
1. What is an event-driven architecture
At present, with the rise of microservices, the development of containerization technology, and the popularization of cloud-native and serverless concepts, event-driven has once again attracted widespread attention in the industry.
The so-called event-driven architecture is the use of events to implement business logic across multiple services. Event-driven architecture is a software architecture and model for designing applications, which can minimize coupling and extend and adapt to different types of service components. In this architecture, when an important event occurs, such as updating business data, a service will publish events, and other services will subscribe to these events; when a service receives an event, it can execute its own business process and update business data. , while publishing a new event to trigger the next step.
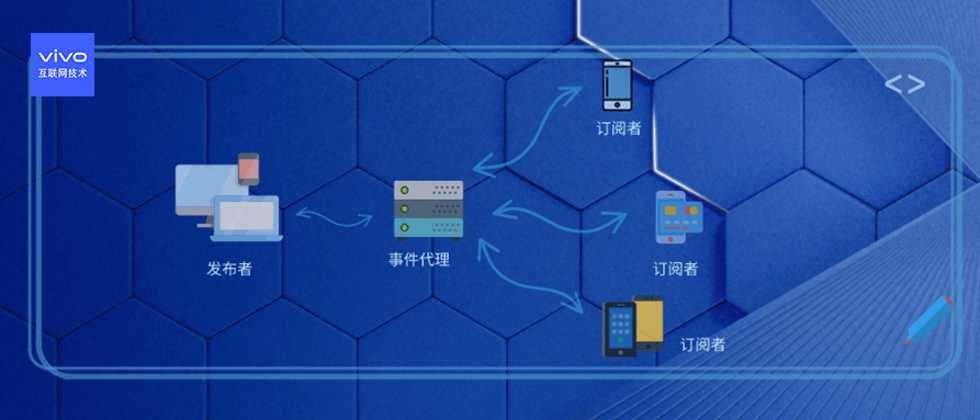
The publication and subscription of events need to rely on a reliable message broker. See below:

Of course, in fact, many software projects use message queues, but it needs to be clear that the use of message queues does not mean that your project must be an event-driven architecture. Many projects are only driven by technology. Only a small range of products have adopted some message queues. In such a large system, if your message queue is only used as a notification for sending emails, then the system naturally cannot use an event-driven architecture.
When adopting an event-driven architecture, we need to consider business modeling, event design, context boundaries, and more technical factors. How this system engineering should be implemented from start to finish requires thought and scrutiny. All in all, the design of an "event-driven architecture" is not an easy task. There is an example at the back of this article for reference.
Also, if you blindly use event-driven design architectures, you run the risk of breaking business logic that is conceptually highly coherent, but is tied together by decoupling mechanisms. In other words, it is to forcibly separate the code that originally needs to be organized together, and it is difficult to locate the processing flow, and there are also problems such as data consistency guarantee. In order to prevent our code from becoming a bunch of complex logic, we should use event-driven architecture in certain explicit scenarios. As a rule of thumb, there are three scenarios where event-driven development can be used:
- decoupling of components
- Execute asynchronous tasks
- Track state changes
2. When to use an event-driven architecture
2.1 Decoupling of components
When service (or component) A needs to execute the business logic in service B, instead of calling it directly, we can send an event to the event proxy (event dispatcher). Service B does this by listening to the dispatcher for a special event type and then executing it when such an event is received.
This means that both service A and service B depend on event brokers and events without concern for each other's implementation: that is, their decoupling is done. See below:

Based on this loose coupling, services can be implemented in different languages. Decoupled services can easily scale independently of each other on the network, modifying their systems by dynamically adding or removing event producers and consumers, without changing any logic in any service.
2.2 Execute asynchronous tasks
Sometimes we have a series of business logic that needs to be executed, but since they take a considerable amount of time to execute, we don't want to see users spend time waiting for these logic processing to complete. In this case, it's better to run them as asynchronous tasks and immediately return a message to the user notifying them to continue processing the operation later.
For example, the warehousing process such as checking of content fields can be processed by "synchronous" execution, but the execution of content understanding is processed by "asynchronous" tasks. In this case, all we have to do is fire an event, which will be added to the task queue until a service is able to fetch and execute the task. At this point, it doesn't matter whether the related business logic is in the same context, the business logic is executed anyway.
2.3 Tracking state changes
In the traditional data storage method, we store data through the entity model. When the data in these entity models changes, we simply update the row in the database to represent the new value. There is a problem here, that is, we cannot accurately store the change and modification time of data in business. However, in an event-driven architecture, the modified content can be stored in the event through event sourcing. "Event Sourcing" is discussed in detail below.
3. Why use an event-driven architecture
When people talk about event-driven architecture, say they happen to adopt event-driven architecture in a recent project, in fact, they may be talking about one or more of these four patterns:
- event notification
- event-carrying state transition
- Event Sourcing
- CQRS
Note: The concept comes from The many meanings of Event-Driven architecture shared by Martin Fowler at the 2017 GOTO Conference.
3.1 Event Notification
Suppose we now want to design a simple content platform with three parts:
- Content introduction system
- Author Microservice
- Concern Center
When a content creator uploads a video through the content import system, the following calling process will be triggered, as shown in the figure below:

- The content introduction system receives the video uploaded by the creator and executes the storage process;
- The content introduction system calls the API of the author's microservice, and increases the affiliation of "video-creator";
- The author service calls the API of the follower center to let the follower center send notifications of the author's video update to other users who follow the creator.
The above calling process inevitably creates the following dependencies:
- The content introduction system relies on the API of the author's microservice, although the content introduction system does not really care about the business of the author's microservice.
- The author microservice depends on the API of the attention center, although the author microservice does not care about the business and processing flow of the attention center.
There is a good chance that this dependency is not what we expected. The content introduction system is a relatively common business, and different types of content introduction systems are likely to have similar functions, such as field type checking, entering content libraries, and enabling high-sensitivity audits. Author service is a very professional system, for example, different sources and different types of content have different business logic for authors. It is not a good solution to make a general system depend on a professional system, no matter from the design point of view or the follow-up system maintenance point of view. The author microservice may be changed frequently according to business needs, but the content introduction system is relatively stable, and the above dependency makes it difficult for us to change the author microservice at will without adjusting the content introduction system.
From the architectural level, we hope to make the author's microservice depend on the content introduction system, and let a professional system depend on a stable and general system to increase the stability of the system. At this time, we can use "event notification". See below:

advantage
- Architecture is more robust. If the queued event can be executed in the source component, but in other components it cannot be executed due to a bug (due to enqueuing it to the queued tasks, they can be executed after the bug is fixed).
- Business processing reduces latency. This kind of work can be added to the event queue when the user does not need to wait for all the logic to be executed.
- It is easy to expand the system, allowing the R&D team of the component to develop independently, speeding up the project progress, reducing the difficulty of functions, reducing the occurrence of problems and being more organized.
- Encapsulate information in "events" for easy dissemination within the system.
Shortcomings
- Without fair use, our code may become "spaghetti" code.
- Data consistency issues. Because processes rely on eventual consistency, ACID transactions are generally not supported, so the handling of duplicate or out-of-order events complicates service code and makes it difficult to test and debug all cases.
The disadvantages and advantages of "event notification" correspond to each other. It is precisely because it provides a good decoupling capability that it is difficult for us to get a complete picture of the entire system and process by reading the code. Because the relationship between these logics is no longer the previous dependency. This will be a challenge.
3.2 Event-Bearing State Transition
When we use event notification, the event often does not contain all the information that the downstream system needs to process the event. For example, when the content is removed from the shelf, the content platform will generate a "content removal" event, but when the downstream system processes this event, it often needs to know what the last state of the content was, who triggered the removal, etc. information to complete subsequent processing. So inevitably, downstream systems often need to obtain these additional information through platform services when processing this event.
To solve this problem, we introduce a new pattern called "event-borne state transfer". Simply put, it is to let the consumer of the event keep a copy of the data of the upstream system that needs to be used in the business processing process. For example, let the downstream system keep a copy of the state before the content change that needs to be used when processing the content state change event, so as to avoid going back to the platform for query.
Advantage
- Architecture is more robust. Reduce the additional dependence of the event consumer on the producer (to obtain the data required for event processing);
- Business processing reduces latency. Increase the response speed of the event consumer system, because it is no longer necessary to call the platform API to obtain the data required for event processing;
- No need to worry about the load on the queried components (especially remote components).
Shortcomings
- Although data storage is no longer the source of the problem, multiple read-only copies of data are still saved, and consistency is further destroyed;
- To increase the complexity of data processing, even if the processing logic conforms to the specification, it requires additional business logic to process and maintain a local copy of the external data.
3.3 Event Sourcing
Sometimes we not only care about the current state of the system, we also care about how to get to this state, but the database simply holds the current state of the entity. Event sourcing can help us solve this problem.
Event source tracing is a special idea. It does not persist the entity object, but only records the initial state and each changed event, and restores the latest state of the entity object in memory according to the event. MySQL master-slave backup is used. The binary log of redis and the aof persistence mechanism of redis can be considered as the implementation of "event source tracing".
After the event source completes the database update, it converts the event sending operation into writing an event record to the database or log system. Other nodes obtain these events by querying the database or file system, and play back to ensure data integrity. eventual consistency.
Merit
- A complete history of changes can be presented;
- Provide more convenient debugging methods;
- Can go back to any historical state;
- It is convenient to modify the current event;
Shortcomings
- Implementing a reliable and high-performance event repository (saved event records) is not an easy task, and the application code needs to be rewritten according to the event repository's API.
3.4 CQRS
The full name of CQRS is Command Query Responsibility Segregation. To put it simply, for the read and write operations of the system, different data models, API interfaces, security mechanisms, etc. are used to achieve complete isolation of read and write operations to meet different business needs. See below:

According to the event collection stored in the event library, the state of each business entity can be calculated, and these states are stored in a database in the form of materialized views. When a new event occurs, the view is also automatically updated. In this way, the view query service can implement various query scenarios just like querying ordinary database data. The specific design can refer to the following figure:

Fourth, the practice of event-driven architecture in the content platform
In today's society, in the era of "runaway" content, content platform companies need to be extremely flexible and adaptable. Especially in a market like China where the content industry (such as video) is developing rapidly, companies require platforms to respond quickly to content business needs, otherwise they will lose their first-mover advantage. This is somewhat similar to the conditions of modern warfare. All countries require troops to have rapid response capabilities. This capability is mainly reflected in the platform's ability to quickly respond to business needs through rapid development or reuse/integration of existing resources.
As the content industry business becomes more and more complex, there are many storage types, processors, account systems, efficiency tools, data and settlement systems involved, which requires the platform to have strong integration capabilities and support for heterogeneous environments. adaptability.
Finally, due to the rapid development of the content industry, certain types of content businesses (such as small videos) will usher in a period of rapid expansion after their initial and mid-term development, and the business volume and business types will increase sharply, which also requires the platform to have a good Extensibility. The relevant platform architecture is shown in the following figure:

4.1 Create an event
An event is actually a concept in DDD (Domain Driven Design), which represents a valuable thing that occurs in a domain for the business. At the technical level, it is any change that affects the business process or state. Events have their own properties, such as when they happened, what happened, the relationship between events, status, and changes. Events can also generate new events, and new business events can be generated based on different events. When creating an event, you first need to record some general information about the event, such as the unique ID and creation time, etc. For this, create the event base class ContentEvent:
public abstract class AbstractContentEvent {
private String eventId;
private String publisher;
private String receiver;
private Long publishTime;
}public abstract class AbstractContentEvent { private String eventId; private String publisher; private String receiver; private Long publishTime; }In general scenarios, events are generally generated with the update of the state of the aggregation root (also a concept of DDD, here refers to the video id). In addition, on the consumer side of the event, sometimes we want to monitor events that occur under a certain aggregation root. For all events, it is recommended to create a corresponding event base class for each aggregate root object, which contains the aggregate root videoId. For example, for the video (Video) class, create a VideoEvent:
public class VideoEvent extends AbstractContentEvent {
private final String videoId;
}Then for the actual video event, it is inherited from VideoEvent, such as the VideoInputEvent event introduced by the video;
public class VideoInputEvent extends VideoEvent {
private Article article; // 视频基本信息
}The inheritance chain of video domain events is shown in the figure below;

There are two things to keep in mind when creating events:
- The event itself should be immutable;
- Events should carry contextual data information related to when the event occurred, but not state data for the entire aggregate root. For example, the basic information article of the video can be carried when the video is imported, and for the VideoStatusChangeEvent event of the video status update, it should also include the status status before and after the update:
public class VideoStatusChangeEvent extends VideoEvent {
private String preStatus; //更新前的状态
private String status; // 更新后的状态
}4.2 Publishing Events
There are various ways to publish events, such as in the application. The usual business processing process will update the database and then publish the event. A common scenario here is: it is necessary to ensure the atomicity between the database update and the event publishing, that is, either both succeed or both fail; of course, there are also no guarantees. Atomic scene. If atomicity needs to be guaranteed, take the business process of "content introduction" as an example, as shown in the following figure:

- receive content;
- write table of contents;
- Writes to the event table in the same local database transaction as the update to the content table;
- After the transaction is completed, trigger the sending of the event;
- read event table;
- send events to a message queue;
- After sending successfully, mark the record as "sent";
4.3 Consumption Events
When consuming events, in addition to completing the basic message processing logic, we need to focus on the following three points:
- The idempotency of the consumer;
- The consumer may further generate events;
- Consumer data consistency;
For "idempotency", the event sending mechanism guarantees "at least one delivery", which is guaranteed by message middleware, and needs to be paid attention to when selecting technology. In order to correctly handle duplicate messages, the consumer is required to be idempotent, that is, consuming an event multiple times has the same effect as consuming the event once. There are many ways to ensure "consumption idempotency", here is one. Create an event table on the consumer side to record the events that have been consumed. When processing an event, first check whether the event has been consumed, and if so, do not do any consumption processing.
For the second point, the "event table" method mentioned above is still used. In fact, whether it is processing service requests or serving as a message consumer, it is unaware of the aggregate root (videoId). Events are generated by the aggregate root and then persisted by the event library. These processes are related to specific business operations. The source doesn't matter.
For "data consistency", it is essentially derived from the second point. The event-driven architecture synchronizes the state between business objects through asynchronous messages. Some messages can also be published to multiple services at the same time. Synchronization" may cause additional messages and events to spread. Event-driven in the strict sense does not have synchronous calls. How to ensure consistency is more complicated than non-event-driven architectures. Usually, "cache aside" mode and "distributed lock" are used to ensure consistency.
To sum up, in the process of consuming events, the application needs to update the business table and event record table. At this time, the whole event publishing and consumption process is shown in the following figure;

V. Summary
In mainstream scenarios, traditional service-oriented (or data-driven) platforms have systemic deficiencies, and the following capabilities need to be enhanced:
- On the basis of traditional data integration, it is necessary to further improve business integration capabilities.
- There is a need to improve the business agility and responsiveness of the integration platform.
- It is necessary to further realize decoupling and high reliability between business systems.
- It is necessary to further improve the real-time response capability of the management and control platform.
An "event-driven architecture" naturally meets these capability requirements. The "innate" advantages of event-driven architecture, such as encapsulation, high cohesion, and low coupling, can also improve code maintainability, performance, and business growth requirements. Through the event sourcing model, it can also improve the reliability of system data.
However, event-driven also has drawbacks, because both conceptual and technical complexity increase, and when it is misused, it can lead to catastrophic consequences. Therefore, in terms of the selection of technology stacks, the following messages are given:
1) Don't "blindly follow new technologies" Technicians tend to follow whatever technology is popular. With the rapid development of technology now, various frameworks are constantly emerging at the front and back ends. We can't wait to use these frameworks in our own projects. We should proceed according to the actual situation, use it as needed, and reserve the space for technical pre-research appropriately.
2) Don't "stand in line with technology and push back with results" Many people regard means as ends and become believers of frameworks. With Java development, does your design have to be object-oriented? Is Spring boot a microservice? The technology must be combined with the actual scene, and the architect must also have an in-depth understanding of the technology, but it is more about understanding the advantages and disadvantages of the technology and the usage scenarios, rather than simply imitating them.
Author: vivo Internet Server Team - Gao Xiang





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。