
面试官:「你是怎么定位线上问题的?」
这个面试题我在两年社招的时候遇到过,前几天面试也遇到了。我觉得我每一次都答得中规中矩,今天来梳理复盘下,下次又被问到的时候希望可以答得更好。
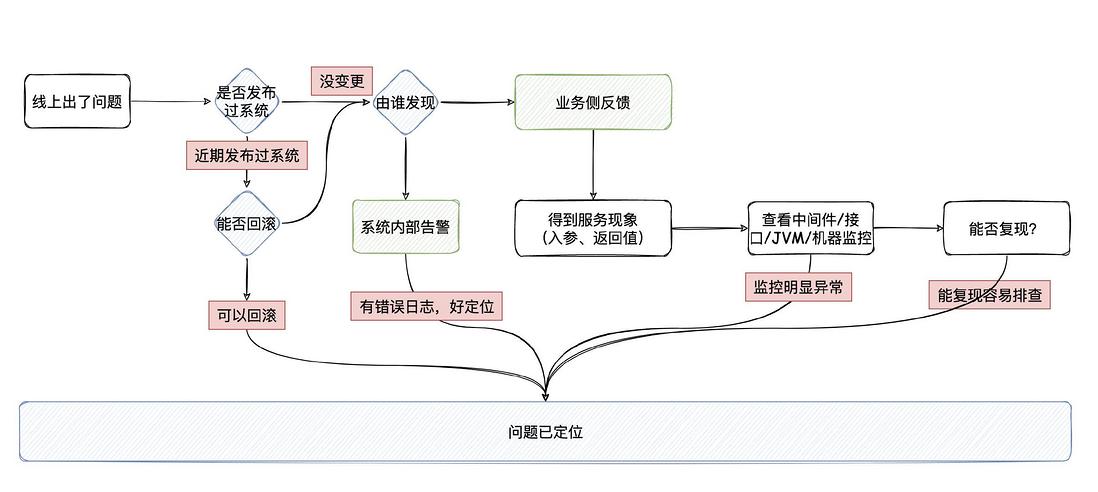
下一次我应该会按照这个思路去答:
1、如果线上出现了问题,我们更多的是希望由监控告警发现我们出了线上问题,而不是等到业务侧反馈。所以,我们需要对核心接口做好监控告警的功能。
2、如果是业务代码层面的监控报警,那我们应该是可以很快地定位出是哪儿的问题,毕竟告警逻辑都是我们写的嘛。如果是服务器资源/所依赖的中间件告警,那我们可能就要花点时间去排查啦。
3、不管怎么样,无论是系统告警还是是业务侧反馈系统或者接口出了问题。我们要想想在近期有没有发布过系统,如果近期发布过系统,判断能不能立马回滚到上一个版本,恢复系统平稳正常运行(在线上环境下,可用性是相当重要的)。回滚的时候要考虑接口有无依赖性,是否需要跟业务侧同步此次的回滚以及做相关的配合。
4、因为线上大多数的问题都来源于系统的变更,可能我们只是变更了很少的代码,但只要有一丝的逻辑没留意到,就真的很可能会导致出现问题,回滚很可能是最快能恢复线上正常运行的办法。
5、如果近期都没发布过系统,是系统告的警,那追踪下告警和报错日志,应该是可以很快地就能定位出问题。
6、如果不是系统告的警,是业务侧反馈出了问题,那这时候需要业务侧明确是哪个具体的功能/接口出了问题,有没有保留请求入参,有没有返回错误的信息,有何现象
7、知道了问题的现象之后,就需要根据经验排查可能是哪块出了问题了。我的经验一般是:先查存储侧有没有瓶颈(MySQL 的CPU有没有飙高,主从同步延迟是否很大,有没有慢SQL。Redis是不是内存满了,走了淘汰策略。搜索引擎有没有慢Query),把该服务所依赖的中间件的指标看一遍,这个过程中也要去看看服务接口的QPS/RT相关的监控。如果有某项指标不对劲,那顺着写入逻辑也应该很快能看出来
8、一般到这里,大多数的问题都能查出来。可能是逻辑本身的问题,可能是请求入参导致慢查询,可能是中间件的网络抖动,可能是突发或者异常请求的问题。
9、如果都不是,回归到应用和机器本身的监控:应用GC的表现、机器本身的网络/磁盘/内存/CPU 各种的指标有没有发现异常的情况。这里可能是需要运维侧一起配合看看有没有做过改动。
10、要是还定位不出来,看能不能复现,能复现都好说,肯定是能解决的。
11、要是不能复现,只能在怀疑的地方打上详细的日志再好好观察(问题定位不出来,很多时候就是日志不够详细,而日志在正常情况下也不应该打太多)
最后再推荐下我的开源项目,对线上消息推送是怎么实现而感兴趣的,可以看看:
austin消息推送平台项目源码Gitee链接:gitee.com/austin
austin消息推送平台项目源码GitHub链接:github.com/austin


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。