
2018 年 3 月,一篇《Service Mesh 是大方向,那 Database Mesh 呢?》迅速火爆技术圈。在这篇文章中,Apache ShardingSphere 创始人张亮沿着 Service Mesh 的思路,对 Database Mesh 进行了畅想。四年过去了,当年的 Database Mesh 理念已经在一些公司开花结果,配合各自的工具和生态进行了实践。今天再看,除了 Service Mesh 以外,“X Mesh” 的理念已经深入人心,ChaosMesh、EventMesh、IOMesh 等各种类型的 Mesh 如雨后春笋般涌出,而 Database Mesh 经过四年的沉淀也迎来了属于它的新一页:Database Mesh 2.0。
本文将带领各位读者回顾 Database Mesh 诞生的背景,重新审视 Database Mesh 1.0 的价值,并为大家介绍 Database Mesh 2.0 的新概念、新思路和新特性,共同探讨 Database Mesh 的未来之路。
01 Database Mesh 1.0 回顾
2016 年,第一代 Service Mesh 由 Linkerd 带入大众视野,紧接着 2017 年就诞生了以 Istio 为代表的第二代 Service Mesh,采用了控制面和数据面分离的设计模式,将服务治理中如流量治理、访问控制、可观测性等关键行为要素进行了抽象和标准化,然后借助 Kubernetes 的 Sidecar 模式解耦了应用容器和治理容器。至此,Service Mesh 的形态已经基本确定。
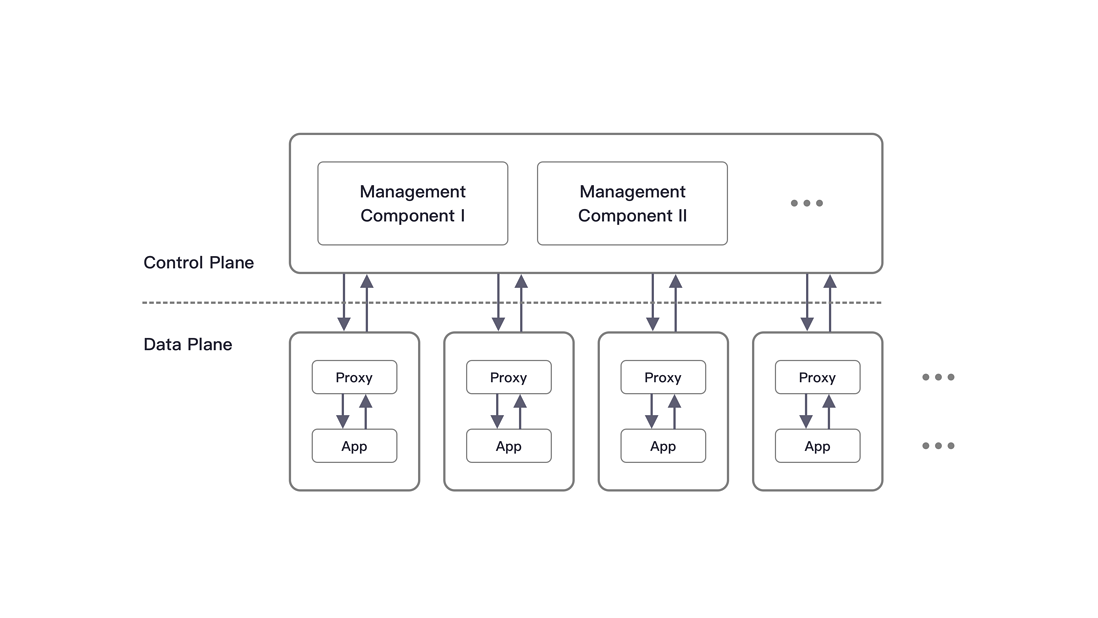
几乎是同样的时间点,由张亮主导的 ShardingSphere 从原来的 ShardingSphere-JDBC 演化出可以独立部署的 ShardingSphere-Proxy。它们都采用 Java 构建实现,分别代表了 SDK 模式和 Proxy 模式,提供了相同的标准化数据分片、分布式事务等功能。但无论使用哪种方式,都有其各自的优缺点。在 2018 年的这篇《Service Mesh 是大方向,那 Database Mesh 呢?》(https://www.infoq.cn/article/...)是这么描绘 Database Mesh 的:

如此一来 Service Mesh 在 Kubernetes 上的 Sidecar 模型实现就变得非常有启发性:如果设计一种 ShardingSphere-Sidecar 模式,将 ShardingSphere 的核心分片能力等迁移到其中,就可以有效的结合 JDBC 代理端与 Proxy 客户端的优点并屏蔽其缺点,达成“弹性伸缩 + 零侵入 + 去中心,实现了一个真正的云上基础设施”。这个阶段的 Database Mesh 为 1.0 阶段。
任何一个新技术概念在它落地的时候,都会因为不同的业务场景和模式、不同的架构设计模式、不同的基础设施成熟度、乃至差异的工程师文化而打上自己独特的烙印。这一点在 Kubernetes 落地历程中已经得到了充分验证,而 Service Mesh 落地又再次加深了这个观点。那么对于 Database Mesh 呢?
ShardingSphere-Sidecar 试图将 ShardingSphere 的核心分片能力等迁移到其中,而一些公司在 Database Mesh 基础上丰富了更多观点,比如在 Service Mesh 的框架中,通过二次开发的方式增加了对 SQL 协议的解析和支持,增强了数据库流量治理能力,兼容了统一的服务治理配置;比如将 Database Mesh 的理念集成到一套完整的中间件服务框架中,以 SDK 或者 Sidecar 的方式给业务应用暴露统一的访问方式,简化开发者的使用;还比如将分布式事务能力集成到 Database Mesh Sidecar 中的项目,以云原生分布式数据库的方式为业务应用进行呈现。不管是哪种方式,都可以看出来 Database Mesh 理念正在不断深入人心,逐步成长为一个繁荣的生态。
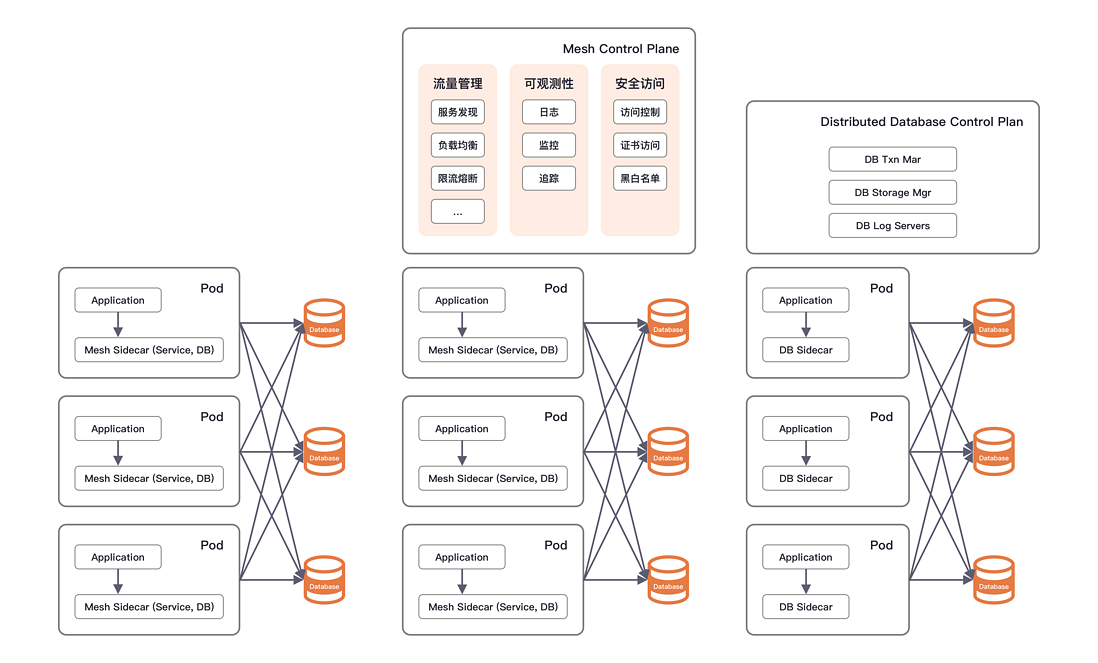
注:从左往右分别为“ShardingSphere-Sidecar、统一 Mesh 管控、分布式数据库”三种 Database Mesh 1.0 的实现。
这个阶段的 Database Mesh 为 1.0 阶段。
02 Database Mesh 2.0 介绍
在计算机科学的世界里,操作系统和数据库可谓是两大最重要的基础软件。就拿 SQL 这门语言来说,它的半衰期之长令人记忆深刻。SQL 不仅在早期的 DBMS 系统中扮演了相当重要的角色,近些年在数据科学领域和 Python 一同成为从业人员的必备技能。SQL 的生命力真可谓是“历久弥新”,以至于有论文直言希望“One SQL to rule all”。这也从侧面反映了数据库领域历史之久,地位之重,具备浓重的领域特色。
如果将数据库视为调用链上一个服务节点,那么同样可以采用 Service Mesh 的框架进行治理。而如果将数据库视作一个有状态的业务应用,它独特的领域性带来了治理的特殊性:比如,数据库请求无法像服务一样可以被随意路由到任何对等节点。而对数据库协议的感知和理解、数据分片和路由、数据库部署的多副本、读写分离、主库多写等模式,也带来了更多的挑战。
更近一步地,当业务应用开始以容器的方式进行打包交付、利用 CI/CD 流水线每天发布成百上千次到各个数据中心的 Kubernetes 基础设施的时候,必然会引发对应用上层服务治理和对数据库治理的思考,Database Mesh 就是这种思考之下的产物。如果没有 Database Mesh,不管是 SDK 还是 Proxy,同样可以支持对数据库的访问治理,Sidecar 本身并非 Database Mesh 的内核,实际上是基础架构全面云原生化的浪潮,在不断推着 Database Mesh 前进。
Database Mesh 不是静态的定义,而是一个在不断进化的动态概念。
Database Mesh 从 1.0 开始,始终关注对数据库流量的治理,基于数据库协议感知能力,提供数据分片、负载均衡、可观测性、审计等能力。这些能力已经解决了数据库治理中属于流量治理的部分问题。但对运维人员和数据库管理人员来说,还有很多可以持续建设的方面。比如是否可以通过统一的配置声明数据库接入?是否可以通过可编程的方式,实现对数据库访问的资源限制?是否可以通过标准的界面自动化数据库维护体验?
在不同的用户视角里,开发人员更关注运行效率、成本开销,以及数据库协议类型和访问信息,不关心数据存储的位置。运维和 DBA 更关注数据库服务的自动化、稳定性、安全性、监控报警等,此外 DBA 还会关心数据的变更、容量、安全访问、备份、迁移等等。这些问题都属于数据库可靠性工程的范畴。
正是随着对数据库治理场景的深入理解和对用户体验的极致追求,共同催生了 Database Mesh 2.0:通过可编程实现高性能扩展,应对云上数据库治理挑战。
Database Mesh 2.0 的目标
Database Mesh 2.0 关注在云原生环境下,如何实现以下几个目标:
- 进一步减轻开发人员的心智负担,提高开发效率,提供透明和无感的数据库基础设施使用体验;
- 以可配置、可插拔、可编程的方式,实现一个覆盖数据库流量、运行时资源和稳定性保障等方面的治理框架;
- 为异构数据源、云原生数据库、分布式数据库等多个数据库领域的典型场景提供标准的使用界面。
开发者体验
如前所述,业务开发人员主要关注业务逻辑和实现,无需关心基础设施和其运维特征,而开发的体验会逐步向 Serverless 的方向前进,对数据库的访问也就必然会变得越来越透明和无感。开发人员只需要了解自己业务所需要的数据存储类型,然后使用预置的或者动态的身份机密信息,即可访问相应的数据库服务。
可编程
对于数据库流量来说,不同的场景会有不同的负载均衡策略和防火墙规则,这些都可以以配置的形式提供给用户。更进一步地,对于流量带宽等运行时资源,可以通过加载可编程插件的方式对其进行限制。无论是配置还是插件,都希望给用户提供框架之内最大的灵活度,践行 Unix “机制和策略分离”的设计哲学。
标准界面
在数据库上云的过程中,因为部署模式、数据迁移、数据容量等诸多问题,增加了上云的复杂度。而标准化的操作可以极大地帮助上云过程。如果可以有一套完整的操作界面,就可以在不同的数据库环境里实现统一的治理行为,从而让未来上云的过程变得更加顺滑。
Database Mesh 2.0 治理框架
为实现上面的三个目标,Database Mesh 2.0 提供了一种以数据库为中心的治理框架:
- 数据库是一等公民:一切抽象都围绕数据库治理行为进行,比如访问控制、流量治理、可观测性等;
- 面向工程师体验:对于开发人员,通过便捷易用的数据库声明和定义,即可继续进行开发,无需关心数据库的位置;对于运维和 DBA,提供多种数据库治理行为抽象,实现自动化的数据库可靠性工程;
- 云原生:以开放的生态和实现机制适配不同的云环境,面向云原生构建和实现,而无需担心厂商锁定。
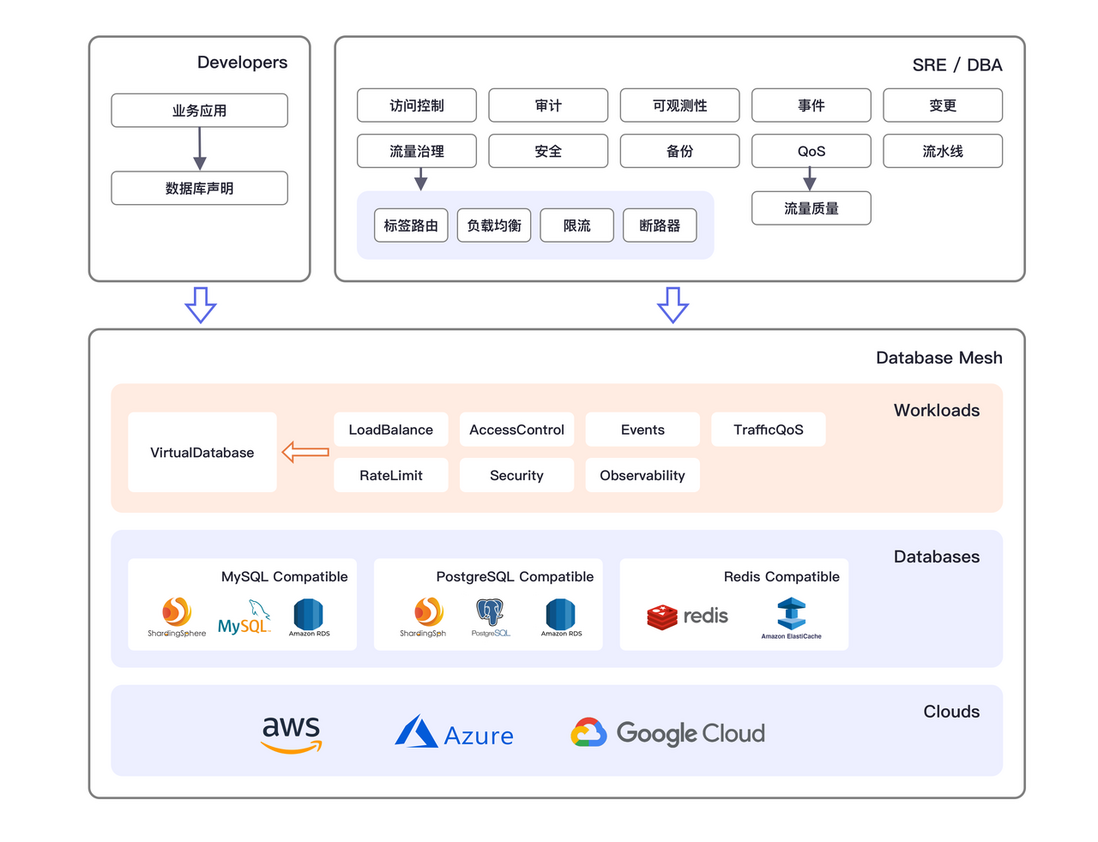
这套治理框架依赖于如下工作负载:
- 虚拟数据库:开发人员视角里一个可以被访问的数据库端点
- 流量策略:对数据库访问流量的治理策略,如分库分表、负载均衡、限流、断路
- 访问控制:根据指定规则提供细粒度的访问控制,如表级别
- 安全声明:数据安全性声明,如数据加密等
- 审计申请:记录应用对数据库的操作行为,如接入风控系统
- 可观测性:数据库的访问流量、运行状态、性能指标等可观测性的配置
- 事件总线:接受数据变更的事件总线
- QoS 声明:提高数据库整体 SLO 指标而设定的资源 QoS 指标
- 备份计划:按计划任务的方式执行数据库备份
- Schema 流水线:以代码方式管理数据库 schema 变更,提高数据库 DDL 和 DML 变更的成功率
基于这样的设计,可以让开发更集中更高效,让云计算更亲和。换句话说,Database Mesh 正在向着扩展性、易用性和标准化的方向大踏步地前进。
这个阶段的 Database Mesh 为 2.0 阶段。
03 Database Mesh 社区
目前 Database Mesh 官网已上线,相应的规范定义也开源在(https://github.com/database-mesh/database-mesh)仓库里。社区每两周都会进行线上讨论,信息如下:

欢迎各位读者加入官方社区进行讨论,Database Mesh 社区欢迎来自不同背景的爱好者们一起建设生态。
此外,Database Mesh 发起人张亮所在 SphereEx 公司将于下月推出面向数据库网格的开源解决方案 Pisanix,欢迎各位关注!
作者介绍
苗立尧,SphereEx 云研发负责人,开源布道师,专注于 SaaS 和 Database Mesh。2015 年起开始接触 Kubernetes,是国内最早一批云原生实践者,2016 年创办“容器时代”公众号,原创和翻译引进 600 余篇技术文章。曾在株式会社ネットスターズ、北京穿杨科技、蚂蚁金服、易宝支付等担任基础设施架构师、云产品负责人、云原生研发工程师等相关职位。
GitHub:https://github.com/mlycore
张亮,SphereEx 创始人 & CEO,Apache Member,Apache ShardingSphere、ElasticJob PMC Chair,微软 MVP 、腾讯云 TVP。
GitHub:https://github.com/terrymanu
欢迎点击链接,了解更多内容:
Apache ShardingSphere 官网:https://shardingsphere.apache.org/
Apache ShardingSphere GitHub 地址:https://github.com/apache/shardingsphere
SphereEx 官网:https://www.sphere-ex.com
欢迎添加社区经理微信(ss_assistant_1)加入交流群,与众多 ShardingSphere 爱好者一同交流。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。