
Redis has high-performance data reading and writing functions, and is widely used in caching scenarios. One is to improve the performance of business systems, and the other is to resist high concurrent traffic requests for the database. Click me -> decrypt the secret of why Redis is so fast .
Using Redis as a cache component needs to prevent some of the following problems, otherwise it may cause production accidents.
- What should I do if the Redis cache is full?
- How to solve cache penetration, cache breakdown, and cache avalanche?
- Will Redis data be deleted immediately when it expires?
- Redis suddenly slows down, how to do performance troubleshooting and solve it?
- How to deal with the data consistency problem between Redis and MySQL?
Today, "Code Brother" will explore the working mechanism of the cache and the cache coherence solution with you in depth.
Before this article officially begins, I think we need to reach a consensus on the following two points:
- The cache must have an expiration time;
- It is enough to ensure the final consistency between the database and the cache, and there is no need to pursue strong consistency.
The directory is as follows:
[toc]
1. What is database and cache coherency
Data consistency refers to:
- There is data in the cache, the cached data value = the value in the database;
- The data is not in the cache, the value in the database = the latest value.
The pushback cache is inconsistent with the database:
- The cached data value ≠ the value in the database;
- There is old data in the cache or database, causing the thread to read the old data.
Why do data consistency problems occur?
When using Redis as a cache, we need to double-write when the data changes to ensure that the cache is consistent with the data in the database.
Database and cache, after all, are two systems. If you want to ensure strong consistency, it is necessary to introduce distributed consistency protocols such as 2PC or Paxos , or distributed locks, etc. It is difficult to implement and will definitely have an impact on performance.
If the consistency requirements for data are so high, is it really necessary to introduce a cache?
2. Cache usage policy
When using cache, there are usually the following cache usage strategies to improve system performance:
-
Cache-Aside Pattern(cache bypass, commonly used in business systems) -
Read-Through Pattern -
Write-Through Pattern -
Write-Behind Pattern
2.1 Cache-Aside (bypass cache)
The so-called "cache bypass" means that the operations of reading the cache, reading the database and updating the cache are all performed by the application system , and the most commonly used caching strategy for business systems .
2.1.1 Read data

The logic for reading data is as follows:
- When an application needs to read data from the database, it first checks whether the cached data is hit.
- If the cache misses, query the database to get the data, and write the data to the cache at the same time, so that subsequent reads of the same data will hit the cache, and finally return the data to the caller.
- If the cache hits, return directly.
The timing diagram is as follows:

advantage
- Only the data actually requested by the application is included in the cache, helping to keep the cache size cost-effective.
- It is simple to implement and can get performance improvement.
The pseudocode of the implementation is as follows:
String cacheKey = "公众号:码哥字节";
String cacheValue = redisCache.get(cacheKey);
//缓存命中
if (cacheValue != null) {
return cacheValue;
} else {
//缓存缺失, 从数据库获取数据
cacheValue = getDataFromDB();
// 将数据写到缓存中
redisCache.put(cacheValue)
}shortcoming
Since data is only loaded into the cache after a cache miss, the response time of the data request for the first call adds some overhead due to the additional cache fill and database query time required.
2.1.2 Update data
When using the cache-aside mode to write data, the process is as follows.

- write data to the database;
- Invalidate the data in the cache or update the cached data;
When using cache-aside , the most common write strategy is to write the data directly to the database, but the cache may be inconsistent with the database.
We should set an expiration time for the cache, this is the solution to ensure eventual consistency.
If the expiration time is too short, the application will continuously query data from the database. Likewise, if the expiration time is too long, and the update does not invalidate the cache, the cached data is likely to be dirty.
The most common way is to delete the cache to invalidate the cached data .
Why not update the cache?
performance issues
When the update cost of the cache is high and multiple tables need to be accessed for joint calculation, it is recommended to delete the cache directly instead of updating the cache data to ensure consistency.
safe question
In high concurrency scenarios, the data found in the query may be old values. The code will analyze the details later, so don't worry.
2.2 Read-Through (direct reading)
When the cache misses, the data is also loaded from the database, written to the cache and returned to the application system at the same time.
Although read-through and cache-aside are very similar, in cache-aside the application is responsible for fetching data from the database and populating the cache.
Read-Through, on the other hand, shifts the responsibility for fetching the value from the data store to the cache provider.

Read-Through implements the principle of separation of concerns. The code only interacts with the cache, and the cache component manages the data synchronization between itself and the database.
2.3 Write-Through synchronous write-through
Similar to Read-Through, when a write request occurs, Write-Through transfers the write responsibility to the cache system, and the cache abstraction layer completes the update of cache data and database data . The sequence flow chart is as follows:

The main advantage of Write-Through is that the application system does not need to consider fault handling and retry logic, and is handed over to the cache abstraction layer to manage the implementation.
Advantages and disadvantages
It is meaningless to use this strategy directly, because this strategy needs to write to the cache first, and then write to the database, which brings extra delay to the write operation.
When Write-Through is used in conjunction with Read-Through Read-Through can be fully utilized, and data consistency can be ensured, so there is no need to consider how to invalidate the cache settings.

This strategy reverses the order in which the cache is filled Cache-Aside instead of delaying loading into the cache after a cache miss, the data is written to the cache first, and then the cache component writes the data to the database .
advantage
- Cache and database data are always up to date;
- Query performance is best because the data to be queried may have already been written to the cache.
shortcoming
Infrequently requested data is also written to the cache, resulting in a larger and more expensive cache.
2.4 Write-Behind
At first glance this graph looks the same as Write-Through , but it is not, the difference is the arrow of the last arrow: it changes from a solid to a line.
This means that the cache system will update the database data asynchronously, and the application system only interacts with the cache system .
The application does not have to wait for database updates to complete, improving application performance because updates to the database are the slowest operation.

Under this strategy, the consistency between the cache and the database is not strong, and it is not recommended for systems with high consistency.
3. Analysis of Coherence Problems under Side Cache
The most commonly used in business scenarios is the Cache-Aside (cache bypass) strategy. Under this strategy, the client reads data from the cache first, and returns if it hits; The database reads and writes data to the cache, so the read operation does not cause inconsistencies between the cache and the database.
The focus is on write operations. Both the database and the cache need to be modified, and there will be a sequence between the two, which may cause the data to no longer be consistent . For writing, we need to consider two issues:
- Update the cache first or update the database?
- When the data changes, choose to modify the cache (update), or delete the cache (delete)?
Combining these two problems, four scenarios emerge:
- Update the cache first, then update the database;
- Update the database first, then update the cache;
- Delete the cache first, then update the database;
- Update the database first, then delete the cache.
You don't need to memorize the following analysis by rote. The key is that you only need to consider whether the following two scenarios will cause serious problems during the deduction process:
- Where the first operation succeeds and the second fails, what could cause the problem?
- Will the read data be inconsistent in the case of high concurrency?
Why not consider the first failure and the second success?
you guess?
Since the first one fails, the second one does not need to be executed, and the exception information such as 50x can be returned directly in the first step, and there will be no inconsistency problem.
Only the first one succeeds and the second one fails, which is a headache. If you want to ensure their atomicity, it involves the category of distributed transactions.
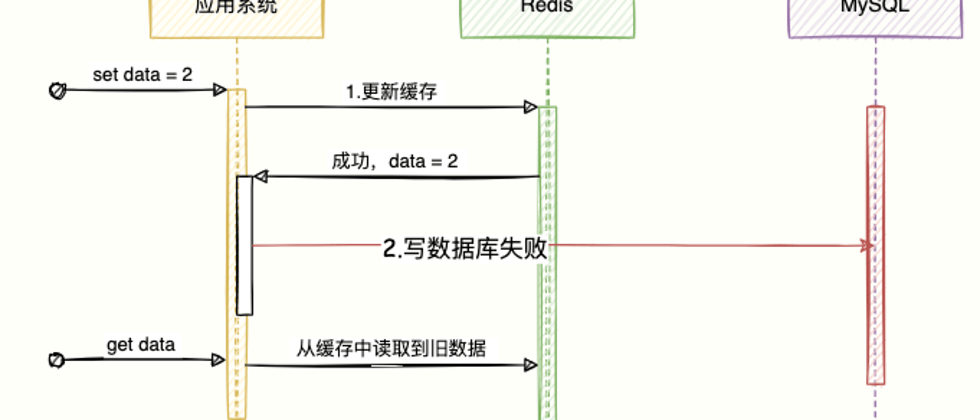
3.1 Update the cache first, then update the database

If the cache is updated first, but the database fails to be written, the cache is the latest data and the database is the old data, so the cache is dirty data.
After that, other queries will get this data when they come in immediately, but this data does not exist in the database.
Data that doesn't exist in the database is meaningless to cache and return to the client.
The program directly Pass .
3.2 Update the database first, then update the cache
Everything works fine as follows:
- Write the database first, success;
- Then update the cache, success.
Update cache failed
At this time, let's infer that if the atomicity of these two operations is broken: what will happen if the first step succeeds and the second step fails ?
It will cause the database to be the latest data and the cache to be the old data, resulting in consistency problems.
I will not draw this picture. Similar to the previous picture, just switch the positions of Redis and MySQL.
High Concurrency Scenario
Xie Bage often 996, backache and neck pain, more and more bugs written, want to massage and massage to improve programming skills.
Affected by the epidemic, the order is not easy to come by. The technicians of the high-end clubs are all scrambling to take this order, high concurrency brothers.
After entering the store, the front desk will enter the customer information into the system, and execute the initial value of set xx的服务技师 = 待定 means that there is no receptionist and save it to the database and cache, and then arrange for a technician massage service.
As shown below:

- Technician No. 98 started first, and sent the command
set 谢霸歌的服务技师 = 98to the system to write to the database. At this time, the system's network fluctuated and became stuck, and the data had not yet been written to the cache . - Next, technician 520 also sent
set 谢霸哥的服务技师 = 520to the system to write to the database, and also wrote this data to the cache. - At this time, the write cache request of the previous technician No. 98 started to be executed, and the data
set 谢霸歌的服务技师 = 98was successfully written into the cache.
Finally found that the database value = set 谢霸哥的服务技师 = 520 and the cached value = set 谢霸歌的服务技师 = 98 .
The latest data in the cache for technician 520 is overwritten by the old data for technician 98.
Therefore, in a high concurrency scenario, when multiple threads write data at the same time and then write to the cache, there will be an inconsistency in which the cache is the old value and the database is the latest value.
The program passes directly.
If the first step fails, a 50x exception will be returned directly, and there will be no data inconsistency.
3.3 Delete the cache first, then update the database
According to the routine mentioned earlier by "Code Brother", assuming that the first operation is successful and the second operation fails, what will happen? What happens in high concurrency scenarios?
The second step failed to write to the database
Suppose now there are two requests: write request A, read request B.
Write request A The first step is to delete the cache successfully, but to fail to write data to the database will result in the loss of the write data, and the database saves the old value .
Then another read request B to come in, find that the cache does not exist, read the old data from the database and write it to the cache.
Problems with high concurrency

- It is still better for technician No. 98 to start first. The system receives a request to delete the cached data. When the system prepares to write
set 肖菜鸡的服务技师 = 98to the database, a freeze occurs and it is too late to write. - At this time, the lobby manager executes a read request to the system to check if Xiaocaiji has a technician reception, which is convenient for arranging technician service. The system finds that there is no data in the cache, so it reads the old data from the database
set 肖菜鸡的服务技师 = 待定, and write to the cache. - At this time, the original stuck technician No. 98 wrote data
set 肖菜鸡的服务技师 = 98to the database operation completed.
In this way, old data will be cached, and the most data cannot be read before the cache expires. Xiao Caiji was already taken by technician No. 98, but the lobby manager thought no one was there.
This solution passes, because the first step succeeds and the second step fails, which will cause the database to be old data. If there is no data in the cache, the old value will continue to be read from the database and written to the cache, resulting in inconsistent data and one more cache.
Whether it is an abnormal situation or a high concurrency scenario, data inconsistency will result. miss.
3.4 Update the database first, then delete the cache
After the previous three schemes, all of them have been passed, and analyze whether the final scheme will work or not.
According to the "routine", judge the problems caused by abnormality and high concurrency respectively.
This strategy can know that if it fails in the writing database phase, it will return the client exception directly, and there is no need to perform the cache operation.
Therefore, if the first step fails, there will be no data inconsistency.
Failed to delete cache
The point is that the first step is to successfully write the latest data to the database, but what should I do if I fail to delete the cache?
You can put these two operations in a transaction, and when the cache deletion fails, the write database is rolled back.
Inappropriate in high concurrency scenarios, large transactions are prone to occur, resulting in deadlock problems.
If it is not rolled back, it will appear that the database is new data, cached or old data, and the data is inconsistent. What should I do?
Therefore, we have to find a way to make the cache deletion successful, otherwise we can only wait until the validity period expires.
Use a retry mechanism.
For example, retries three times, and if all three times fail, record the log to the database, and use the distributed scheduling component xxl-job to implement subsequent processing.
In high concurrency scenarios, it is best to use asynchronous methods for retry , such as sending messages to mq middleware to achieve asynchronous decoupling.
Or use the Canal framework to subscribe to the MySQL binlog log, monitor the corresponding update request, and perform the delete corresponding cache operation.
High Concurrency Scenario
Let's analyze what problems there will be with high concurrent read and write...

- Technician No. 98 started first, and took over the business of Xiaocaiji. The database executed
set 肖菜鸡的服务技师 = 98; the network was still stuck, and there was no time to delete the cache . - The supervisor, Candy, executed a read request to the system, checked if Xiaocaiji was received by a technician, and found that there was data in the cache
肖菜鸡的服务技师 = 待定, and directly returned the information to the client. The supervisor thought that no one was there. - The original technician No. 98 received the order, but the operation of the cache was not deleted due to the freeze, and the deletion is now successful.
The read request may read a small amount of old data, but the old data will be deleted soon, and subsequent requests can obtain the latest data, which is not a big problem.
There is also a more extreme situation. When the cache is automatically invalidated, it encounters a situation of high concurrent read and write. Suppose there will be two requests, one thread A does the query operation, and one thread B does the update operation, then there will be the following situation produce:

- When the expiration time of the cache expires, the cache is invalid.
- Thread A's read request reads the cache, and if it misses, the database is queried to get an old value (because B will write a new value, which is relatively the old value), and the network problem is stuck when preparing to write the data to the cache. .
- Thread B performs a write operation, writing the new value to the database.
- Thread B performs the delete cache.
- Thread A continues, wakes up from the freeze, and writes the old value queried into the cache.
Code brother, what are you playing, there are still inconsistencies.
Don't panic, the probability of this happening is very small, the necessary conditions for the above to happen are:
- The write database operation in step (3) takes less time and faster than the read operation in step (2), so that step (4) may be preceded by step (5).
- The cache has just reached its expiration time.
Usually the QPS of a MySQL single machine is about 5K, and the TPS is about 1k, (ps: Tomcat's QPS is about 4K, TPS = about 1k).
The database read operation is much faster than the write operation (it is precisely because of this that the read and write separation is performed), so it is difficult for step (3) to be faster than step (2).
Therefore, when using the cache bypass strategy, it is recommended to use the write operation: update the database first, and then delete the cache.
4. What are the conformance solutions?
Finally, for the Cache-Aside (cache-aside) strategy, when the write operation uses the database to be updated first, and then the cache is deleted , let's analyze what data consistency solutions are available?
4.1 Cache delay double deletion
How to avoid dirty data if you delete the cache first and then update the database?
A delayed double deletion strategy is adopted.
- Delete the cache first.
- write database.
- Sleep for 500 milliseconds, then delete the cache.
In this way, there will only be a maximum of 500 milliseconds of dirty data read time. The key is how to determine the sleep time?
The purpose of the delay time is to ensure that the read request ends, and the write request can delete the cached dirty data caused by the read request.
Therefore, we need to evaluate the time-consuming of the project's data reading business logic by ourselves, and add a few hundred milliseconds as the delay time on the basis of the reading time .
4.2 Delete cache retry mechanism
What should I do if the cache deletion fails? For example, if the second deletion of delayed double deletion fails, it means that dirty data cannot be deleted.
Use the retry mechanism to ensure that the cache deletion is successful.
For example, if it retries three times and fails three times, it will record the log to the database and send a warning for manual intervention.
In high concurrency scenarios, it is best to use asynchronous methods for retry , such as sending messages to mq middleware to achieve asynchronous decoupling.

Step (5) If the deletion fails and the maximum number of retries is not reached, the message will be re-queued until the deletion is successful, otherwise it will be recorded in the database for manual intervention.
The disadvantage of this scheme is that it causes intrusion into the business code, so there is the next scheme, starting a service that specifically subscribes to the database binlog to read the data to be deleted and perform the cache deletion operation.
4.3 Read binlog asynchronously delete

- update the database;
- The database will record the operation information in the binlog log;
- Use canal to subscribe to the binlog log to obtain the target data and key;
- The cache deletion system obtains canal data, parses the target key, and tries to delete the cache.
- If the deletion fails, send the message to the message queue;
- The cache deletion system obtains data from the message queue again and performs the deletion operation again.
Summarize
The best practice for a caching strategy is the Cache Aside Pattern. They are divided into read caching best practices and write caching best practices.
Read cache best practice: read the cache first, and return if it hits; query the database if it misses, and then write to the database.
Write caching best practices:
- Write the database first, then operate the cache;
- Directly delete the cache instead of modifying it, because when the update cost of the cache is high, it is necessary to access multiple tables for joint calculation. It is recommended to delete the cache directly instead of updating. In addition, the operation of deleting the cache is simple, and the side effect is only an increase of a chache miss, it is recommended Everyone uses this strategy.
Under the above best practices, in order to ensure the consistency between the cache and the database as much as possible, we can use delayed double deletion.
To prevent deletion failure, we use asynchronous retry mechanism to ensure correct deletion, asynchronous mechanism, we can send deletion message to mq message middleware, or use canal to subscribe MySQL binlog log to monitor write request to delete the corresponding cache.
So, what if I have to guarantee absolute consistency, first give the conclusion:
There is no way to achieve absolute consistency, which is determined by the CAP theory. The applicable scenario of the cache system is the scenario of non-strong consistency, so it belongs to the AP in the CAP.
Therefore, we have to compromise, and we can achieve the eventual consistency in the BASE theory.
In fact, once the cache is used in the scheme, it often means that we give up the strong consistency of the data, but it also means that our system can get some improvements in performance.
The so-called tradeoff is exactly that.
Finally, can you call me pretty boy in the comment area? "Like" and "watching" that don't want to call me pretty are also a kind of encouragement.
Add "code brother" WeChat: MageByte1024, enter the exclusive reader technology group to chat about technology.
thanks
https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
https://blog.cdemi.io/design-patterns-cache-aside-pattern/
https://hazelcast.com/blog/a-hitchhikers-guide-to-caching-patterns/




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。