
大家好,我是「码哥」,大家可以叫我靓仔。
这次码哥跟大家分享一些优化神技,当你面试或者工作中你遇到如下问题,那就使出今天学到的绝招,一招定乾坤!
如何用更少的内存保存更多的数据?
我们应该从 Redis 是如何保存数据的原理展开,分析键值对的存储结构和原理。
从而继续延展出每种数据类型底层的数据结构,针对不同场景使用更恰当的数据结构和编码实现更少的内存占用。
为了保存数据, Redis 需要先申请内存,数据过期或者内存淘汰需要回收内存,从而拓展出内存碎片优化。
最后,说下 key、value 使用规范和技巧、 Bitmap 等高阶数据类型,运用这些技巧巧妙解决有限内存去存储更多数据难题……
这一套组合拳下来直接封神。
具体详情,且看「码哥」一一道来。
主要优化神技如下:
- 键值对优化;
- 小数据集合的编码优化;
- 使用对象共享池;
- 使用 Bit 比特位或 byte 级别操作
- 使用 hash 类型优化;
- 内存碎片优化;
- 使用 32 位的 Redis。
在优化之前,我们先掌握 Redis 是如何存储数据的。
Redis 如何存储键值对
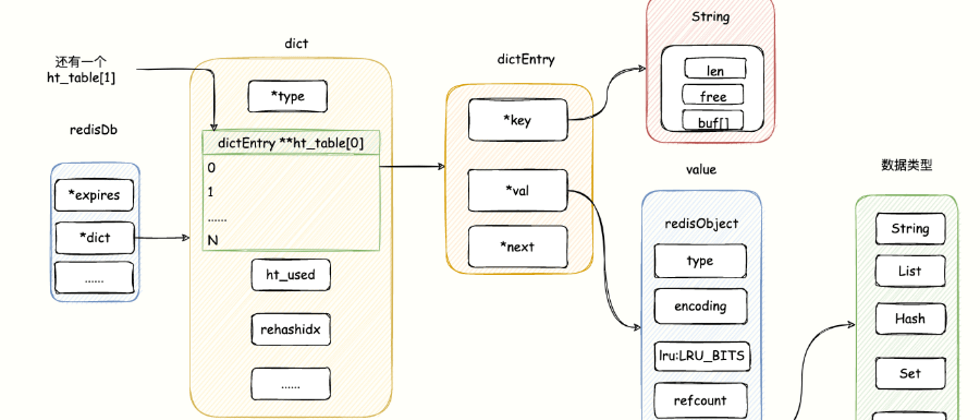
Redis 以 redisDb为中心存储,redis 7.0 源码在 https://github.com/redis/redis/blob/7.0/src/server.h:

- dict:最重要的属性之一,就是靠这个定义了保存了对象数据键值对,dcit 的底层结构是一个哈希表。
- expires:保存着所有 key 的过期信息.
- blocking_keys 和 ready_keys 主要为了实现 BLPOP 等阻塞命令
- watched_keys用于实现watch命令,记录正在被watch的一些key,与事务相关。
- id 为当前数据库的id,redis 支持单个服务多数据库,默认有16个;
- clusterSlotToKeyMapping:cluster 模式下,存储key 与哈希槽映射关系的数组。
Redis 使用「dict」结构来保存所有的键值对(key-value)数据,这是一个全局哈希表,所以对 key 的查询能以 O(1) 时间得到。
所谓哈希表,我们可以类比 Java 中的 HashMap,其实就是一个数组,数组的每个元素叫做哈希桶。
dict 结构如下,源码在 https://github.com/redis/redis/blob/7.0/src/dict.h:
struct dict {
// 特定类型的处理函数
dictType *type;
// 两个全局哈希表指针数组,与渐进式 rehash 有关
dictEntry **ht_table[2];
// 记录 dict 中现有的数据个数。
unsigned long ht_used[2];
// 记录渐进式 rehash 进度的标志, -1 表示当前没有执行 rehash
long rehashidx;
// 小于 0 表示 rehash 暂停
int16_t pauserehash;
signed char ht_size_exp[2];
};- dictType:存储了hash函数,key和value的复制等函数;
- ht_table:长度为 2 的 数组,正常情况使用 ht_table[0] 存储数据,当执行 rehash 的时候,使用 ht_table[1] 配合完成 。
key 的哈希值最终会映射到 ht_table 的一个位置,如果发生哈希冲突,则拉出一个哈希链表。
大家重点关注 dictEntry 的 ht_table,ht_table 数组每个位置我们也叫做哈希桶,就是这玩意保存了所有键值对。
码哥,Redis 支持那么多的数据类型,哈希桶咋保存?
哈希桶的每个元素的结构由 dictEntry 定义:
typedef struct dictEntry {
// 指向 key 的指针
void *key;
union {
// 指向实际 value 的指针
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 哈希冲突拉出的链表
struct dictEntry *next;
} dictEntry;- key 指向键值对的键的指针,key 都是 string 类型。
- value 是个 union(联合体)当它的值是 uint64_t、int64_t 或 double 类型时,就不再需要额外的存储,这有利于减少内存碎片。(为了节省内存操碎了心)当然,val 也可以是 void 指针,指向值的指针,以便能存储任何类型的数据。
- next 指向另一个 dictEntry 结构, 多个 dictEntry 可以通过 next 指针串连成链表, 从这里可以看出, ht_table 使用链地址法来处理键碰撞: 当多个不同的键拥有相同的哈希值时,哈希表用一个链表将这些键连接起来。
哈希桶并没有保存值本身,而是指向具体值的指针,从而实现了哈希桶能存不同数据类型的需求。
而哈希桶中,键值对的值都是由一个叫做 redisObject 的对象定义,源码地址:https://github.com/redis/redis/blob/7.0/src/server.h。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;- type: 记录了对象的类型,string、set、hash 、Lis、Sorted Set 等,根据该类型才可以确定是哪种数据类型,使用什么样的 API 操作。
- encoding:编码方式,表示 ptr 指向的数据类型具体数据结构,即这个对象使用了什么数据结构作为底层实现保存数据。同一个对象使用不同编码实现内存占用存在明显差异,内部编码对内存优化非常重要。
- lru:LRU_BITS:LRU 策略下对象最后一次被访问的时间,如果是 LFU 策略,那么低 8 位表示访问频率,高 16 位表示访问时间。
- refcount :表示引用计数,由于 C 语言并不具备内存回收功能,所以 Redis 在自己的对象系统中添加了这个属性,当一个对象的引用计数为 0 时,则表示该对象已经不被任何对象引用,则可以进行垃圾回收了。
- ptr 指针:指向对象的底层实现数据结构,指向值的指针。
如下图是由 redisDb、dict、dictEntry、redisObejct 关系图:

「码哥」再唠叨几句,void key 和 void value 指针指向的是 redis对象,因为 Redis 中每个对象都是用 redisObject 表示。
知道了 Redis 存储原理以及不同数据类型的存储数据结构后,我们继续看如何做性能优化。
1. 键值对优化
当我们执行 set key value 的命令,*key指针指向 SDS 字符串保存 key,而 value 的值保存在 *ptr 指针指向的数据结构,消耗的内存:key + value。
第一个优化神技:降低 Redis 内存使用的最粗暴的方式就是缩减键(key)与值(value)的长度。
在《Redis 很强,不懂使用规范就糟蹋了》中我说过关于键值对的使用规范,对于 key 的命名使用「业务模块名:表名:数据唯一id」这样的方式方便定位问题。
比如:users:firends:996 表示用户系统中,id = 996 的朋友信息。我们可以简写为:u:fs:996
对于 key 的优化:使用单词简写方式优化内存占用。
对于 value 的优化那就更多了:
- 过滤不必要的数据:不要大而全的一股脑将所有信息保存,想办法去掉一些不必要的属性,比如缓存登录用户的信息,通常只需要存储昵称、性别、账号等。
- 精简数据:比如用户的会员类型:0 表示「屌丝」、1 表示 「VIP」、2表示「VVIP」。而不是存储 VIP 这个字符串。
- 数据压缩:对数据的内容进行压缩,比如使用 GZIP、Snappy。
使用性能好,内存占用小的序列化方式。比如 Java 内置的序列化不管是速度还是压缩比都不行,我们可以选择 protostuff,kryo等方式。如下图 Java 常见的序列化工具空间压缩比:
靓仔们,我们通常使用 json 作为字符串存储在 Redis,用 json 存储与二进制数据存储有什么优缺点呢?
json 格式的优点:方便调试和跨语言;缺点是:同样的数据相比字节数组占用的空间更大。
一定要 json 格式的话,那就先通过压缩算法压缩 json,再把压缩后的数据存入 Redis。比如 GZIP 压缩后的 json 可降低约 60% 的空间。

2. 小数据集合编码优化
key 对象都是 string 类型,value 对象主要有五种基本数据类型:String、List、Set、Zset、Hash。
数据类型与底层数据结构的关系如下所示:

特别说明下在最新版(非稳定版本,时间 2022-7-3),ziplist 压缩列表由 quicklist 代替(3.2 版本引入),而双向链表由 listpack 代替。
另外,同一数据类型会根据键的数量和值的大小也有不同的底层编码类型实现。
在 Redis 2.2 版本之后,存储集合数据(Hash、List、Set、SortedSet)在满足某些情况下会采用内存压缩技术来实现使用更少的内存存储更多的数据。
当这些集合中的数据元素数量小于某个值且元素的值占用的字节大小小于某个值的时候,存储的数据会用非常节省内存的方式进行编码,理论上至少节省 10 倍以上内存(平均节省 5 倍以上)。
比如 Hash 类型里面的数据不是很多,虽然哈希表的时间复杂度是 O(1),ziplist 的时间复杂度是 O(n),但是使用 ziplist 保存数据的话会节省了内存,并且在少量数据情况下效率并不会降低很多。
所以我们需要尽可能地控制集合元素数量和每个元素的内存大小,这样能充分利用紧凑型编码减少内存占用。
并且,这些编码对用户和 api 是无感知的,当集合数据超过配置文件的配置的最大值, Redis 会自动转成正常编码。
数据类型对应的编码规则如下所示
String 字符串
- int:整数且数字长度小于 20,直接保存在 *ptr 中。
- embstr:开辟一块连续分配的内存(字符串长度小于等于 44 字节)。
- raw:动态字符串(大于 44 字节的字符串,同时字符串小于 512 MB)。
List 列表
ziplist:元素个数小于
hash-max-ziplist-entries配置,同时所所的元素的值大小都小于hash-max-ziplist-value配置。- linkedlist:3.0 版本之前当列表类型无法满足 ziplist 的条件时,Redis会使用 linkedlist 作为列表的内部实现。
- quicklist:Redis 3.2 引入,并作为 List 数据类型的底层实现,不再使用双端链表 linkedlist 和 ziplist 实现。

Set 集合
- intset 整数集合:元素都是整数,且元素个数小于
set-max-intset-entries配置 - hashtable 哈希表:集合类型无法满足intset的条件时就会使用hashtable 编码。
Hash 哈希表
- ziplist:元素个数小于
hash-max-ziplist-entries配置,同时任意一个 value 的占用字节大小都小于hash-max-ziplist-value。 - hashtable:hash 类型无法满足 intset 的条件时就会使用hashtable。
Sorted Set 有序集合
- ziplist:元素个数小于
zset-max-ziplist-entries同时每个元素的value小于`zset-max-ziplist-value配置。 - skiplist:当ziplist条件不满足时,有序集合会使用skiplist作为内部实现。
以下是 Redis redis.conf 配置文件默认编码阈值配置:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
set-max-intset-entries 512下图是 reidsObject 对象的 type 和 encoding 对应关系图:

码哥,为啥对一种数据类型实现多种不同编码方式?
主要原因是想通过不同编码实现效率和空间的平衡。
比如当我们的存储只有100个元素的列表,当使用双向链表数据结构时,需要维护大量的内部字段。
比如每个元素需要:前置指针,后置指针,数据指针等,造成空间浪费。
如果采用连续内存结构的压缩列表(ziplist),将会节省大量内存,而由于数据长度较小,存取操作时间复杂度即使为O(n) 性能也相差不大,因为 n 值小 与 O(1) 并明显差别。
数据编码优化技巧
ziplist 存储 list 时每个元素会作为一个 entry,存储 hash 时 key 和 value 会作为相邻的两个 entry。
存储 zset 时 member 和 score 会作为相邻的两个entry,当不满足上述条件时,ziplist 会升级为 linkedlist, hashtable 或 skiplist 编码。
由于目前大部分Redis运行的版本都是在3.2以上,所以 List 类型的编码都是quicklist。
quicklist 是 ziplist 和 linkedlist 的混合体,它将 linkedlist 按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来。
考虑了综合平衡空间碎片和读写性能两个维度所以使用了个新编码 quicklist。

ziplist 的不足
每次修改都可能触发 realloc 和 memcopy, 可能导致连锁更新(数据可能需要挪动)。
因此修改操作的效率较低,在 ziplist 的元素很多时这个问题更加突出。
优化手段:
- key 尽量控制在 44 字节以内,走 embstr 编码。
- 集合类型的 value 对象的元素个数不要太多太大,充分利用 ziplist 编码实现内存压缩。
3. 对象共享池
整数我们经常在工作中使用,Redis 在启动的时候默认后生成一个 0 ~9999 的整数对象共享池用于对象复用,减少内存占用。
比如执行set 码哥 18; set 吴彦祖 18; key 等于 「码哥」 和「吴彦祖」的 value 都指向同一个对象。
如果 value 可以使用整数表示的话尽可能使用整数,这样即使大量键值对的 value 大量保存了 0~9999 范围内的整数,在实例中,其实只有一份数据。
靓仔们,有两个大坑遇到注意,它会导致对象共享池失效。
Redis 中设置了 maxmemory 限制最大内存占用大小且启用了 LRU 策略(allkeys-lru 或 volatile-lru 策略)。
码哥,为啥呀?
因为 LRU 需要记录每个键值对的访问时间,都共享一个整数 对象,LRU 策略就无法进行统计了。
集合类型的编码采用 ziplist 编码,并且集合内容是整数,也不能共享一个整数对象。
这又是为啥呢?
使用了 ziplist 紧凑型内存结构存储数据,判断整数对象是否共享的效率很低。
4.使用 Bit 比特位或 byte 级别操作
比如在一些「二值状态统计」的场景下使用 Bitmap 实现,对于网页 UV 使用 HyperLogLog 来实现,大大减少内存占用。
码哥,什么是二值状态统计呀?
也就是集合中的元素的值只有 0 和 1 两种,在签到打卡和用户是否登陆的场景中,只需记录签到(1)或 未签到(0),已登录(1)或未登陆(0)。
假如我们在判断用户是否登陆的场景中使用 Redis 的 String 类型实现(key -> userId,value -> 0 表示下线,1 - 登陆),假如存储 100 万个用户的登陆状态,如果以字符串的形式存储,就需要存储 100 万个字符串,内存开销太大。
String 类型除了记录实际数据以外,还需要额外的内存记录数据长度、空间使用等信息。
Bitmap 的底层数据结构用的是 String 类型的 SDS 数据结构来保存位数组,Redis 把每个字节数组的 8 个 bit 位利用起来,每个 bit 位 表示一个元素的二值状态(不是 0 就是 1)。
可以将 Bitmap 看成是一个 bit 为单位的数组,数组的每个单元只能存储 0 或者 1,数组的下标在 Bitmap 中叫做 offset 偏移量。
为了直观展示,我们可以理解成 buf 数组的每个字节用一行表示,每一行有 8 个 bit 位,8 个格子分别表示这个字节中的 8 个 bit 位,如下图所示:

8 个 bit 组成一个 Byte,所以 Bitmap 会极大地节省存储空间。 这就是 Bitmap 的优势。
关于 Bitmap 的详细解答,大家可移步 -> 《Redis 实战篇:巧用 Bitmap 实现亿级数据统计》。
5. 妙用 Hash 类型优化
尽可能把数据抽象到一个哈希表里。
比如说系统中有一个用户对象,我们不需要为一个用户的昵称、姓名、邮箱、地址等单独设置一个 key,而是将这个信息存放在一个哈希表里。
如下所示:
hset users:深圳:999 姓名 码哥
hset users:深圳:999 年龄 18
hset users:深圳:999 爱好 女为啥使用 String 类型,为每个属性设置一个 key 会占用大量内存呢?
因为 Redis 的数据类型有很多,不同数据类型都有些相同的元数据要记录(比如最后一次访问的时间、被引用的次数等)。
所以,Redis 会用一个 RedisObject 结构体来统一记录这些元数据,用 *prt 指针指向实际数据。
当我们为每个属性都创建 key,就会创建大量的 redisObejct 对象占用内存。
如下所示 redisObject 内存占用:

用 Hash 类型的话,每个用户只需要设置一个 key。
6. 内存碎片优化
Redis 释放的内存空间可能并不是连续的,这些不连续的内存空间很有可能处于一种闲置的状态。
虽然有空闲空间,Redis 却无法用来保存数据,不仅会减少 Redis 能够实际保存的数据量,还会降低 Redis 运行机器的成本回报率。
比如, Redis 存储一个整形数字集合需要一块占用 32 字节的连续内存空间,当前虽然有 64 字节的空闲,但是他们都是不连续的,导致无法保存。
内存碎片是如何形成呢?
两个层面原因导致:
- 操作系统内存分配机制:内存分配策略决定了无法做到按需分配。因为分配器是按照固定大小来分配内存。
- 键值对被修改和删除,从而导致内存空间的扩容和释放。
碎片优化可以降低内存使用率,提高访问效率,在4.0以下版本,我们只能使用重启恢复:重启加载 RDB 或者通过高可用主从切换实现数据的重新加载减少碎片。
在4.0以上版本,Redis提供了自动和手动的碎片整理功能,原理大致是把数据拷贝到新的内存空间,然后把老的空间释放掉,这个是有一定的性能损耗的。
因为 Redis 是单线程,在数据拷贝时,Redis 只能等着,这就导致 Redis 无法处理请求,性能就会降低。
手动整理碎片
执行 memory purge命令即可。
自动整理内存碎片
使用 config set activedefrag yes 指令或者在 redis.conf 配置 activedefrag yes 将 activedefrag 配置成 yes 表示启动自动清理功能。
这个配置还不够,至于啥时候清理还需要看下面的两个配置:
- active-defrag-ignore-bytes 200mb:内存碎片的大小达到 200MB,开始清理。
- active-defrag-threshold-lower 6:表示内存碎片空间占操作系统分配给 Redis 的总空间比例达到 6% 时,开始清理。
只有满足这两个条件, Redis 才会执行内存碎片自动清理。
除此之外,Redis 为了防止清理碎片对 Redis 正常处理指令造成影响,有两个参数用于控制清理操作占用 CPU 的时间比例上下限。
- active-defrag-cycle-min 15: 自动清理过程所用 CPU 时间的比例不低于 15%,保证清理能有效展开。
- active-defrag-cycle-max 50:表示自动清理过程所用 CPU 时间的比例不能大于 50%,一旦超过,就停止清理,从而避免在清理时,大量的内存拷贝阻塞 Redis执行命令。
7. 使用 32 位的 Redis
使用32位的redis,对于每一个key,将使用更少的内存,因为32位程序,指针占用的字节数更少。
但是32的Redis整个实例使用的内存将被限制在4G以下。我们可以通过 cluster 模式将多个小内存节点构成一个集群,从而保存更多的数据。
另外小内存的节点 fork 生成 rdb 的速度也更快。
RDB和AOF文件是不区分32位和64位的(包括字节顺序),所以你可以使用64位的Redis 恢复32位的RDB备份文件,相反亦然。
总结
打完收工,这一套神技下来,只想说一个字「绝」。
希望这篇文章,能帮你使用全局视角去破解内存优化难题,我是「码哥」,下回 Redis 再见。
想要加技术群的少年留步,扫描备注「加群」,进专属技术读者群一起吹牛逼。
看到这里的靓仔,给个「三连」写个评论呀,靓仔。
参考文献
[1]https://redis.io/docs/referen...
[2]《Redis 核心技术与实战》


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。