

注:本篇文章推荐以 Colab NoteBook 的形式查看,并在浏览器中直接运行代码。
链接:https://colab.research.google...
导语
在数据很简单的时候,每个向量都代表一个数据点,我们轻松地存储到任意向量数据库,基于相似度去检索 embedding。但现实世界的数据总是很混乱的,多模态数据有着各式各样的层次嵌套结构。
无需担心,Jina 全家桶为你准备了解决方案!
作者介绍
Jina AI 机器学习工程师 Johannes Messner
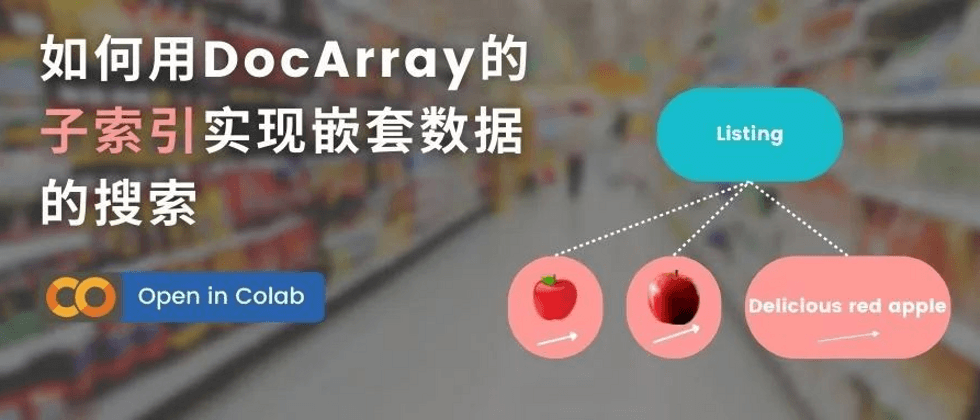
任务:商品搜索
在本笔记本中,我们的数据库包含在线商店的列表,每个列表都包含多个图像和一个商品描述。首先要让这些数据都是可搜索的,此外,还希望用户能使用不同的模态(文本、图像或两者同时)作为查询输入,来搜索到准确的商品。
为了解决这两个问题,我们只需要一个工具 DocArray
具体来说,我们将用到 3 个 DocArray 的功能:
1. Dataclass[1],对数据进行建模
2. Subindex[2],使数据点及数据点的嵌套信息可搜索
3. Document Stores[3],将我们的数据存储在磁盘上,并对它做检索
此外,我们也将使用 CLIP-as-service 编码文本和图像数据,生成对应 embedding。
数据索引
在索引数据之前,让我们看看我们的数据必须是什么样子,才能完成上述任务。
• 想要搜索图像,需要为每个图像提供 embedding
• 想要搜索描述,需要表示其描述的语义 embedding
• 想要搜索整个列表,每个列表都需要一个能代表整个列表的 embedding

将 embedding 存储在向量数据库中时,通常无法保留这种嵌套数据结构。但是,DocArray 子索引解决了这一难题。
Subindex
在 DocArray 中,数据以 Document 的形式存储,DocumentArray 是用于保存多个 Document 的列表。默认情况下,DocumentArray 是一个内存数据结构,但它也原生支持 Document Store,它是(向量)数据库后端,可用于在磁盘上持久化数据。
每个 DocumentArray 代表一个搜索索引,因此给定一个查询,我们可以找到其中包含的元素。一旦找到匹配的 Document,就可以将它们加载到内存中。
子索引使得这种模式能够扩展到嵌套数据。每个子索引代表父 DocumentArray 的一个嵌套层次,比如图片或描述文本。只要启用了子索引,就可以直接在该层执行搜索,就不需要像使用根级别索引一样,先将所有数据加载到内存中。
在底层,每个子索引创建一个单独的数据库索引,独立于其他子索引或根索引来存储相关数据。
引用链接
[1] Dataclass: https://docarray.jina.ai/fund...
[2] Subindex: https://docarray.jina.ai/fund...
[3] Document Stores: https://docarray.jina.ai/adva...







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。