务
true, // 初始化之后立刻执行
"Asia/Shanghai" // 时区
);
// 进程结束时,停止定时任务
process.on("exit", () => c.stop());
}然后每一阶段都在不同的时间阶段去处理(定时拆分 -> 定时分析 -> 定时删除)
定时拆分
function splitLogFileTiming() {
const cronTime = "0 0 0 * * *"; // 每天的 00:00:00
schedule(cronTime, () => splitLogFile(accessLogPath));
console.log("定时拆分日志文件", cronTime);
}定时分析并入库
function analysisLogsTiming() {
const cronTime = "0 0 3 * * *"; // 每天的 3:00:00 ,此时凌晨,访问量较少,服务器资源处于闲置状态
schedule(cronTime, () => analysisLogsAndWriteDB(accessLogPath));
console.log("定时分析日志并入库", cronTime);
}定时删除
function rmLogsTiming() {
const cronTime = "0 0 4 * * *"; // 每天的 4:00:00 ,此时凌晨,访问量较少,服务器资源处于闲置状态
schedule(cronTime, () => rmLogs(accessLogPath));
console.log("定时删除过期日志文件", cronTime);
}然后在应用入口按序调用即可:
// 定时拆分日志文件
splitLogFileTiming();
// 定时分析日志并入库
analysisLogsTiming();
// 定时删除过期日志文件
rmLogsTiming();总结
ok,到这里,一个简易的统计服务就完成了。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。