
专注于PHP、MySQL、Linux和前端开发,感兴趣的感谢点个关注哟!!!文章已收录,主要包含的技术有PHP、Redis、MySQL、JavaScript、HTML&CSS、Linux、Java、Golang、Linux和工具资源等相关理论知识、面试题和实战内容。
文章导语
大家好,前段时间一直在忙找工作相关的事情。最近工作稳定了,于是把面试过程中遇到的Redis相关知识问题总结下来,希望能够对大家面试、学习有所帮助。本文重点分享数据类型,其他内容后续章节分享,也可以点击上方收录链接。
本系列面试题会从认识Redis、Redis几大数据类型、常见的使用场景和解决方案、Redis主从复制、Redis哨兵、Redis集群等相关知识点进行总结。不仅仅单纯的从文字方面终结,还会带有更多的图文方面,尽可能的让大家深入的学习。


同时我也准备了一份汇总大纲,相对文字来说更加的清晰、明了。需要的小伙伴也可以回复Redis面试大纲。同时该系列问题也会不断的完善、更新。让大家学习到更多的知识。

认识Redis
- REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库。
- Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API。
Redis的数据类型都有哪些
- 有五种基本数据类型,分别是string、hash、list、有序集合(zset)、集合(set)。在5.0之后增加了一种Stream类型。
- 额外的有GEO、HyperLogLog、BitMap。
Redis使用的场景有哪些
- 数据缓存(用户信息、商品数量、文章阅读数量)
- 消息推送(站点的订阅)
- 队列(削峰、解耦、异步)
- 排行榜(积分排行)
- 社交网络(共同好友、互踩、下拉刷新)
- 计数器(商品库存,站点在线人数、文章阅读、点赞)
- 基数计算
- GEO计算
Redis功能特点都有哪些
- 持久化
- 丰富的数据类型(string、list、hash、set、zset、发布订阅等)
- 高可用方案(哨兵、集群、主从)
- 事务
- 丰富的客户端
- 提供事务
- 消息发布订阅
- Geo
- HyperLogLog
- 事务
- 分布式事务锁
Redis如何实现分布式锁
- Redis可以使用
setnx key value+expire key expire_time来实现分布式锁。 - 正常情况下,上面的命令是没有问题的。当Redis出现异常的情况下,很容易出现非原子性操作。
- 非原子性操作指的的setnx命令执行成功,但是expire没有执行成功,此时key就成为了一个无过期时间的key,一直保留在Redis中,导致其他的请求就无法执行。
要解决该问题,可以使用lua脚本实现。通过lua实现命令的原子性操作。
在Redis中使用set命令,加参数也可以实现分布式锁。
set key vale nx ex|px ttl
<!-- tabs:start -->
通过数组定义
--- getLock key
local key = KEYS[1]
local requestId = KEYS[2]
local ttl = tonumber(KEYS[3])
local result = redis.call('setnx', key, requestId)
if result == 1 then
--PEXPIRE:以毫秒的形式指定过期时间
redis.call('pexpire', key, ttl)
else
result = -1;
-- 如果value相同,则认为是同一个线程的请求,则认为重入锁
local value = redis.call('get', key)
if (value == requestId) then
result = 1;
redis.call('pexpire', key, ttl)
end
end
-- 如果获取锁成功,则返回 1
return result通过数组定义
-- releaseLock key
local key = KEYS[1]
local requestId = KEYS[2]
local value = redis.call('get', key)
if value == requestId then
redis.call('del', key);
return 1;
end
return -1<!-- tabs:end -->
tips:如果对一个key第一次set添加了过期时间,第二次操作时没有添加过期时间,此时key是没有过期时间的(过期时间被覆盖为永久不过期)。
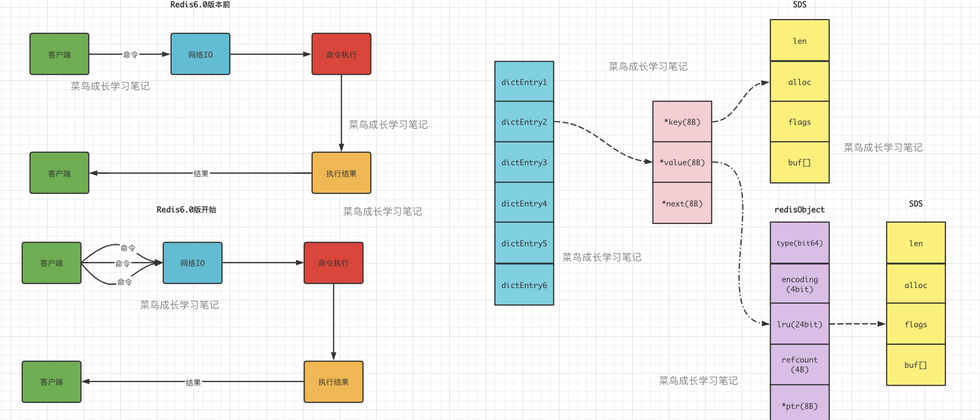
Redis底层数据结构有哪些
Redis底层数据结构主要有六种,这六种构成了五种常用的数据类型。其他的数据类型,例如bitmap、hyperLogLog也是基于这五大数据类型实现。具体的数据结构图如下:

说说Redis的全局Hash表
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。结构图如下:

Hash表应用如此广泛的一个重要原因,就是从理论上来说,它能以 O(1) 的复杂度快速查询数据。Hash 表通过Hash函数的计算,就能定位数据在表中的位置,紧接着可以对数据进行操作,这就使得数据操作非常快速。
那么我们该如何解决哈希冲突呢?可以考虑使用以下两种解决方案:
- 第一种方案,就是使用链式哈希。但是链式哈希容易导致Hash的链过长,查询效率降低。
- 第二种方案,就是当链式哈希的链长达到一定长度时,我们可以使用rehash。不过,执行rehash本身开销比较大。
del删除大量key有什么问题
- 使用del命令可以删除一个key或者多个key,其时间复杂度为O(N),这里的N表示删除的key数量。
- 删除单个key时,其时间复杂度为O(1)。
- 当删除单个列表、集合、有序集合或者哈希列表类型的key时,时间复杂度为O(M),这里的M表示key对应的内部元素个数。
说说Redis的全局hash实现原理
说说Zset在skiplist和ziplist实现原理
Redis事务都有哪些命令
mutil: 开启事务;exec: 提交事务;discard: 回滚事务。watch: 监听key; unwatch: 取消监听key。
Redis中的事务是否是原子性
严格来说,Redis中的事务并非满足事务的原子性操作。当事务在命令组队时没有发生错误,则事务是原子性;当事务在命令组队时发生错误,则事务是非原子性的。
Redis如何解决事务之间的冲突
- 使用watch监听key变化,当key发生变化,事务中的所有操作都会被取消。
- 使用乐观锁,通过版本号实现。
- 使用悲观锁,每次开启事务时,都添加一个锁,事务执行结束之后释放锁。
悲观锁:悲观锁(Pessimistic Lock),顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人拿到这个数据就会block(阻塞)直到它拿到锁。传统的关系型数据库里面 就用到了很多这种锁机制,比如行锁、表锁、读锁、写锁等,都是在做操作之前先上锁。
乐观锁:乐观锁(Optimistic Lock),顾名思义,就是很乐观,每次去那数据的时候都认为别人不会修改,所以 不会上锁,但是在修改的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机 制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。redis就是使用这种check-and-set机制实现 事务的。
事务中的watch有什么用
在执行multi之前,先执行watch key1 [key2 ...],可以监视一个或者多个key。若在事务的exec命令之前,这些key对应的值被其他命令所改动了,那么事务中所有命令都将被打断,即事务所有操作将被取消执行。
Redis事务的三大特性
- 事务中的所有命令都会序列化、按顺序地执行,事务在执行过程中,不会被其他客户端发送来的命令请求所打断。
- 队列中的命令没有提交(exec)之前,都不会实际被执行,因为事务提交前任何指令都不会被实际执行。
- 事务中如果有一条命令执行失败,后续的命令仍然会被执行,没有回滚。如果在组队阶段,有1个失败了,后面都不会成功;如果在组队阶段成功了,在执行阶段有那个命令失败 就这条失败,其他的命令则正常执行,不保证都成功或都失败。
如何使用Redis实现队列功能
- 可以使用list实现普通队列,lpush添加到嘟列,lpop从队列中读取数据。
- 可以使用zset定期轮询数据,实现延迟队列。
- 可以使用发布订阅实现多个消费者队列。
- 可以使用stream实现队列。(推荐使用该方式实现)。
如何用Redis实现异步队列
- 一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
- 如果对方追问可不可以不用sleep呢?list还有个指令叫blpop,在没有消息的时候,它会阻塞住直到消息到来。
- 如果对方追问能不能生产一次消费多次呢?使用pub/sub主题订阅者模式,可以实现1:N的消息队列。
- 如果对方追问pub/sub有什么缺点?在消费者下线的情况下,生产的消息会丢失,可以使用Redis6增加的stream数据类型,也可以使用专业的消息队列如rabbitmq等。
- 如果对方追问redis如何实现延时队列?使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用zrangebyscore指令获取N秒之前的数据轮询进行处理。
Stream与list、zset和发布订阅区别
- list可以使用lpush向队列中添加数据,lpop可以向队列中读取数据。list作为消息队列无法实现一个消息多个消费者。如果出现消息处理失败,需要手动回滚消息。
- zset在添加数据时,需要添加一个分值,可以根据该分值对数据进行排序,实现延迟消息队列的功能。消息是否消费需要额外的处理。
- 发布订阅可以实现多个消费者功能,但是发布订阅无法实现数据持久化,容易导致数据丢失。并且开启一个订阅者无法获取到之前的数据。
- stream借鉴了常用的MQ服务,添加一个消息就会产生一个消息ID,每一个消息ID下可以对应多个消费组,每一个消费组下可以对应多个消费者。可以实现多个消费者功能,同时支持ack机制,减少数据的丢失情况。也是支持数据值持久化和主从复制功能。
如何设计一个网站每日、每月和每天的PV和UV
实现这样的功能,如果只是统计一个汇总数据,推荐使用HyperLogLog数据类型。Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
Redis如何实现距离检索功能
实现距离检索,可以使用Redis中的GEO数据类型。GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增。但是GEO适合精度不是很高的场景。由于GEO是在内存中进行计算,具备计算速度快的特点。
list和发布订阅实现队列有什么问题
- list可以使用lpush向队列中添加数据,lpop可以向队列中读取数据。list作为消息队列无法实现一个消息多个消费者。如果出现消息处理失败,需要手动回滚消息。
- 发布订阅可以实现多个消费者功能,但是发布订阅无法实现数据持久化,容易导致数据丢失。并且开启一个订阅者无法获取到之前的数据。
Redis如何实现秒杀功能
- 在秒杀场景下,超卖是一个非常严重的问题。常规的逻辑是先查询库存在减少库存。但在秒杀场景中,无法保证减少库存的过程中有其他的请求读取了未减少的库存数据。
- 由于Redis是单线程的执行,同一时刻只有一个线程进行操作。因此可以使用Redis来实现秒杀减少库存。
- 在Redis的数据类型中,可以使用lpush,decr命令实现秒杀减少库存。该命令属于原子操作。
Redis如何实现用户签到功能
- 使用Redis实现用户签到可以使用bitmap实现。bitmap底层数据存储的是1否者0,占用内存小。
- Redis提供的数据类型BitMap(位图),每个bit位对应0和1两个状态。虽然内部还是采用String类型存储,但Redis提供了一些指令用于直接操作BitMap,可以把它看作一个bit数组,数组的下标就是偏移量。
- 它的优点是内存开销小,效率高且操作简单,很适合用于签到这类场景。
- 缺点在于位计算和位表示数值的局限。如果要用位来做业务数据记录,就不要在意value的值。
Redis如何实现延迟队列
- 使用Redis实现延迟队列,可以使用zset数据类型。
- zset在添加数据时,需要添加一个分值,将时间作为分值,根据该分值对数据进行排序。
- 单独开启线程,根据分值大小定期实行数据。
Redis实现一个积分排行功能
- 使用Redis实现积分排行,可以使用zset数据类型。
- zset在添加数据时,需要添加一个分值,将积分作为分值,值作为用户ID,根据该分值对数据进行排序。
字符串类型存储最大容量是多少
一个字符串最大可存储512M。




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。