
This article is based on the content of Mr. Li live speech 2021 vivo Developer Conference 161e61828bdf75". Reply to the [2021VDC] obtain relevant information on the topics of the Internet technology sub-venue.
1. Introduction of vivo push platform
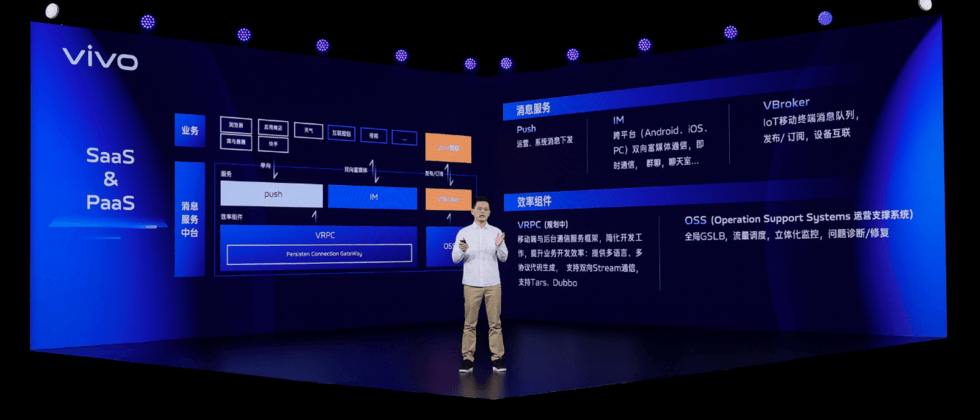
1.1 Understand the push platform from product and technology perspectives
What does a push platform do?
Some friends may have known it before, and some may have encountered it for the first time. No matter what kind of situation you are in, I hope that through today's sharing, you can have a new understanding of us. Next, I will introduce the vivo push platform from two different perspectives of product and technology.

First of all, from the product point of view, the vivo push platform is deeply integrated with the system to establish a stable, reliable, safe and controllable message push service that supports a push speed of 100w per second and hundreds of millions of users are online at the same time, helping developers in different industries to explore more operational value. The core capability of the push platform is to use the long connection technology to provide users with real-time, two-way content and service transmission capabilities using smart devices and mobile phones as carriers.
So if you are an operator, you can consider using our push platform to operate your APP on vivo mobile phone system to improve the activity and retention of your APP. What is the essence of the push platform?

From a technical point of view, we are a platform that sends messages to users through a long TCP connection. Therefore, the essence of the push platform is to send messages to user devices through network channels.
Everyone has received the express notification every day! When the courier puts the courier in the courier cabinet, the courier background will automatically push a message to notify you that there is a courier. I believe that if you are an operator, you will also like this efficient way of automatically sending messages. If you are interested, you can learn more about us through the portal of vivo open platform and select the message push after the sharing is over.

1.2 Contents, Services, and Device Interconnection
In this era of the Internet of Everything, our platform also has the ability to connect multiple times. We connect content, services, and users through long-term connections, distribute content to users, and provide real-time, two-way communication capabilities for terminal devices.
There is a concept of long connection here, so what is a long connection? The so-called long connection is a network connection maintained by the client and the server, which can carry out network communication for a relatively long period of time (for example, a long connection based on TCP).
Why do we use long connections instead of short connections as the underlying network communication of the platform.
Let's first take a look at the scenario of message delivery under short connection: the method of using short connection is polling, that is, the client periodically asks the background whether there is a message from device A, and when there is a message from device A, the background returns the corresponding message , in many cases, it may be ineffective and waste traffic; when there is a message in the background that needs to be sent to device A, the message cannot be sent because device A has not come to fetch it. With a long connection, when there is a message from device A, the background directly sends it to device A without waiting for device A to pull it by itself, so the long connection makes data interaction more natural and efficient; in addition, our platform is technically equipped with The following advantages:

- More than 100 million devices are online at the same time;
- Support millions of push speeds per second;
- Support daily message throughput exceeding 10 billion levels;
- Real-time push effect analysis;
- Real-time audit of all push messages.
These capabilities of our push platform can guarantee the timeliness of messages. These capabilities of our platform have been continuously evolved. Next, I will share with you the changes in the architecture of the vivo push platform in recent years.
2. The evolution of vivo push platform architecture
2.1 Embrace business
The architecture in the IT field is dynamic and may change at different stages. The driving force for the evolution of the architecture mainly comes from business requirements. Next, let’s review the business development process of our platform.

Since the establishment of the project in 2015, with the growth of business volume, we have continued to add to the system, enriching the capabilities of the entire system to meet the needs of different business scenarios. For example, it supports full content review, IM, IoT, and WebSocket communication.
As can be seen from the figure, our business volume has grown by billions almost every year, and the continuous increase has brought challenges to the system. Problems existing in the original system architecture have gradually surfaced, such as delays and performance bottlenecks. . The architecture serves the business. Before 2018, all the services of our platform were placed on the cloud, but other internal services we depended on were deployed in the self-built computer room.

2.2 The courage to change
With the growth of business volume and data transmission in the self-built computer room, the problem of delay has occurred, and it is gradually worsening, which is not conducive to the expansion of our platform functions. Therefore, in the second half of 2018, we adjusted the deployment architecture: all core logic modules were migrated to the self-built computer room. After the architecture was optimized, the data delay problem was completely solved. It also lays the foundation for further evolution of the architecture. From the above figure, we can see that our access gateway is also optimized for deployment in three places.
Why do three-site deployments instead of more regional deployments? Mainly based on the following three considerations:
- The first is based on the consideration of user distribution and cost;
- The second is to provide users with nearby access;
- The third is to enable the access gateway to have a certain disaster tolerance capability.
You can imagine that if there is no deployment in three places, when the access gateway computer room fails, then our platform will be paralyzed.
With the further expansion of the business scale of our platform, the daily throughput has reached the order of 1 billion, and users have higher and higher requirements for timeliness and concurrency, and the system architecture of our logical service in 2018 has been unable to meet the requirements of high business concurrency or Higher server costs are required to meet high concurrency demands. Therefore, starting from platform function and cost optimization, we reconstructed the system in 2019 to provide users with richer product functions and a more stable and higher-performance platform.
2.3 Empowering business with long connection capability

As the company's larger-scale long-term connection service platform, we have accumulated a wealth of long-term connection experience. We have also been thinking about how to enable long-term connectivity to empower more businesses. Each module of our platform server is called through RPC, which is a very efficient development mode, and every developer does not need to care about the underlying network layer data packets.
We imagine that if the client can also call the background through RPC, this must be a great development experience. In the future, we will provide a VRPC communication framework to solve the communication and development efficiency problems between the client and the background, and provide a consistent development experience for the client and the background, so that more developers will no longer care about network communication issues and concentrate on developing business logic. .
3. System stability, high performance and security
As a push platform with a throughput of more than 10 billion, its stability, high performance, and security are very important. Then I will share with you our practical experience in system stability, high performance, and security.

As can be seen from the domain model in the above figure, our push platform takes communication services as the core capability. On the basis of the core capabilities, we also provide big data services and operating systems, and provide different functions and services through different interfaces. The stability and performance of a push platform centered on communication services will affect the timeliness of messages. The timeliness of a message refers to the time it takes for a message to be received by the device that is initiated by the business party. So how to measure the timeliness of a message?
3.1 Monitoring and Quality Metrics

The traditional message timeliness measurement method is shown in the figure on the left. The sender and the receiver are on two devices. The time t1 is taken when the message is sent, and the time t2 is taken when the message is received. The two times are subtracted to obtain the message. time consuming. But this method is not rigorous, why? Because the time bases of the two devices are likely to be inconsistent. The solution we adopted is shown in the figure on the right, which puts the sender and receiver on the same device, so that the problem of time reference can be solved. Based on this solution, we built a dialing and testing system to actively monitor the time-consuming distribution of message delivery.
3.2 High-performance and stable long-connection gateway
In the past 10 years, when discussing the long connection performance of a single machine, we have faced the problem of 10,000 connections per machine. As a platform with hundreds of millions of devices online at the same time, we have to face the problem of 1 million connections per machine.

As a long-connection gateway, the main responsibility is to maintain the TCP connection with the device and forward data packets. For the long-connection gateway, we should make it as lightweight as possible, so we perform refactoring and optimization from top to bottom through the entire layer from architecture design, coding, operating system configuration, and hardware characteristics.
- Adjust the maximum number of file handles in the system and the maximum number of file handles in a single process;
- Adjust the system network card soft interrupt load balancing or enable network card multi-queue, RPS/RFS;
- Adjust TCP related parameters such as keepalive (need to be adjusted according to the session time of the host), close timewait recycles;
- Use AES-NI instructions on hardware to accelerate data encryption and decryption.
After our optimization, the online 8C32GB server can stably support 1.7 million long connections.

Another major difficulty lies in the connection keep-alive. An end-to-end TCP connection passes through layers of routers and gateways. The resources of each hardware are limited, and it is impossible to store all TCP connection states for a long time. Therefore, in order to prevent TCP resources from being recycled by intermediate routers and cause the connection to be disconnected, we need to send heartbeat requests regularly to keep the connection active.
How often should heartbeats be sent? Sending too fast will cause power consumption and traffic problems, and too slow will have no effect. Therefore, in order to reduce unnecessary heartbeats and improve connection stability, we use intelligent heartbeats to use different frequencies for different network environments.
330 million-level device load balancing
More than 100 million devices on our platform are online at the same time, and when each device is connected to the long-connection gateway, load balancing is performed through the traffic scheduling system. When the client requests to obtain an IP, the traffic scheduling system will issue multiple IPs of the nearest access gateway.

So how does the scheduling system ensure that the issued IP is available? You can simply think about it, and we use four strategies: nearest access, public network detection, machine load, and interface success rate. Which of these strategies are used? You can think about these two questions:
- The internal network is normal, can the public network be able to connect?
- Does it have to be available if there are few connections to the server?
The answer is no, because the persistent connection gateway and the traffic scheduling system are kept alive by heartbeat through the intranet, so the persistent connection gateway seen on the traffic scheduling system is normal, but it is very likely that the public network connection of the persistent connection gateway is For example, there is no permission to open the public network, so we need to combine various strategies to evaluate the availability of nodes, ensure the load balance of the system, and provide protection for the stability of the system.
3.4 How to meet high concurrency requirements
There is such a scenario: sending a piece of news to hundreds of millions of users at a push rate of one thousand per second, some users may not receive the news until a few days later, which greatly affects the user experience, so high concurrency The timeliness of the message is very important.

Judging from the push process shown in the figure, do you think that TiDB will become a performance bottleneck for push? In fact, no, at first glance, you may think that they are used as central storage, because we use distributed cache to cache the data stored in the central to each business node according to a certain strategy, make full use of server resources, and improve system performance and throughput. Our online distributed cache hit rate is 99.9%, and the central storage blocks most of the requests. Even if TiDB fails for a short time, the impact on us is relatively small.
3.5 How to ensure system stability
As a push platform, the traffic of our platform is mainly divided into external calls and internal calls between upstream and downstream. Their large fluctuations will affect the stability of the system, so we need to limit the current and control the speed to ensure the stable operation of the system.

3.5.1 Push gateway current limit
As a traffic portal, the stability of the push gateway is very important. To make the push gateway run stably, we must first solve the problem of traffic balance, that is, to avoid the problem of traffic skew. Because the flow is inclined, it is likely to cause an avalanche.
We use the polling mechanism to balance the load of traffic to avoid the problem of traffic skew. However, there is a prerequisite here, that is, the server configuration of all push gateway nodes must be consistent, otherwise it is very likely to cause an overload problem due to a lack of processing capacity. Secondly, we need to control the amount of concurrency flowing into our system to avoid traffic floods penetrating the push gateway and overloading the backend services. We use the token bucket algorithm to control the delivery speed of each push gateway, thereby protecting downstream nodes.
So what is the appropriate number of tokens to set? If the setting is too low, the resources of downstream nodes cannot be fully utilized; if the setting is too high, the downstream nodes may not be able to handle it. We can adopt the active + passive dynamic adjustment strategy:
1) When the traffic exceeds the processing capacity of the downstream cluster, notify the upstream to limit the speed;
2) When the call to the downstream interface times out, a certain percentage is reached to limit the current.

3.5.2 Internal speed limit of the system: label push and smooth delivery
Since the push gateway has already limited the current, why is the speed limited between the internal nodes? This is determined by the business characteristics of our platform. Our platform supports full and label push. We must avoid modules with better performance and exhaust downstream node resources. Our tag push module (providing full, tag push) is a high-performance service, in order to avoid its impact on the downstream. We implement the function of smooth push based on Redis and token bucket algorithm, and control the push speed of each label task to protect downstream nodes.

In addition, our platform supports applications to create multiple tag pushes, and their push speeds will be superimposed, so it is not enough to control the smooth push of a single tag task. It is necessary to limit the speed of the application granularity in the push delivery module to avoid the pressure on the business background caused by too fast push.
3.5.3 Internal speed limit of the system: speed-limited sending of messages

Therefore, in order to achieve application-level rate limiting, we use Redis to implement a distributed leaky bucket current limiting scheme. The specific scheme is shown in the figure above. Why do we use clientId (device unique identifier) instead of application ID for consistency hash? It is mainly for load balancing because clientId is compared to application ID. Since the implementation of this function, business parties no longer have to worry about pushing too fast, causing their own servers to be under great pressure.

So will the speed-limited message be dropped? Of course not. We will store these messages in the local cache and store them in Redis. The reason why we need to store them is to avoid subsequent storage hotspots.
3.5.4 Fusing downgrade
Pushing the platform, some emergencies and hot news will bring large burst traffic to the system. How should we deal with burst traffic?

As shown in the figure on the left, in the traditional architecture, in order to avoid the impact of sudden traffic on the system, a large number of machines are deployed redundantly, which is costly and wastes resources. In the face of burst traffic, the capacity cannot be expanded in time, which reduces the success rate of push. How do we do it? We adopt the solution of adding buffer channels, using message queues and containers, and this solution has little system changes. When there is no burst traffic, it is deployed with a smaller number of machines. When encountering burst traffic, we do not need manual intervention. It will automatically expand and shrink according to the system load.
3.6 Automated testing system based on Karate
In daily development, in order to quickly develop requirements, people often ignore the boundary test of the interface, which will cause great quality risks to online services. In addition, I don’t know if you have noticed that the different media used by different roles in the team to communicate, such as the use of word, excel, xmind, etc., will cause the communication information to be compromised to varying degrees. Therefore, in order to improve the above problems, we have developed an automated test platform to improve test efficiency and interface use case coverage. We use a unified language in the field to reduce the loss of communication information between different roles in the team. In addition, test cases can be managed in a unified and centralized manner to facilitate iterative maintenance.

3.7 Content Security
As a push platform, we need to ensure the security of content, and we provide the ability to audit content. We use automatic review as the main mechanism and manual review as the supplementary mechanism to improve review efficiency. At the same time, we conduct content audit based on the strategy based on impact and application classification to escort content security. It can be seen from the figure that the business request is forwarded to the content auditing system through the access gateway for content auditing of the first-layer local rules.

4. Future planning of the platform
So far, we have mainly introduced the architecture evolution of our push platform in the past few years and the practice of system stability, high performance, and security during the evolution process. Next, we will introduce our key work in the future.

In order to provide users with an easier-to-use, more stable and safer push platform, we will continue to invest in the following four aspects in the future:
- First, on the basis of single-module data consistency, realize the data consistency of the whole system;
- Second, although our platform currently has a certain capacity for disaster recovery and downgrade, it is not enough. We will continue to improve the fusing and downgrade capacity of each system;
- Third, we will continue to optimize the usability of the platform to provide users with more convenient platform services;
- Fourth, as a push platform, the ability to identify abnormal traffic is also more important. It can prevent abnormal traffic from affecting the stability of the system. Therefore, we will also build the ability to identify abnormal traffic in the future.
We also hope that as we continue to improve our platform capabilities, we can provide you with better services in the future.
Author: Li Qingxin, vivo Internet Server Team






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。