
Focus on PHP, MySQL, Linux and front-end development, if you are interested, thank you for paying attention! ! ! The article has been included , and the main technologies include PHP, Redis, MySQL, JavaScript, HTML&CSS, Linux, Java, Golang, Linux and tool resources and other related theoretical knowledge, interview questions and practical content.
Article introduction
Hello everyone, I have been busy looking for a job for a while. The work has stabilized recently, so I summarized the Redis-related knowledge problems encountered during the interview process, hoping to be helpful for everyone's interview and study. This article focuses on sharing data types. Other content will be shared in subsequent chapters. You can also click the link above.
This series of interview questions will summarize related knowledge points such as understanding Redis, several major data types of Redis, common usage scenarios and solutions, Redis master-slave replication, Redis sentinel, and Redis cluster. It will not only end with text, but also with more pictures and texts, so that everyone can learn as much as possible.


At the same time, I also prepared a summary outline, which is more clear and clear than the text. Those in need can also reply Redis面试大纲 . At the same time, this series of questions will be continuously improved and updated. Let everyone learn more knowledge.

Get to know Redis
- REmote DIctionary Server (Redis) is a key-value storage system written by Salvatore Sanfilippo and is a cross-platform non-relational database.
- Redis is an open source written in ANSI C language, complies with the BSD protocol, supports network, can be based on memory, distributed, optional persistent key-value pair (Key-Value) storage database, and provides APIs in multiple languages.
What are the data types of Redis
- There are five basic data types, namely string, hash, list, ordered set (zset), and set (set). A Stream type was added after 5.0.
- Extras are GEO, HyperLogLog, BitMap.
What are the scenarios used by Redis
- Data cache (user information, number of items, number of articles read)
- News push (subscription to the site)
- Queue (peak clipping, decoupling, async)
- Leaderboard (points ranking)
- Social network (common friends, mutual stepping, pull down to refresh)
- Counter (product inventory, number of people online, article reading, likes)
- Cardinality calculation
- GEO calculation
What are the features of Redis
- Persistence
- Rich data types (string, list, hash, set, zset, publish-subscribe, etc.)
- High availability solution (sentry, cluster, master-slave)
- affairs
- rich client
- offer transaction
- News publish and subscribe
- Geo
- HyperLogLog
- affairs
- Distributed transaction lock
How Redis implements distributed locks
- Redis can use
setnx key value+expire key expire_timeto implement distributed locks. - Under normal circumstances, the above command is no problem. When Redis is abnormal, non-atomic operations are easy to occur.
- The non-atomic operation refers to the successful execution of the setnx command, but the expire is not successfully executed. At this time, the key becomes a key with no expiration time, which has been kept in Redis, resulting in the failure of other requests to be executed.
To solve this problem, you can use lua script implementation. The atomic operation of commands is implemented through lua.
Using the set command in Redis and adding parameters can also implement distributed locks.
set key vale nx ex|px ttl
<!-- tabs:start -->
Defined by an array
--- getLock key
local key = KEYS[1]
local requestId = KEYS[2]
local ttl = tonumber(KEYS[3])
local result = redis.call('setnx', key, requestId)
if result == 1 then
--PEXPIRE:以毫秒的形式指定过期时间
redis.call('pexpire', key, ttl)
else
result = -1;
-- 如果value相同,则认为是同一个线程的请求,则认为重入锁
local value = redis.call('get', key)
if (value == requestId) then
result = 1;
redis.call('pexpire', key, ttl)
end
end
-- 如果获取锁成功,则返回 1
return resultDefined by an array
-- releaseLock key
local key = KEYS[1]
local requestId = KEYS[2]
local value = redis.call('get', key)
if value == requestId then
redis.call('del', key);
return 1;
end
return -1<!-- tabs:end -->
Tips: If an expiration time is added to the first set of a key, and the expiration time is not added in the second operation, the key has no expiration time at this time (the expiration time is overwritten to never expire).
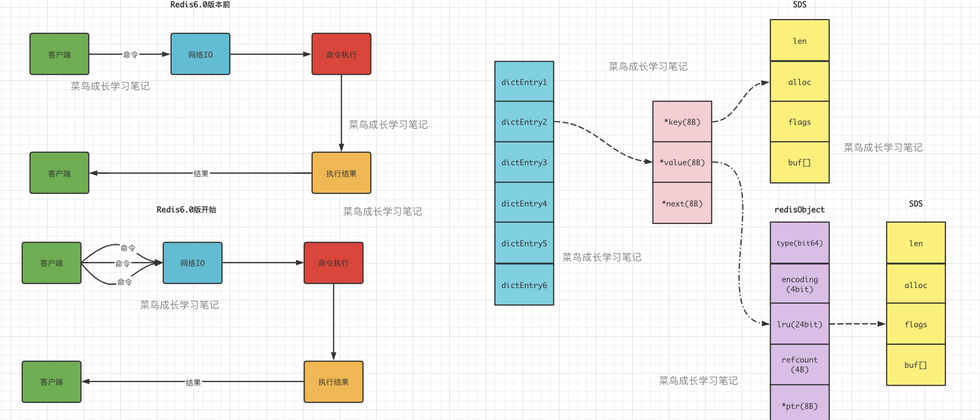
What are the underlying data structures of Redis
There are six main underlying data structures in Redis, which constitute five commonly used data types. Other data types, such as bitmap and hyperLogLog, are also implemented based on these five data types. The specific data structure diagram is as follows:

Talk about Redis' global Hash table
To achieve fast access from keys to values, Redis uses a hash table to store all key-value pairs. The structure diagram is as follows:

An important reason why Hash tables are so widely used is that theoretically, it can quickly query data with O(1) complexity. Hash table Through the calculation of the Hash function, the position of the data in the table can be located, and then the data can be operated, which makes the data operation very fast.
So how do we resolve hash collisions? There are two solutions to consider:
- The first solution is to use chained hashing. However, chained hashing can easily lead to a long Hash chain and reduce query efficiency.
- The second solution is that when the chain length of the chain hash reaches a certain length, we can use rehash. However, the overhead of executing rehash itself is relatively high.
What's wrong with del deleting a large number of keys
- Use the del command to delete a key or multiple keys, and its time complexity is O(N), where N represents the number of keys to be deleted.
- When deleting a single key, its time complexity is O(1).
- When deleting a key of a single list, set, sorted set or hash list type, the time complexity is O(M), where M represents the number of internal elements corresponding to the key.
Talk about the principle of global hash implementation of Redis
Talk about the implementation principle of Zset in skiplist and ziplist
What are the commands for Redis transactions
mutil: open the transaction; exec: commit the transaction; discard: roll back the transaction. watch: monitor the key; unwatch: cancel the monitor key.
Are transactions in Redis atomic
Strictly speaking, transactions in Redis do not satisfy the atomic operation of transactions. A transaction is atomic when no error occurs while the transaction is being queued for commands; a transaction is non-atomic when an error occurs while the transaction is being queued for commands.
How Redis resolves conflicts between transactions
- Use watch to monitor key changes. When the key changes, all operations in the transaction will be canceled.
- Use optimistic locking, implemented by version number.
- Using pessimistic locks, each time a transaction is opened, a lock is added, and the lock is released after the transaction execution ends.
Pessimistic Lock: Pessimistic Lock, as the name suggests, is very pessimistic. Every time I go to get the data, I think that others will modify it, so every time I get the data, it will be locked, so that when others get the data, it will block (blocks) until it gets the lock. Many such lock mechanisms are used in traditional relational databases, such as row locks, table locks, read locks, and write locks, all of which are locked before operations are performed.
Optimistic lock: Optimistic Lock, as the name suggests, is very optimistic. Every time I go to the data, I think that others will not modify it, so it will not be locked, but when modifying it, it will judge whether others have To update this data, mechanisms such as version numbers can be used. Optimistic locking is suitable for multi-read application types, which can improve throughput. Redis uses this check-and-set mechanism to implement transactions.
What is the use of watch in transaction
Before executing multi, execute watch key1 [key2 ...] to monitor one or more keys. If the values corresponding to these keys are changed by other commands before the exec command of the transaction, then all commands in the transaction will be interrupted, that is, the operation of the transaction will be canceled.
Three Features of Redis Transactions
- All commands in a transaction will be serialized and executed sequentially, and the transaction will not be interrupted by command requests sent by other clients during the execution process.
- Commands in the queue will not be actually executed until they are committed (exec), because no instructions will be actually executed until the transaction is committed.
- If a command fails to be executed in the transaction, the subsequent commands will still be executed without rollback. If one fails in the team formation stage, none of the following ones will succeed; if it succeeds in the team formation stage, if any command fails in the execution stage, this one will fail, and other commands will be executed normally, and there is no guarantee that all of them will succeed or fail. both fail.
How to use Redis to implement queue function
- You can use list to implement a normal queue, lpush to add to the beep column, and lpop to read data from the queue.
- Delay queues can be implemented by polling data periodically using zset.
- Multiple consumer queues can be implemented using publish-subscribe.
- Queues can be implemented using streams. (recommended to use this method to achieve).
How to implement asynchronous queue with Redis
- Generally, the list structure is used as a queue, rpush produces messages, and lpop consumes messages. When there is no message from lpop, sleep properly for a while and try again.
- If the other party asks if it is okay not to sleep? list also has an instruction called blpop, which blocks until a message arrives when there is no message.
- If the other party asks whether it can be produced once and consumed many times? Using the pub/sub topic subscriber pattern, a 1:N message queue can be implemented.
- If the other party asks what are the disadvantages of pub/sub? In the case of consumers offline, the produced messages will be lost . You can use the stream data type added by Redis6, or you can use professional message queues such as rabbitmq .
- If the other party asks how redis implements the delay queue? Use sortedset, take the timestamp as the score , and call zadd to generate the message with the message content as the key. The consumer uses the zrangebyscore command to obtain the data polling before N seconds for processing.
The difference between Stream and list, zset and publish-subscribe
- List can use lpush to add data to the queue, and lpop can read data from the queue. As a message queue, a list cannot implement multiple consumers of one message. If message processing fails, you need to roll back the message manually.
- When zset adds data, a score needs to be added, and the data can be sorted according to the score to realize the function of delaying the message queue. Whether or not the message is consumed requires additional processing.
- Publish and subscribe can implement multiple consumer functions, but publish and subscribe cannot achieve data persistence, which can easily lead to data loss. And opening a subscriber cannot get the previous data.
- Stream draws on the common MQ service, adding a message will generate a message ID, each message ID can correspond to multiple consumer groups, and each consumer group can correspond to multiple consumers. It can implement multiple consumer functions and support the ack mechanism at the same time to reduce data loss. It also supports data value persistence and master-slave replication.
How to design a website with daily, monthly and daily PV and UV
To implement such a function, if you only count a summary data, it is recommended to use the HyperLogLog data type. Redis HyperLogLog is an algorithm for cardinality statistics. The advantage of HyperLogLog is that when the number or volume of input elements is very large, the space required to calculate the cardinality is always fixed and small. In Redis, each HyperLogLog key only takes 12 KB of memory to calculate the cardinality of nearly 2^64 distinct elements. This is in stark contrast to a collection where more elements consume more memory when calculating cardinality.
How Redis implements the distance retrieval function
To achieve distance retrieval, you can use the GEO data type in Redis. GEO is mainly used to store geographic location information and operate the stored information. This function was added in Redis 3.2. But GEO is suitable for scenarios where the accuracy is not very high. Because GEO is calculated in memory, it has the characteristics of fast calculation speed.
What's wrong with list and publish-subscribe implementation of queues
- List can use lpush to add data to the queue, and lpop can read data from the queue. As a message queue, a list cannot implement multiple consumers of one message. If message processing fails, you need to roll back the message manually.
- Publish and subscribe can implement multiple consumer functions, but publish and subscribe cannot achieve data persistence, which can easily lead to data loss. And opening a subscriber cannot get the previous data.
How Redis implements the seckill function
- In the seckill scenario, oversold is a very serious problem. The conventional logic is to first query the inventory to reduce inventory. However, in the seckill scenario, there is no guarantee that other requests will read the unreduced inventory data in the process of reducing inventory.
- Since Redis is a single-threaded implementation, only one thread operates at the same time. Therefore, Redis can be used to reduce inventory in seconds.
- In the data type of Redis, you can use the lpush and decr commands to reduce inventory in seconds. This command is an atomic operation.
How Redis implements the user sign-in function
- Using Redis to implement user sign-in can be implemented using bitmap. The underlying data of the bitmap is stored as 1 or 0, which occupies a small amount of memory.
- The data type BitMap (bitmap) provided by Redis, each bit corresponds to two states of 0 and 1. Although it is still stored in String type internally, Redis provides some instructions for directly operating BitMap, which can be regarded as a bit array, and the subscript of the array is the offset.
- It has the advantages of low memory overhead, high efficiency and simple operation, which is very suitable for scenarios such as sign-in.
- The disadvantage is the limitation of bit calculation and bit representation of numerical values. If you want to use bits for business data records, don't care about the value of value.
How Redis Implements Delay Queues
- To implement a delayed queue with Redis, you can use the zset data type.
- When adding data, zset needs to add a score, use time as the score, and sort the data according to the score.
- Open the thread separately, and execute the data regularly according to the size of the score.
Redis implements a point ranking function
- Use Redis to achieve score ranking, you can use the zset data type.
- When adding data, zset needs to add a score, take the score as the score and the value as the user ID, and sort the data according to the score.
What is the maximum capacity of string type storage
A string can store up to 512M.





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。