
文章来源于沈辉
背景
喜马拉雅成立之初,各个业务管理各自的数据库、缓存,各个业务都要了解中间件的各种部署情况,导致业务间的合作,需要运维、开发等方面的人工介入,效率较低,扩展困难,安全风险也很高,资源利用率也不高。喜马拉雅在发展中,逐渐意识到需要在公司层面,提供统一的定制化的数据访问平台的重要性。为此,我们推出了自己的 PaaS 化平台,PaaS 化就是对资源的使用做了统一的入口,业务只需要申请一个资源 ID,就能使用数据库,达到对资源使用的全部系统化,其中对数据库的访问我们基于 Apache ShardingSphere 来实现,并基于 Apache ShardingSphere 强大功能做些优化和增强。
整体架构
我们 PaaS 平台建设中,负责和数据层通信的 dal 层中间件我们叫 Arena,其中对数据库的访问我们叫 Arena-Jdbc。
Arena-Jdbc 层的能力基本是基于 Apache ShardingSphere 的能力建设,我们只是基于喜马拉雅需要的特性做了增强和优化,整体架构如下:
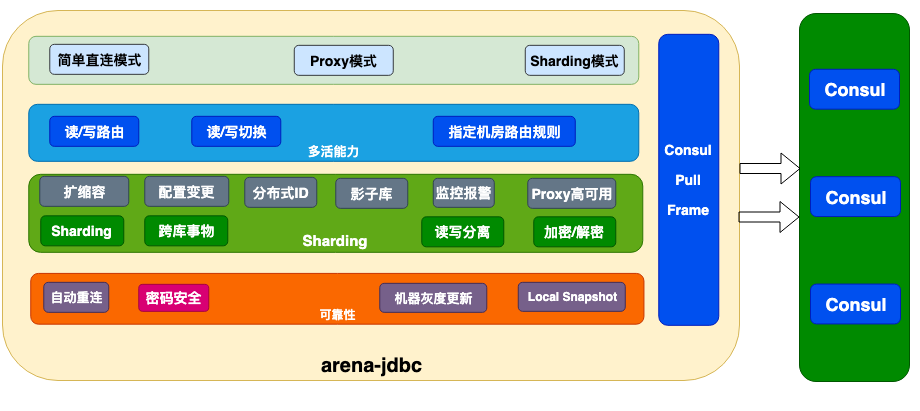
Pull Frame
Consul Pull Frame 是我们对 Consul 的配置自动拉起封装为统一的 Pull 框架,我们除了数据库,还有缓存,每种还有不同的使用方式,我们对不同的使用方式只需要实现对应的实现类和初始化,更新,切好这些接口就行,框架会统一把解析好的数据给到,具体一种场景不需要关心和 Consul 的交互,为后面的资源 PaaS 化提供了简单的接入能力。
故障容灾
· 自动重连
我们对故障容灾在设计时就考虑了平时通用的一些故障场景,比如数据库 server 挂了,我们做自动重链,不需要业务做重启操作。
· 本地快照
本地快照是为了防止 Consul 不可用时,业务不能启动,所以我们在拉到远程配置后,会本地存储一份,在拉配置时,如果远程失败,就用本地的配置,保证 Consul 挂了,不影响业务,每次拉到新的配置时,会更新本地的快照。
· 灰度更新
灰度更新是为了支持配置变更时找灰度的逻辑,对于数据库层面的变更,是非常危险的,如果一下就全量变更,有可能会触发线上事故,所以通过灰度变更的机制,业务可以先选择一个容器实例来变更,没有问题后,再全量变更,把风险降到最低。
· 密码安全
没有 PaaS 化之前,我们的数据库密码都是 DBA 统一管理的,但 PaaS 化后,访问数据库的密码就存在配置文件中,如果明文,就太不安全,所以我们对密码统一做了加密处理,在 Arena-Jdbc 层统一做解密,确保密码不会泄露出去。
统一数据源
为了让业务做最低成本的改造,Arena-Jdbc 需要提供一个统一的数据源,不论上层用什么框架,不影响业务只需要替换数据源接入即可,对于数据库连接池我们默认使用 HikariCP DataSource 也支持个性化的业务,业务可以通过配置指定连接池。
我们基于 Apache ShardingSphere 的连接池封装了一个我们自己的 DataSource,我们叫 ArenaDataSource,通过 ArenaDataSource 封装了各种不同场景聚合的使用一个 ArenaDataSource 支持三种使用方式:
- 支持原生直接连接
- 支持 Proxy 模式,也是 Apache ShardingSphere 的 Proxy
- 支持直接连接分库分表
业务只需要一个 DataSource,即支持分库分表,也支持简单的直接连接的模式,这样的好处是业务以后要分库分表,就不再需要升级中间件了,为了彻底解决业务升级的成本,我们做了配置自动升级,就是你之前是简单直接链接使用,为了 PaaS 化,后来业务发展了,需要分库分表了,以及从分库分表需要多活部署了,这些都不要再升级依赖了,只需要配置动即可。
资源动态变更
资源动态变更是 PaaS 平台基本的能力,接入 PaaS 后,业务修改数据库的任何属性,都不再需要业务方代码变更,重新发布。
Apache ShardingSphere 也支持数据库属性的动态变更,我们基于自己的内部系统的特征,实现了基于 Consul 的资源变更通知,我们的资源存在 Consul。
Arena-Jdbc 支持对使用的资源做无损的变更,Arena-Jdbc 收到资源变更时,会先对新下发的资源做预热处理,预热后,再切换使用的数据源,切换成功后,再销毁老的数据源,业务无感知。
如果新的资源预热失败,则不会做变更处理,保证下发的资源是可用的,规避错误下发的问题。
扩容和缩容也是同理,一期数据需要运维手动迁移,迁移好了后,直接在 PaaS 平台下发新的配置即可,二期支持自动迁移数据和配置变更结合。
同时支持 Proxy 的无损上下线机制,通过 PaaS 平台对 Proxy 的变更,把需要下线的 Proxy 节点去掉,通知 Arena-Jdbc,Arena-Jdbc 会把缩容的 Proxy 节点去掉,做到无损下线。
读写分离
读写分离我们完全基于 Apache ShardingSphere 的来实现,我们根据喜马拉雅业务的特性,对强制路由做了增强,不需要规则配置为 Hint 模式,只要线程上下文带有强制路由的标志,就可以路由到指定的库和表,不受分表规则的影响,我们重写了 ShardingStandardRoutingEngine 的 Sharding 时路由库和表的逻辑:
private Collection<String> routeDataSources(final TableRule tableRule, final ShardingStrategy databaseShardingStrategy, final List<ShardingConditionValue> databaseShardingValues) {
//先判断是否存在Hint上下文路由标,如果有,则优先根据用户指定的规则路由库
Collection<Comparable<?>> databaseShardings = HintManager.getDatabaseShardingValues(tableRule.getLogicTable());
if (databaseShardings != null && databaseShardings.size() > 0) {
List<String> list = new ArrayList<>(4);
for (Comparable<?> databaseSharding : databaseShardings) {
list.add((String) databaseSharding);
}
if (log.isDebugEnabled()) {
log.debug("route dataSources, find HintManager, so hint to: {}", list);
}
return list;
}
//没有Hint路由规则,则按Sharding 规则路由
if (databaseShardingValues.isEmpty()) {
return tableRule.getActualDatasourceNames();
}
Collection<String> result = new LinkedHashSet<>(databaseShardingStrategy.doSharding(tableRule.getActualDatasourceNames(), databaseShardingValues, properties));
Preconditions.checkState(!result.isEmpty(), "no database route info");
Preconditions.checkState(tableRule.getActualDatasourceNames().containsAll(result),
"Some routed data sources do not belong to configured data sources. routed data sources: `%s`, configured data sources: `%s`", result, tableRule.getActualDatasourceNames());
return result;
}路由表也是同样的逻辑,我们重写了 ShardingStandardRoutingEngine 的 routeTables 方法,和上面一样,先从 Hint 的上下文获取。这样通过上下文的方式能很好地满足业务个性化的路由规则,能和 Sharding 规则共存。
Database Plus
Apache ShardingSphere 除了提供基本的分库分表,读写分离的能力外,在上层还提供了很多的插件和扩展的机制,这让我们在基于数据库提供更偏向业务的能力非常容易,成本非常低,这叫 Database Plus。
Database Plus 简单的说就是用 Apache ShardingSphere 的数据库中间件,不仅仅是提供了分库分表这一基本能力,通过对底层数据的封装为统一的交互标准插件模式,可以在上面实现很多业务的通用的场景的需求,比如喜马拉雅除了用到 Apache ShardingSphere 基础的能力外,我们也享受了 Database Plus 的威力,我们在它的基础上轻松实现了支持压测的影子库和影子表,数据加解密,机房级别容灾的同城双读,分布式唯一 ID。
影子库和影子表
影子库影子表我们对 Apache ShardingSphere 做了改动,Apache ShardingSphere 需要修改 SQL,我们认为对业务有改造成本,同时结合我们自己的压测平台,我们和业界一样,我们也实现了影子标记,通过全链路压测标的传递来判断是否路由到影子库/影子表,业务无需任何改造,即可使用影子库影子表来做压测,同时不需要在运行时对 SQL 改写,提升了性能,我们重写了 ShadowSQLRouter。
public class ArenaShadowSQLRouter extends ShadowSQLRouter {
@Override
public boolean isShadow(final SQLStatementContext<?> sqlStatementContext, final List<Object> parameters, final ShadowRule rule) {
if (sqlStatementContext instanceof InsertStatementContext || sqlStatementContext instanceof WhereAvailable
|| sqlStatementContext instanceof UpdateStatementContext) {
//这里就是判断是否有压测标,如果有,ShardingSphere则会找影子的逻辑。
return ArenaUtilities.checkPeakRequest();
}
return false;
}
}通过 spi 的方式把我们自定义的 ArenaShadowSQLRouter 给 Apache ShardingSphere 加载使用,不得不说 Apache ShardingSphere 的插件设计很赞,很方便自定义和扩展。
配置还是和 Apache ShardingSphere 的一样:
配置影子库规则
- !SHADOW
# true-影子表,false-影子库(默认)
enableShadowTable: true
# 源库名称(对应DataSources数据源配置中的名称),影子库才需要配,影子表不需要配置
sourceDataSourceNames:
- ds0 # 源库,与影子库shadow_ds0对应
- ds1 # 源库,与影子库shadow_ds1对应
# 影子库名称(对应dataSources数据源配置中的名称),影子库才需要配,影子表不需要配置
shadowDataSourceNames:
- shadow_ds0 # 影子库,与源库ds0对应
- shadow_ds1 # 影子库,与源库ds1对应enableShadowTable 我们新增了该属性,来确定是使用影子库还是影子表。
影子库
影子库,一定要填 sourceDataSourceNames 和 shadowDataSourceNames,enableShadowTable 不用设置,或者设置为 false。
sourceDataSourceNames
按顺序映射,一一对应:
ds --> shadow_ds
ds1--> shadow_ds1
影子库/影子表是最后一个路由规则,如果发现有影子库/影子表,则根据实际的库找到对应的影子库/影子表,执行 SQL。
同城多活
基于喜马拉雅的业务特性,读多写少,我们只实现了对读业务的双机房部署,写业务还是路由到主机房。
为了增强容灾能力,喜马拉雅搭建了双机房,同时承载业务流量,当一个机房故障时,可以把流量快速切换到另一个机房,我们在 dal 层设计上支持双写,这里充分利用了 Apache ShardingSphere 的读写分离功能,读和写可以配置独立的数据源,我们只需要在上面做了一层封装,在切换时候动态变更对应的数据源即可,为了切换时不影响业务的流量,我们是先预热新的数据源,再销毁老的数据源。
架构图如下:
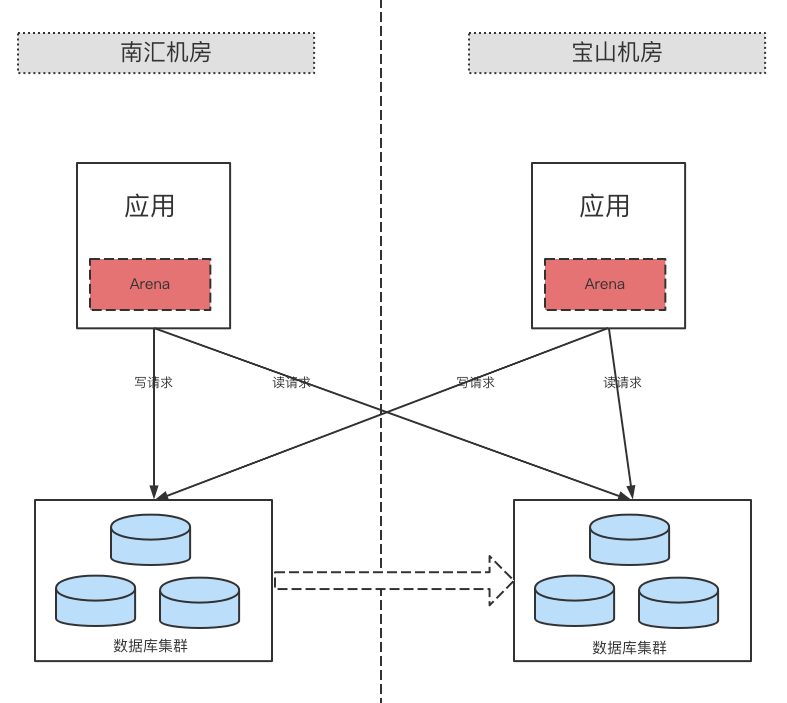
另外我们也对双写做了研究和探索,关键在于数据库的双向同步,基于阿里开源的 otter 做了改造,支持基于 gtid 模式同步,不依赖打标,打标会有性能开销,在一些业务做了试用。
分布式唯一 ID
分库分表后,唯一 id 是必须要满足的需求,Apache ShardingSphere 默认提供了 snowfake 和 uuid 算法,但不是很 db 时候的场景,db 需要保证顺序和格式,所以我们基于 Apache ShardingSphere 提供的接口,也实现自己的唯一 id 生成策略:数据分片后,不同 MySQL 实例生成全局唯一主键是非常棘手的问题。Arena-Jdbc 实现了 Apache ShardingSphere 的分布式主键生成器接口,通过集成喜马拉雅内部的全局唯一 id 生成服务,提供了适用于喜马拉雅内部的自增主键生成算法- BoushId 主键生成策略。
监控和报警
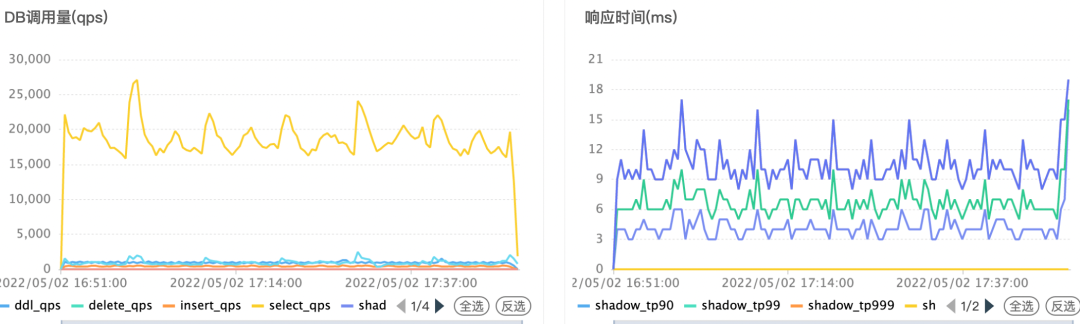
做一个数据库中间件,监控是必不可少的部分,就像我们的眼睛,没有监控就是瞎抓,以及对异常情况的报警也是非常重要的部分,只有完善的监控和报警才能算是一个完整的产品,得益于 Apache ShardingSphere 在设计时就提供了钩子,我们能非常小的成本就能实现对 SQL 层面的监控和报警。
Arena-Jdbc 客户端通过钩子回调,从多维度数据来分析使用数据库的运行情况,以 30s 为一次统计周期,每个周期统计的数据包括:MySQL 总请求量,新增、删除、修改和查询的请求量,失败的请求量和慢请求量,影子库的流量,以及统计响应时间的 TP 百分比,还有连接池的等待时间、建连时间、连接数等信息。这些指标会发送给专门的收集指标服务,并持久化到时序数据库,PaaS 平台可以从时序数据库中查询数据,展示给各个业务,对于异常 SQL 和慢 SQL,做报警等后续处理。
其他
我们除了基于 Apache ShardingSphere 实现上述关键特性外,我们还对 Apache ShardingSphere 做了一些优化和改进,以更适合喜马拉雅的业务。
· 优化分片规则,启动时,如果分片的真实表不存在的情况则报错,将配置错误前置;
· 有的业务方有几百,甚至几千的分表,这种情况下,由于 Apache ShardingSphere 中的联邦查询需要依次扫表,启动速度很慢,达到了分钟级别。针对这种情况,我们新增了 props 配置项,不再初始化联邦查询,大大加快了启动速度,并且在使用中,也没有用联邦查询;
· 优化了 Apache ShardingSphere,执行 SQL 异常不报错误的情况;
· 由于有的业务方,对重要的表采用了大写的表名和列名,我们去掉 Apache ShardingSphere 中,对配置中的大写的表名列名强制小写的情况,允许大写的表名和列名;
· 新增了 props 配置项,可以调节 Apache ShardingSphere 的编译缓存的大小;
· 优化 Apache ShardingSphere 复合分片算法,精确匹配分片字段;
· 在 ComplexShardingStrategyConfiguration 中,添加 shardingColumnList 字段,修复 Apache ShardingSphere 批量 insert 不返回主键的问题,这个问题在 mybatis-plus 中比较常见;
· 不分片的表,支持使用默认的主键 id 生成策略。
总结
基于 Apache ShardingSphere 实现的数据库中间件 Arena-Jdbc,经过半年的时间,已经覆盖了喜马拉雅的 70% 的核心业务,目前没有发现任何问题,表现的非常稳定,通过和我们的 PaaS 平台结合,业务也非常愿意接入,另外我们使用 Apache ShardingSphere 时,社区还没有发布 stable 的版本,所以我们在使用过程中也遇到了些问题,基本上我们都解决了,有的社区也有对应的解决方案,得益于社区非常活跃,我们以后也希望把我们做的一些 feature 能回馈到社区,为 Apache ShardingSphere 的发展做出一点点小贡献。
非常感谢基础架构团队胡建华、彭荣新提出的宝贵意见和建议,感谢喜马拉雅基础小伙伴们在项目推广过程中的大力支持,让 Apache ShardingSphere 在喜马拉雅生根发芽。
非常感谢亮哥亲自来喜马拉雅对 Apache ShardingSphere 的技术内幕和规则做了一次全面的分享,非常关心我们在使用 Apache ShardingSphere 过程中遇到的问题,在现场对小伙伴提的问题都一一作了深入的解答,非常感谢亮哥,祝 Apache ShardingSphere 越来越好。
如果大家对 Apache ShardingSphere 有任何疑问或建议,欢迎在 GitHub issue 列表提出,或可前往中文社区交流讨论。
GitHub issue:https://github.com/apache/sha...
贡献指南:https://shardingsphere.apache...
中文社区:https://community.sphere-ex.com/
欢迎点击链接,了解更多内容:
Apache ShardingSphere 官网:https://shardingsphere.apache...
Apache ShardingSphere GitHub 地址:https://github.com/apache/sha...
SphereEx 官网:https://www.sphere-ex.com





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。