
引言
本篇主要聚焦介绍风控决策引擎中决策树编排能力的构建。决策引擎是风控的大脑,而决策树的编排能力和体验是构建大脑的手段,如何构建高效、丝滑、稳定可靠的决策树编排能力,是对风控决策引擎的一大挑战,本篇文章和大家分享一下过往构建心得。
背景
任何系统在初期构建肯定不是往“一步到位”的方向去构建的,只是架构设计者尽量向后期可扩展、可维护的方向去搭建。好的底层设计,不怕产品后期疯狂迭代,且改动调整方便。糟糕的“填鸭式”代码,可能在当时为了尽快实现了功能,最终也会逐步发展成“屎山”,维护成本越来越高,要么跑路,要么只能另起炉灶。
MVP 小步迭代 1.0
此阶段目标:最小化可行产品(MVP);小布迭代,快速上线;一人分饰多角色。
风控部门成立初期,人员少,缺少 UED 和 前端,毕竟风控本身对视觉设计和前端不是刚需,主要是后端研发和策略运营对抗黑产即可。此时为了能尽快上线决策树功能,研发人员本着小步快跑的思想,直接在代码层资源目录 resource 下放置决策树静态配置文件(具体实现在下文分解),每次更改都需要发版。本身引擎的构建也是不完善的,需要添加的功能很多,一周发个几版也是家常便饭的事,此阶段大家也是能接受的。
“由静转动”2.0
此阶段目标:无需发版,生产快速变更;稳定性相关考虑。
随着部门队伍的逐步壮大,以及研发流程的规范,风控策略运营人员对于决策编排的响应时效和可视化能力需求越来越迫切,对于研发需要发版才能部署新的决策能力现状不满,黑产是高效的,但是研发发版又是需要编排和时间的,大家都要发版,且集中在一个发版周期,策略周一提出的修改,待到周三和大家的需求一起上,此时黑产早撸完跑路了。同时发版是有一定的风险的,出错了需要立即回滚,此时又延误了策略上线的时间。
基于上述,我们考虑到是时候开放生产环境直接可视化的编排决策树能力了,但是我们没有前端的同学,找别的部门借可能又不熟悉决策引擎这一套流程规范,沟通成本还高。那折中了一个方案:将静态配置文件挪到 DB 存储中去,且配置以文本字符的形式展现在前端即可,不需要复杂的前端设计,只需要简单的表单文本框填充即可满足研发修改决策流的诉求。这样让原本静态的配置“动”起来,直接在生产可配置,大大提高了生产部署的效率。
可视化决策流编排 3.0
此阶段目标:高效、稳定、智能的可视化决策树编排能力产品构建
接入风控的业务线越来越多,研发人员忙于风险场景对应的变量开发迭代,此时还需要分出一部分精力负责修改决策树。2.0 版本的决策树对运营来说就是一段字符串,不是一棵树,策略运营是没办法修改,也不敢修改,出错的风险太大。考虑到整个风控的体量和模式已经非常稳定了,也有一定的时间去考虑将决策编排做成一个可视化的产品交付策略人员使用了,毕竟决策树的调整本身也是策略的职责之一,需要将此沉淀为一个高可用的产品。
我们参照了业内 BPMN 工作流的前端样式设计规范,摘取了在风控决策树种需要用到的元素,构建了自己的决策引擎智能编排能力,可视化的拖拽节点,可完全交付给策略人员自行配置使用。
设计实现
技术选型
决策树,实际上就是一个变种 DAG(有向无环图),图中的节点在业务层面有不同的属性及功能。
那么如何存储这个 DAG 结构呢?用二维数组存储,是不能满足节点属性及边属性要求的,一是边界没法定义,可能这棵树很大,二是假设属性由关联表来实现,就会很割裂,没法直观看得到。
其实图可以用链表表示,链表的存储结构第一反应就是 JSON 或者 XML 来表示。可以想象, 如果用 JSON 来表示的话,层级嵌套关系会非常繁琐,毕竟 JSON 是用来序列化数据用的,展示方面,还是 XML 添加属性更为方便直观。


数据结构
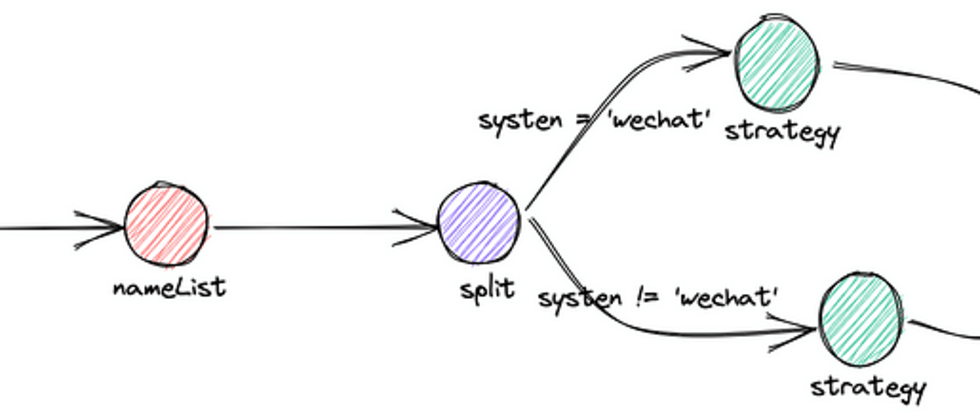
举例简易决策树如下
如上决策树用 XML 数据结构表示如下:

<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<flow id="test01" desc="建议决策流">
<!-- 开始节点 -->
<start id="start">
<!-- 链接到下一节点 -->
<link to="black01"/>
</start>
<!-- 名单节点 -->
<nameList id="black01" desc="黑名单">
<!-- 名单属性:名单类型:黑/白/灰;领域类型;适用范围 -->
<field key="type" val="black"/>
<field key="domain" val="10001,10002"/>
<field key="scope" val="deviceHash,phone,uid"/>
<link to="split01"/>
</nameList>
<!-- 分流节点 -->
<split id="split01" desc="是否为微信渠道">
<!-- 条件分支 -->
<condition order="0" desc="是" expr="system == 'wechat'" to="strategy01"/>
<condition order="10" desc="否" to="strategy02"/>
</split>
<!-- 策略节点 -->
<strategy id="strategy01" desc="微信专属策略">
<!-- 关联专属策略元数据 -->
<field key="strategyGuid" val="25F7C71A5F834F24A12C478CEE4CB9EB"/>
<link to="end"/>
</strategy>
<strategy id="strategy02" desc="非微信渠道策略">
<field key="strategyGuid" val="0FC8A95A4D6A4F169C77950BB4A98D80"/>
<link to="end"/>
</strategy>
<!-- 结束节点 -->
<end id="end" desc="结束"/>
</flow>上述数据结构非常直观的表示了当前需要绘制的决策树数据结构,相较于 JSON 的数据表现形式,XML 更灵活,扩展更方便,在横向和深度上可以有较好的平衡。
决策流解析
XML 是很成熟的技术实现了,市面上有很多解析 XML 的开源实现,如上数据结构我使用 common-digester解析,POM 中引入如下依赖即可:
<!-- https://mvnrepository.com/artifact/commons-digester/commons-digester -->
<dependency>
<groupId>commons-digester</groupId>
<artifactId>commons-digester</artifactId>
<version>1.8.1</version>
</dependency>实体关系如下:

XML 数据解析如下:
@Data
public class FlowEntity {
private String id;
private String desc;
private INode startNode;
private Map<String, INode> nodeMap = new HashMap<>();
}Digester digester = new Digester();
// parse flow node
digester.addObjectCreate("flow", FlowEntity.class);
digester.addSetProperties("flow");
// parse start node
digester.addObjectCreate("flow/start", StartNode.class);
digester.addSetProperties("flow/start");
// 在 FlowEntity 实现 addNode 方法,将当前节点录入
digester.addSetNext("flow/start", "addNode");
digester.addObjectCreate("flow/start/link", LinkBranch.class);
digester.addSetProperties("flow/start/link");
// 在 StartNode 实现 addLink 方法,将当前边录入
digester.addSetNext("flow/start/link", "addLink");
// parse split node
digester.addObjectCreate("flow/split", SplitNode.class);
digester.addSetProperties("flow/split");
digester.addSetNext("flow/split", "addNode");
digester.addObjectCreate("flow/split/condition", ConditionBranch.class);
digester.addSetProperties("flow/split/condition");
// 在 SplitNode 实现 addCondition 方法,将当前条件录入
digester.addSetNext("flow/split/condition", "addCondition");
// 省略...
InputStream inputStream = new ByteArrayInputStream(xmlResource.getBytes());
return (FlowEntity) digester.parse(inputStream);其中 addNode 逻辑为将所有节点都存储在一个 nodeMap 结构内,并且如果当前节点是开始节点,则赋值到startNode节点。
当 XML 解析完后,此时关联关系还没有建立,轮询每个节点后将节点与节点之间联系起来,并且校验节点是够存在,确保能关联成一个树。
public void assembleToNode(Map<String, INode> nodeMap) {
if (Objects.isNull(nodeMap)) {
return;
}
if (!nodeMap.containsKey(this.to)) {
throw new RuntimeException(String.format("%s to: %s can't find node from nodeMap", this.desc, this.to));
}
this.toNode = nodeMap.get(this.to);
}决策流执行
决策的执行只需要从 startNode 执行开始,递归执行,直到找到唯一的出口弹出即可。注意,策略接口是有输出决策结果的,如果是拒绝的话,此时可以直接中断流程执行,返回结果即可。
@Override
public void execute(FlowContext context) {
// 出口
if (this instanceof EndNode) {
return;
}
// 递归执行
this.execute(context);
}其中,SplitNode节点执行需要计算条件表达式,只要满足一个条件,即可确定往下走的节点,子类覆盖实现如下:
注:条件表达式我之前单独发了一篇文章,感兴趣的话欢迎关注,可在我的历史文章归档中查找,此处就不在展开说明了。
@Override
public void execute(FlowContext context) {
Validate.notEmpty(condition, "node id: {} desc: {} [condition] is empty", this.getId(), this.getDesc());
// 主动判断
Optional<ConditionBranch> target = condition.stream().filter(c -> c.evaluate(context)).findFirst();
// TODO: 考虑返回默认兜底分支节点
if (!target.isPresent()) {
throw new RuntimeException("node id: {} ConditionBranch expr execute find nothing, please check your expr condition");
}
target.get().getToNode().execute(context);
}StrategyNode 节点执行原理和 SplitNode 一致,只需要子类覆写实现方法,去执行相应的规则引擎,获取到决策结果,即可判断走向,此处就不在列出。
如上设计好了决策树的存储结构,再配合前端同学构建的基于 BPMN 流图的样式配合,定制风控需要的节点信息和表达,即可随时构建一棵理想的树(此处一句话带过,但在丝滑编排和辅助校验上,前端同学付出了很多,当然这不是本篇文章的重点)。

总结
本文分享了决策引擎中决策流图的思考及构建过程,从最小可用产品上线支撑业务发展到沉淀出可视化编排能力的工作区。当然,本文仅仅展示了通用决策流的思考构建过程,显示业务中还是会遇到各种挑战,比如对性能的要求、对成本的控制等等,挑战非常多,我将在后续一一分享出来,欢迎关注。
往期精彩
欢迎关注公众号:咕咕鸡技术专栏
个人技术博客:https://jifuwei.github.io/



**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。