
Hello everyone, I'm "Brother Code", you can call me pretty boy.
This time, the code brother will share some optimization skills with you. When you encounter the following problems in your interview or work, you can use the tricks you learned today, and one trick will set the world!
How to save more data with less memory?
We should start from the principle of how Redis saves data, and analyze the storage structure and principle of key-value pairs.
This continues to extend the underlying data structure of each data type, and uses more appropriate data structures and encodings for different scenarios to achieve less memory usage.
In order to save data, Redis needs to apply for memory first, and the memory needs to be reclaimed when the data expires or the memory is eliminated, thereby expanding the optimization of memory fragmentation.
Finally, let's talk about key and value usage specifications and techniques, Bitmap and other high-level data types, and use these techniques to cleverly solve the problem of storing more data in limited memory...
This set of combined punches directly conferred gods.
For specific details, let's see "Code Brother" one by one.
The main optimization skills are as follows:
- Key-value pair optimization;
- Coding optimization for small data sets;
- Use object shared pool;
- Use Bit-bit or byte-level operations
- Use hash type optimization;
- Memory fragmentation optimization;
- Use 32-bit Redis.
Before optimizing, let's first grasp how Redis stores data.
How Redis stores key-value pairs
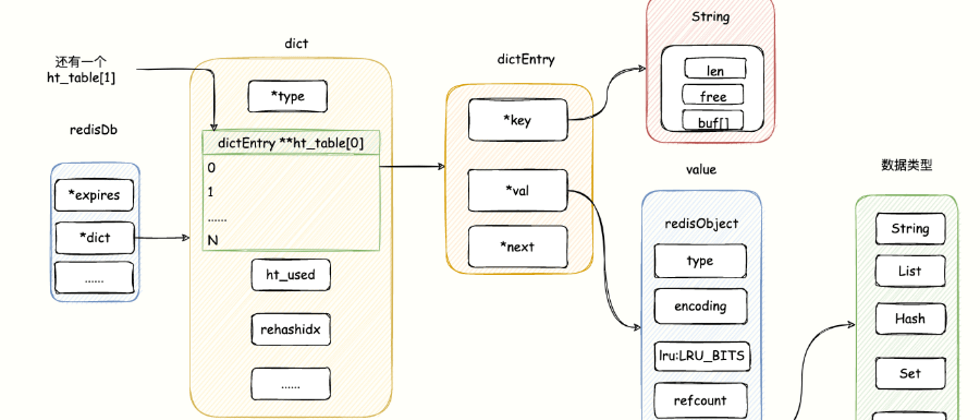
Redis is stored around redisDb 132fa407760f2d483f1326cd201c7f7f---, and the source code of redis 7.0 is in https://github.com/redis/redis/blob/7.0/src/server.h :

- dict: One of the most important attributes is that the key-value pair of object data is saved by this definition. The underlying structure of dcit is a hash table.
- expires: saves the expiration information of all keys.
- blocking_keys and ready_keys are mainly used to implement blocking commands such as BLPOP
- watched_keys is used to implement the watch command, recording some keys that are being watched, related to transactions.
- id is the id of the current database , redis supports multiple databases for a single service, and there are 16 by default;
- clusterSlotToKeyMapping: In cluster mode, an array that stores the mapping relationship between keys and hash slots.
Redis uses a "dict" structure to store all key-value data, which is a global hash table, so queries for keys can be obtained in O(1) time.
The so-called hash table, we can compare it with HashMap in Java, which is actually an array, and each element of the array is called a hash bucket.
The dict structure is as follows, the source code is in https://github.com/redis/redis/blob/7.0/src/dict.h :
struct dict {
// 特定类型的处理函数
dictType *type;
// 两个全局哈希表指针数组,与渐进式 rehash 有关
dictEntry **ht_table[2];
// 记录 dict 中现有的数据个数。
unsigned long ht_used[2];
// 记录渐进式 rehash 进度的标志, -1 表示当前没有执行 rehash
long rehashidx;
// 小于 0 表示 rehash 暂停
int16_t pauserehash;
signed char ht_size_exp[2];
};- dictType: stores functions such as hash function, key and value replication;
- ht_table: an array of length 2. Normally, ht_table[0] is used to store data. When rehash is executed, ht_table[1] is used to complete it.
The hash value of the key will eventually be mapped to a location in ht_table, and if a hash collision occurs, a hash linked list will be pulled.
Everyone should pay attention to the ht_table of dictEntry . Each position of the ht_table array is also called a hash bucket, which is what saves all key-value pairs.
Code brother, Redis supports so many data types, how to save the hash bucket?
The structure of each element of the hash bucket is defined by dictEntry:
typedef struct dictEntry {
// 指向 key 的指针
void *key;
union {
// 指向实际 value 的指针
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 哈希冲突拉出的链表
struct dictEntry *next;
} dictEntry;- key Pointer to the key of the key-value pair, all keys are of type string.
- value is a union (union) when its value is of type uint64_t, int64_t or double, no additional storage is required, which helps reduce memory fragmentation. (Broken my heart to save memory) Of course, val can also be a void pointer, a pointer to a value, so that it can store any type of data.
- next points to another dictEntry structure, and multiple dictEntry can be concatenated into a linked list through the next pointer. It can be seen from this that ht_table uses the chain address method to deal with key collisions: when multiple different keys have the same hash value, ha The table uses a linked list to connect these keys.
The hash bucket does not store the value itself, but a pointer to a specific value, thus realizing the requirement that the hash bucket can store different data types .
In the hash bucket, the value of the key-value pair is defined by an object called redisObject , and the source address is: https://github.com/redis/redis/blob/7.0/src/server.h .
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;- type : Records the type of the object, string, set, hash, Lis, Sorted Set, etc. According to the type, which data type can be determined and what API operation is used.
- encoding : encoding method, indicating the specific data structure of the data type pointed to by ptr, that is, what data structure is used by this object as the underlying implementation to save data. There are obvious differences in the memory usage of the same object using different encodings, and the internal encoding is very important for memory optimization.
- lru:LRU_BITS: The last time the object was accessed under the LRU policy. If it is the LFU policy, the lower 8 bits represent the access frequency, and the upper 16 bits represent the access time.
- refcount : Represents the reference count. Since the C language does not have the function of memory recovery, Redis adds this attribute to its own object system. When the reference count of an object is 0, it means that the object is no longer referenced by any object. Garbage collection is available.
- ptr pointer: pointer to the underlying implementation data structure of the object, pointer to value .
The following figure shows the relationship between redisDb, dict, dictEntry, and redisObejct:

"Code Brother" chatter a few more words, void key and void value pointers point to redis objects , because each object in Redis is represented by redisObject .
After knowing the storage principle of Redis and the storage data structure of different data types, let's continue to see how to optimize performance.
1. Key-value optimization
当set key value的命令, *key指针指向SDS 字符串保存key, value *ptr指针指向的Data structure, memory consumed: key + value.
The first optimization trick: The crudest way to reduce Redis memory usage is to reduce the length of keys and values.
In " Redis is very strong, if you don't know how to use it, you will waste it ", I said about the use of key-value pairs. For the naming of keys, the method of "business module name: table name: data unique id" is used to locate the problem.
For example: users:firends:996 means friend information with id = 996 in the user's system. We can abbreviate it as: u:fs:996
For key optimization: use word shorthand to optimize memory usage.
For the optimization of value it is more:
- Filter unnecessary data : Don't store all the information in a big and comprehensive way, and try to remove some unnecessary attributes, such as caching the information of logged-in users, usually only need to store nickname, gender, account number, etc.
- Simplified data : For example, the user's membership type: 0 means "diaosi", 1 means "VIP", and 2 means "VVIP". Instead of storing the VIP string.
- Data compression: Compress the content of the data, such as using GZIP, Snappy.
Serialization method with good performance and small memory footprint . For example, Java's built-in serialization is not good for speed or compression ratio. We can choose protostuff, kryo and other methods. The following figure shows the space compression ratio of common serialization tools in Java:
Guys, we usually use json as a string to store in Redis. What are the advantages and disadvantages of using json storage and binary data storage?
Advantages of json format: easy debugging and cross-language; disadvantages: the same data takes up more space than byte arrays.
If it must be in json format, then compress json through a compression algorithm, and then store the compressed data in Redis. For example, GZIP compressed json can reduce the space by about 60%.

2. Small data set encoding optimization
The key objects are all string types, and the value objects mainly have five basic data types: String, List, Set, Zset, and Hash .
The relationship between data types and underlying data structures is as follows:

In the latest version (unstable version, time 2022-7-3), the ziplist compressed list is replaced by quicklist (introduced in version 3.2), and the doubly linked list is replaced by listpack.
In addition, the same data type will have different underlying encoding types based on the number of keys and the size of the value.
After Redis 2.2 version, storage collection data (Hash, List, Set, SortedSet) will use memory compression technology to store more data with less memory under certain conditions.
When the number of data elements in these sets is less than a certain value and the byte size occupied by the value of the element is less than a certain value, the stored data will be encoded in a very memory-saving way, theoretically saving at least 10 times more memory ( average savings of more than 5x).
For example, there is not a lot of data in the Hash type. Although the time complexity of the hash table is O(1) and the time complexity of ziplist is O(n), using ziplist to save data will save memory, and in the case of a small amount of data Efficiency will not be reduced much.
So we need to control the number of collection elements and the memory size of each element as much as possible, so that we can make full use of compact encoding to reduce memory usage.
Moreover, these encodings are insensitive to users and apis. When the collection data exceeds the maximum value configured in the configuration file, Redis will automatically convert to normal encoding.
The encoding rules corresponding to the data types are as follows
String String
- int: integer and the number length is less than 20, directly stored in *ptr.
- embstr: Open up a block of contiguously allocated memory (the length of the string is less than or equal to 44 bytes).
- raw: dynamic strings (strings larger than 44 bytes, while strings smaller than 512 MB).
List list
ziplist: The number of elements is less than
hash-max-ziplist-entriesconfiguration, and the value of all elements is smaller thanhash-max-ziplist-valueconfiguration.- linkedlist: Before version 3.0, when the list type cannot meet the conditions of ziplist, Redis will use linkedlist as the internal implementation of the list.
- quicklist: Introduced in Redis 3.2 and used as the underlying implementation of the List data type, the double-ended linked list linkedlist and ziplist implementations are no longer used.

Set collection
- intset set of integers: the elements are all integers, and the number of elements is less than
set-max-intset-entriesconfiguration - hashtable hash table: hashtable encoding is used when the collection type cannot meet the conditions of intset.
Hash hash table
- ziplist: The number of elements is less than
hash-max-ziplist-entriesconfiguration, and the occupied byte size of any value is less thanhash-max-ziplist-value. - hashtable: hashtable is used when the hash type cannot satisfy the condition of intset.
Sorted Set
- ziplist: the number of elements is less than
zset-max-ziplist-entriesand the value of each element is less than`zset-max-ziplist-valueconfigure. - skiplist: When the ziplist condition is not met, the sorted set will use skiplist as the internal implementation.
The following is the default encoding threshold configuration of the Redis redis.conf configuration file:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
set-max-intset-entries 512 The following figure shows the correspondence between the type and encoding of the reidsObject object:

Code brother, why implement multiple different encoding methods for one data type?
The main reason is to achieve a balance between efficiency and space through different encodings.
For example, when we store a list with only 100 elements, when using a doubly linked list data structure, we need to maintain a large number of internal fields.
For example, each element needs: pre-pointer, post-pointer, data pointer, etc., resulting in a waste of space.
If the compressed list (ziplist) of continuous memory structure is used, a lot of memory will be saved, and due to the small data length, the time complexity of the access operation is not much different even if the performance is O(n), because the small value of n is similar to O( 1) and there is a significant difference.
Data Encoding Optimization Tips
When ziplist stores list, each element will be used as an entry, and when storing hash, key and value will be used as two adjacent entries.
When storing zset, member and score will be used as two adjacent entries. When the above conditions are not met, the ziplist will be upgraded to linkedlist, hashtable or skiplist encoding.
Since most of the current versions of Redis are running above 3.2, the encoding of List type is quicklist .
quicklist is a mixture of ziplist and linkedlist, it divides linkedlist into segments, each segment uses ziplist for compact storage, and multiple ziplists are concatenated using two-way pointers.
Considering the two dimensions of comprehensive balance of space fragmentation and read and write performance, a new encoding quicklist is used.

Disadvantages of ziplist
Each modification may trigger realloc and memcopy, which may lead to chain updates (data may need to be moved).
Therefore, the efficiency of the modification operation is low, and this problem is more prominent when there are many elements in the ziplist.
Optimization means:
- The key should be controlled within 44 bytes as much as possible, and use embstr encoding.
- The number of elements of the value object of the collection type should not be too large, and make full use of ziplist encoding to achieve memory compression.
3. Object Shared Pool
We often use integers in our work. Redis generates a shared pool of integer objects ranging from 0 to 9999 by default when it starts up for object reuse and reduces memory usage .
For example, when executing set 码哥 18; set 吴彦祖 18; the key is equal to the value of "Brother Code" and "Yanzu Wu" both point to the same object.
If the value can be represented by an integer, use an integer as much as possible, so that even if the value of a large number of key-value pairs stores a large number of integers in the range of 0~9999, in the example, there is actually only one piece of data.
Beauties, there are two big pits to pay attention to, which will cause the object shared pool to fail.
In Redis, maxmemory is set to limit the maximum memory footprint and the LRU strategy (allkeys-lru or volatile-lru strategy) is enabled.
Code brother, why?
Because LRU needs to record the access time of each key-value pair, they all share an integer object, so the LRU strategy cannot be counted.
The encoding of the collection type adopts ziplist encoding, and the content of the collection is integer, and cannot share an integer object.
Why is this?
Using the ziplist compact memory structure to store data, it is very inefficient to determine whether integer objects are shared.
4. Use Bit-bit or byte-level operations
For example, in some scenarios of "binary state statistics", Bitmap is used, and HyperLogLog is used for web page UV, which greatly reduces memory usage.
Code brother, what is binary state statistics?
That is, the values of the elements in the collection are only 0 and 1. In the scenario of check-in and check-in and whether the user is logged in, just record 签到(1) or 未签到(0) , 已登录(1) --or 已登录(1) 未登陆(0) .
If we use Redis's String type implementation in the scenario of judging whether a user is logged in ( key -> userId, value -> 0 means offline, 1 - login ), if the login status of 1 million users is stored, if the string Form storage, it needs to store 1 million strings, and the memory overhead is too large.
In addition to recording the actual data, the String type also needs additional memory to record data length, space usage and other information.
The underlying data structure of Bitmap uses the SDS data structure of String type to store the bit array. Redis uses the 8 bits of each byte array, and each bit represents the binary state of an element (either 0 or 1 ).
Bitmap can be regarded as a bit-unit array, each unit of the array can only store 0 or 1, the subscript of the array is called offset offset in Bitmap.
For visual display, we can understand that each byte of the buf array is represented by a row, each row has 8 bits, and the 8 grids respectively represent the 8 bits in the byte, as shown in the following figure:

8 bits form a Byte, so Bitmap will greatly save storage space. This is the advantage of Bitmap.
For detailed answers about Bitmap, you can go to -> "Redis Actual Combat: Using Bitmap to Achieve Billion-Level Data Statistics" .
5. Magical use of Hash type optimization
Abstract the data into a hash table as much as possible.
For example, if there is a user object in the system, we do not need to set a separate key for a user's nickname, name, email address, address, etc., but store this information in a hash table.
As follows:
hset users:深圳:999 姓名 码哥
hset users:深圳:999 年龄 18
hset users:深圳:999 爱好 女Why use String type, setting a key for each property will take up a lot of memory?
Because there are many data types in Redis, different data types have the same metadata to be recorded (such as the last access time, the number of references, etc.).
Therefore, Redis will use a RedisObject structure to record these metadata uniformly, and use the *prt pointer to point to the actual data.
When we create a key for each property, a large number of redisObejct objects are created that take up memory.
The memory footprint of redisObject is as follows:

With Hash type, each user only needs to set one key.
6. Memory fragmentation optimization
The memory space released by Redis may not be continuous, and these discontinuous memory spaces are likely to be in an idle state.
Although there is free space, Redis cannot be used to save data, which will not only reduce the amount of data that Redis can actually save, but also reduce the cost-return rate of Redis running machines.
For example, Redis needs a continuous memory space of 32 bytes to store a set of integer numbers. Although there are currently 64 bytes of free space, they are all discontinuous and cannot be saved.
How is memory fragmentation formed?
There are two reasons for this:
- Operating system memory allocation mechanism: The memory allocation strategy determines that on-demand allocation cannot be achieved. Because the allocator allocates memory according to a fixed size.
- Key-value pairs are modified and deleted, resulting in the expansion and release of memory space.
Fragmentation optimization can reduce memory usage and improve access efficiency. In versions below 4.0, we can only use restart recovery: restart loading RDB or reload data to reduce fragmentation through high-availability master-slave switching.
In versions 4.0 and above, Redis provides automatic and manual defragmentation functions. The principle is roughly to copy data to a new memory space, and then release the old space, which has a certain performance loss.
Because Redis is a single thread, when data is copied, Redis can only wait, which causes Redis to be unable to process the request, and the performance will be reduced.
Defrag manually
Execute the memory purge command.
Automatically defragment memory
Use the config set activedefrag yes command or configure activedefrag yes in redis.conf to configure activedefrag to yes to start the automatic cleaning function.
This configuration is not enough. As for when to clean up, you need to look at the following two configurations:
- active-defrag-ignore-bytes 200mb: The size of the memory fragment reaches 200MB and starts to be cleaned up.
- active-defrag-threshold-lower 6: Indicates that the cleanup starts when the memory fragmentation space accounts for 6% of the total space allocated to Redis by the operating system.
Only when these two conditions are met, Redis will perform automatic cleanup of memory fragments.
In addition, Redis has two parameters to control the upper and lower limit of the CPU time proportion of cleaning operations in order to prevent the cleaning fragment from affecting the normal processing instructions of Redis.
- active-defrag-cycle-min 15: The proportion of CPU time used in the automatic cleaning process is not less than 15% to ensure that the cleaning can be effectively carried out.
- active-defrag-cycle-max 50: Indicates that the proportion of CPU time used in the automatic cleaning process cannot be greater than 50%. Once it exceeds, the cleaning will be stopped, so as to avoid a large number of memory copies blocking Redis from executing commands during cleaning.
7. Using 32-bit Redis
Using 32-bit redis, for each key, will use less memory, because 32-bit programs, pointers take up fewer bytes.
But the memory used by the entire instance of Redis of 32 will be limited to less than 4G. We can use cluster mode to form a cluster of multiple small memory nodes to save more data.
In addition, nodes with small memory fork generate rdb faster.
RDB and AOF files are 32-bit and 64-bit insensitive (including byte order), so you can use 64-bit Redis to restore 32-bit RDB backup files and vice versa.
Summarize
After finishing work, this set of magical skills came down, and I just wanted to say one word "Absolutely".
I hope this article can help you use a global perspective to solve the problem of memory optimization. I am "Code Brother", see you next time in Redis.
Teenagers who want to join the technical group stay, scan the notes "add to the group", and enter the exclusive technical reader group to brag together.
When you see the pretty boys here, write a comment to "Sanlian", pretty boy.
references
[1] https://redis.io/docs/reference/optimization/memory-optimization/
[2] "Redis Core Technology and Practice"


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。