
如何 build NebulaGraph?如何为 NebulaGraph 内核做贡献?即便是新手也能快速上手,从本文作为切入点就够了。
NebulaGraph 的架构简介
为了方便对 NebulaGraph 尚未了解的读者也能快速直接从贡献代码为起点了解它,我把开发、贡献内核代码入手所需要的基本架构知识在这里以最小信息量的形式总结一下。作为前导知识,请资深的 NebulaGraph 玩家直接跳过这一章节。
服务、进程
NebulaGraph 的架构和 Google Spanner、TiDB 很相似,核心部分只有三种服务进程:Graph 服务、Meta 服务和 Storage 服务。它们之间彼此通过 TCP 之上的 Thrift RPC 协议进行通信。

计算层与存储层
NebulaGraph 是存储与计算分离的架构,Meta 服务和 Storage 服务共同组成了存储层,Graph 服务是内核提供的计算层。
这样的设计使得 NebulaGraph 的集群部署可以灵活按需分配计算、存储的资源。比如,在同一个集群中创建不同配置的两组 Graph 服务实例用来面向不同类型的业务。
同时,计算层解耦于存储层使得在 NebulaGraph 之上的构建不同的特定计算层成为可能。比如,NebulaGraph Algorithm、NebulaGraph Analytics 就是在 NebulaGraph 之上构建了异构的另一个计算层。任何人都可以按需定制专属计算层,从而满足统一图基础存储之上的复合、多样的计算需求。
Graph Service:nebula-graphd
Graph 服务是对外接收图库登录、图查询请求、集群管理操作、Schema 定义所直接连接的服务,它的进程名字叫 graphd,表示 nebula graph daemon。
Graph 服务的每一个进程是无状态的,这使得横向扩缩 Graph 服务的实例非常灵活、简单。
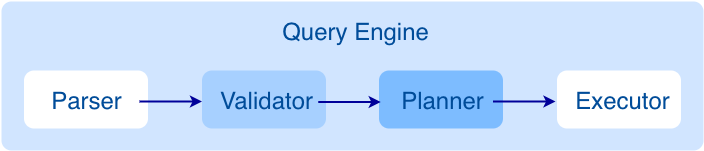
Graph 服务也叫 Query Engine,其内部和传统的数据库系统的设计非常相似,分为:解析、校验、计划、执行几部分。
Meta Service:nebula-metad
Meta 服务顾名思义负责元数据管理,进程名字叫 metad。这些元数据包括:
- 所有的图空间、Schema 定义
- 用户鉴权、授权信息
- 集群服务的发现与服务的分布
- 图空间中的数据分布
Meta 服务的进程可以单实例部署。在非单机部署的场景下,为了数据、服务的高 SLA ,以奇数个实例进行部署。通常来说 3 个 nebula-metad 就足够了,3 个 nebula-metad 通过 Raft 共识协议构成一个集群提供服务。

Storage Service:nebula-storaged
Storage 服务存储所有的图数据,进程名字叫 storaged。storaged 分布式地存储图数据,为 Graph 内部的图查询执行期提供底层的图语义存储接口,方便 Storage 客户端通过 Thrift RPC 协议面向涉及的 storaged 示例进行图语义的读写。
当 NebulaGraph 中图空间的副本数大于 1 的时候,每一个分区都会在不同 storaged 示例上有副本,副本之间则通过 Raft 协议协调同步与读写。

进程间通信、服务发现机制
在 NebulaGraph 中 graphd、metad、storaged 之间通过 Thrift 协议进行远程调用(RPC),下边给一些例子:
- graphd 会通过 metaclient 调用 metad:将自己报告为一个正在运行的服务,以便被发现;再为用户(使用 graphclient )登录进行 RPC 调用;当它处理 nGQL 查询时,获取图存储分布情况;
- graphd 会通过 storageclient 调用 storaged:当 graphd 处理 nGQL 时,先从 metad 获得所需的元信息,再进行图数据的读/写;
- storaged 会通过 metaclient调用 metad:将 storaged 报告为一个正在运行的服务,以便被发现。
当然,有状态的存储引擎内部也有集群同步的流量与通信。比如,storaged 与其他 storaged 有 Raft 连接;metad 与其他 metad 实例有 Raft 连接。
开发环境搭建
接下来,我们开始 NebulaGraph 的构建、开发环境的部分。
NebulaGraph 只支持在 GNU/Linux 分支中构建。目前来说,最方便的方式是在社区预先提供好了依赖的容器镜像的基础上在容器内部构建、调试 NebulaGraph 代码的更改和 Debug。
创建一个容器化的 NebulaGraph 集群
为了更方便地调试代码,我习惯提前创建一个 NebulaGraph Docker 环境。推荐使用官方的 Docker-Compose 方式部署,也可以使用我在官方 Docker-Compose 基础之上弄的一键部署工具:nebula-up。
下面以 nebula-up 为例:
在 Linux 开发服务器中执行 curl -fsSL nebula-up.siwei.io/install.sh | bash 就可以了。
代码获取
NebulaGraph 的代码仓库托管在 GitHub 之上,在联网的情况下直接克隆:
git clone git@github.com:vesoft-inc/nebula.git
cd nebula创建开发容器
有了 NebulaGraph 集群,我们可以借助 nebula-dev-docker 提供的开箱即用开发容器镜像,搭建开发环境:
export TAG=ubuntu2004
docker run -ti \
--network nebula-net \
--security-opt seccomp=unconfined \
-v "$PWD":/home/nebula \
-w /home/nebula \
--name nebula_dev \
vesoft/nebula-dev:$TAG \
bash其中,-v "$PWD" 表示当前的 NebulaGraph 代码本地的路径会被映射到开发容器内部的 /home/nebula,而启动的容器名字是 nebula_dev。
待这个容器启动后,会自动进入到这个容器的 bash shell 之中。如果我们输入 exit 退出容器,它会被关闭。如果我们想再次启动容器,只需要执行:
docker start nebula_dev之后的编译、Debug、测试工作都在 nebula_dev 容器内部进行。在容器是运行状态的情况下,可以随时新建一个容器内部的 bash shell 进程:
docker exec -ti nebula_dev bash为了保持编译环境是最新版,可以定期删除、拉取、重建这个开发容器,以保持环境与代码相匹配。
编译环境
在 nebula_dev 这个容器内部,我们可以进行代码编译。进入编译容器:
docker exec -ti nebula_dev bash用 CMake 准备 makefile。第一次构建时,为了节省时间、内存,我关闭了测试 -DENABLE_TESTING=OFF:
mkdir build && cd build
cmake -DCMAKE_CXX_COMPILER=$TOOLSET_CLANG_DIR/bin/g++ -DCMAKE_C_COMPILER=$TOOLSET_CLANG_DIR/bin/gcc -DENABLE_WERROR=OFF -DCMAKE_BUILD_TYPE=Debug -DENABLE_TESTING=OFF ..开始编译,根据服务器的空闲 CPU 个数和内存量力而行。比如,我在 72 核心的服务器上准备允许同时运行 64 个 job,则运行:
make -j64第一次构建的时间会慢一些,在 make 成功之后,我们也可以执行 make install 把二进制安装到像生产安装时候一样的路径:
root@1827b82e88bf:/home/nebula/build# make install
root@1827b82e88bf:/home/nebula/build# ls /usr/local/nebula/bin
db_dump db_upgrader meta_dump nebula-graphd nebula-metad nebula-storaged
root@1827b82e88bf:/home/nebula/build# ls /usr/local/nebula/
bin etc pids scripts share调试 NebulaGraph
以 graphd 调试为例。
安装依赖
安装一些后边会方便 Debug 额外用到的依赖:
# 装一个 ping,测试一下 nebula-up 安装的集群可以访问
apt update && apt install iputils-ping -y
# ping graphd 试试看
ping graphd -c 4
# 安装 gdb gdb-dashboard
apt install gdb -y
wget -P ~ https://git.io/.gdbinit
pip install pygments准备客户端
准备一个 NebulaGraph 的命令行客户端:
# 新开一个 nebula_dev 的 shell
docker exec -ti nebula_dev bash
# 下载 nebula-console 二进制文件,并赋予可执行权限,命名为 nebula-console 并安装到 /usr/bin/ 下
wget https://github.com/vesoft-inc/nebula-console/releases/download/v3.2.0/nebula-console-linux-amd64-v3.2.0
chmod +x nebula-console*
mv nebula-console* /usr/bin/nebula-console连接到前边我们 nebula-up 准备的集群之上,加载 basketballplayer 这个测试数据:
nebula-console -u root -p nebula --address=graphd --port=9669
:play basketballplayer;
exitgdb 运行 graphd
用 gdb 执行刚刚编译的 nebula-graphd 二进制,让它成为一个新的 graphd 服务,名字就叫 nebula_dev。
首先启动 gdb:
# 新开一个 nebula_dev 的 shell
docker exec -ti nebula_dev bash
cd /usr/local/nebula/
mkdir -p /home/nebula/build/log
gdb bin/nebula-graphd在 gdb 内部执行设置必要的参数,跟随 fork 的子进程:
set follow-fork-mode child设置待调试 graphd 的启动参数(配置):
meta_server_addrs填已经启动的集群的所有 metad 的地址;local_ip和ws_ip填本容器的域名,port是 graphd 监听端口;log_dir是输出日志的目录,v和minloglevel是日志的输出等级;
set args --flagfile=/usr/local/nebula/etc/nebula-graphd.conf.default \
--meta_server_addrs=metad0:9559,metad1:9559,metad2:9559 \
--port=9669 \
--local_ip=nebula_dev \
--ws_ip=nebula_dev \
--ws_http_port=19669 \
--log_dir=/home/nebula/build/log \
--v=4 \
--minloglevel=0如果我们想加断点在 src/common/function/FunctionManager.cpp 2783 行,可以再执行:
b /home/nebula/src/common/function/FunctionManager.cpp:2783配置前边安装的 gdb-dashboard,一个开源的 gdb 界面插件。
# 设定在 gdb 界面上展示 代码、历史、回调栈、变量、表达几个部分,详细参考 https://github.com/cyrus-and/gdb-dashboard
dashboard -layout source history stack variables expressions最后我们让进程通过 gdb 跑起来吧:
run之后,我们就可以在这个窗口/shell 会话下调试 graphd 程序了。
修改 NebulaGraph 代码
这里,我以 issue#3513 为例子,快速介绍一下代码修改的过程。
读代码
这个 issue 表达的内容是在有一小部分用户决定把 JSON 以 String 的形式存储在 NebulaGraph 中的属性里。因为这种方式比较罕见且不被推崇,NebulaGraph 没有直接支持对 JSON String 解析。
由于不是一个通用型需求,这个功能是希望热心的社区用户自己来实现并应用在他的业务场景中。但在该 issue 中,刚好有位新手贡献者在里边回复、求助如何开始参与这块的功能实现。借着这个契机,我去参与讨论看了一下这个功能可以实现成什么样子。最终讨论的结果是可以做成和 MySQL 中的 JSON_EXTRACT 函数那样,改为只接受 JSON String、无需处理输出路径参数。
一句话来说就是,为 NebulaGraph 引入一个解析 JSON String 为 Map 的函数。那么,如何实现这个功能呢?
在哪里修改
显然,引入新的函数,项目变更肯定有很多。所以,我们只需要找到之前增加新函数的 PR 就可以快速知道在哪些地方修改了。
一般情况下,可以自底向上地了解 NebulaGraph 整体的代码结构,再一点点找到函数处理的位置。这时候,除了代码本身,一些面向贡献者的文章可能会帮助大家事半功倍对整体有一个了解。NebulaGraph 官方也除了一个系列文章,大家做项目贡献前不妨阅读了解下,参见:延伸阅读 5。
具体的实操起来呢?我从 pr#4526 了解到所有函数入口都被统一管理在 src/common/function/FunctionManager.cpp 之中。通过搜索、理解当中某个函数的关键词之后,可以很容易理解一个函数实体的关键词、输入/输出数据类型、函数体处理逻辑的代码在哪里实现。
此外,在同一个根目录下,src/common/function/test/FunctionManagerTest.cpp 之中则是所有这些函数的单元测试代码。用同样的方式也可以知道新加的一个函数需要如何在里边实现基于 gtest 的单元测试。
开始改代码
在修改代码之前,确保在最新的 master 分支之上创建一个单独的分支。在这里的例子中,我把分支名字叫 fn_JSON_EXTRACT:
git checkout master
git pull
git checkout -b fn_JSON_EXTRACT通过 Google 了解与交叉验证 NebulaGraph 内部使用的 utils 库,知道应该用 folly::parseJson 把字符串读成 folly::dynamic。再 cast 成 NebulaGraph 内置的 Map() 类型。最后,借助于 Stack Overflow/GitHub Copilot,我终于完成了第一个版本的代码修改。
调试代码
我兴冲冲地改好了第一版的代码,信心满满地开始编译!实际上,因为我是 CPP 新手,即使在 Copilot 加持下,我的代码还是花了好几次修改才通过编译。
编译之后,我用 gdb 把修改了的 graphd 启动起来。用 console 发起 JSON_EXTRACT 的函数调用。先调通了期待中的效果,并试着跑几种异常的输入。在发现新问题、修改、编译、调试的几轮循环下让代码达到了期望的状态。
这时候,就该把代码提交到远端 GitHub 请项目的资深贡献者帮忙 review 啦!
提交 PR
PR(Pull Request)是 GitHub 中方便多人代码协作、代码审查中的一种方式。它通过把一个 repo 下的分支与这个审查协作的实例(PR)做映射,得到一个项目下唯一的 PR 号码之后,生成单独的网页。在这个网页下,我们可以做不同贡献者之间的交流和后续的代码更新。这个过程中,代码提交者们可以一直在这个分支上不断提交代码直到代码的状态被各方同意 approve,再合并 merge 到目的分支中。
这个过程可以分为:
- 创建 GitHub 上远程的个人开发分支;
- 基于分支创建目标项目仓库中的 PR;
- 在 PR 中协作、讨论、不断再次提交到开发分支直到多方达到合并、或者关闭的共识;
提交到个人远程分支
在这一步骤里,我们要把当前的本地提交的 commit 提交到自己的 GitHub 分叉之中。
commit 本地修改
首先,确认本地的修改是否都是期待中的:
# 先确定修改的文件
$ git status
# 再看看修改的内容
$ git diff再 commit,这时候是在本地仓库提交 commit:
# 添加所有当前目录(. 这个点表示当前目录)修改过的文件为待 commit
$ git add .
# 然后我们可以看一下状态,这些修改的文件状态已经不同了
$ git status
# 最后,提交在本地仓库,并用 -m 参数指定单行的 commit message
$ git commit -m "feat: introduce function JSON_EXTRACT"提交到自己远程的分支
在提交之前,要确保自己的 GitHub 账号之下确实存在 NebulaGraph 代码仓库的分叉 fork。比如,我的 GitHub 账号是 wey-gu,那么我对 https://github.com/vesoft-inc... 的分叉应该就是 https://github.com/wey-gu/nebula 。
如果还没有自己的分叉,可以直接在 https://github.com/vesoft-inc... 上点击右上角的 Fork,创建自己的分叉仓库。
当远程的个人分叉存在之后,我们可以把代码提交上去:
# 添加一个新的远程仓库叫 wey
git remote add wey git@github.com:wey-gu/nebula.git
# 提交 JSON_EXTRACT 分支到 wey 这个 remote 仓库
git push wey JSON_EXTRACT在个人远程分叉分支上创建 PR
这时候,我们访问这个远程分支:https://github.com/wey-gu/nebula/tree/fn_JSON_EXTRACT,就能找到 Open PR 的入口:

点击 Open pull request 按钮,进入到创建 PR 的界面了,这和在一般的论坛里提交一个帖子是很类似的:

提交之后,我们可以等待、或者邀请其他人来做代码的审查 review。往往,开源项目的贡献者们会从他们的各自角度给出代码修改、优化的建议。经过几轮的代码修改、讨论后,这时候代码会达到最佳的状态。
在这些审查者中,除了社区的贡献者(人类)之外,还有自动化的机器人。它们会在代码库中自动化地通过持续集成 CI 的方式运行自动化的审查工作,可能包括以下几种:
- CLA:Contributor License Agreement,贡献者许可协议。PR 作者在首次提交代码到项目时,所需签署的协议。因为代码将被提交到公共空间,这份协议的签署意味着作者同意代码被分享、复用、修改;
- lint:代码风格检查,这也是最常见的 CI 任务;
- test:各种层面的测试检查任务。
通常来说,所有自动化审查机器人执行的任务全都通过后,贡献的代码状态才能被认为是可合并的。不出意外,我首次提交的代码果然有测试的失败提示。

调试 CI 测试代码
NebulaGraph 里所有的 CI 测试代码都能在本地被触发。当然,它们都有被单独触发的方式。我们需要掌握如何单独触发某个测试,而不是在每次修改一个小的测试修复、提交到服务器,就等着 CI 做全量的运行,这样会浪费掉几十分钟。
CTest
本次 PR 提交中,我修改的函数代码同一层级下的单元测试 CTest 就有问题。问题发生的原因有多种,可能是测试代码本身、代码变更破坏了原来的测试用例、测试用例发现代码修改本身的问题。
我们要根据 CTest 失败的报错进行排查和代码修改。再编译代码,在本地运行一下这个失败的用例:
# 我们需要进入到我们的编译容器内部的 build 目录下
$ docker exec -ti nebula_dev bash
$ cd build
# 在 -DENABLE_TESTING=ON 之中编译,如果之前的编译 job 数下内存已经跑满了的话,这次可以把 job 数调小一点,因为开启测试会占用更多内存
$ cmake -DCMAKE_CXX_COMPILER=$TOOLSET_CLANG_DIR/bin/g++ -DCMAKE_C_COMPILER=$TOOLSET_CLANG_DIR/bin/gcc -DENABLE_WERROR=OFF -DCMAKE_BUILD_TYPE=Debug -DENABLE_TESTING=ON ..
$ make -j 48
# 可以看到编译成功了 CTest 的单元测试二进制可执行文件
# [100%] Linking CXX executable ../../../../bin/test/function_manager_test
# [100%] Built target function_manager_test
# 执行重新修改过的单元测试!
$ bin/test/function_manager_test
[==========] Running 11 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 11 tests from FunctionManagerTest
[ RUN ] FunctionManagerTest.testNull
[ OK ] FunctionManagerTest.testNull (0 ms)
[ RUN ] FunctionManagerTest.functionCall
W20221020 23:35:18.579897 28679 Map.cpp:77] JSON_EXTRACT nested layer 1: Map can be populated only by Bool, Double, Int, String value and null, now trying to parse from: object
[ OK ] FunctionManagerTest.functionCall (2 ms)
[ RUN ] FunctionManagerTest.time
[ OK ] FunctionManagerTest.time (0 ms)
[ RUN ] FunctionManagerTest.returnType
[ OK ] FunctionManagerTest.returnType (0 ms)
[ RUN ] FunctionManagerTest.SchemaRelated
[ OK ] FunctionManagerTest.SchemaRelated (0 ms)
[ RUN ] FunctionManagerTest.ScalarFunctionTest
[ OK ] FunctionManagerTest.ScalarFunctionTest (0 ms)
[ RUN ] FunctionManagerTest.ListFunctionTest
[ OK ] FunctionManagerTest.ListFunctionTest (0 ms)
[ RUN ] FunctionManagerTest.duplicateEdgesORVerticesInPath
[ OK ] FunctionManagerTest.duplicateEdgesORVerticesInPath (0 ms)
[ RUN ] FunctionManagerTest.ReversePath
[ OK ] FunctionManagerTest.ReversePath (0 ms)
[ RUN ] FunctionManagerTest.DataSetRowCol
[ OK ] FunctionManagerTest.DataSetRowCol (0 ms)
[ RUN ] FunctionManagerTest.PurityTest
[ OK ] FunctionManagerTest.PurityTest (0 ms)
[----------] 11 tests from FunctionManagerTest (5 ms total)
[----------] Global test environment tear-down
[==========] 11 tests from 1 test suite ran. (5 ms total)
[ PASSED ] 11 tests.成功!
将新的更改提交到远程分支上,在 PR 的网页中,我们可以看到 CI 已经在新的提交的触发下重新编译、执行了。过一会儿全部 pass,我开始兴高采烈地等待着 2 位以上的审查者帮忙批准代码,最后合并它!
但是,我收到了新的建议:

另一位贡献者请我添加 TCK 的测试用例。
TCK
TCK 的全称是 The Cypher Technology Compatibility Kit,它是 NebulaGraph 从 openCypher 社区继承演进而来的一套测试框架,并用 Python 做测试用例格式兼容的实现。
它的优雅在于,我们可以像写英语一样去描述我们想实现的端到端功能测试用例,像这样!
# tests/tck/features/function/json_extract.feature
Feature: json_extract Function
Background:
Test json_extract function
Scenario: Test Positive Cases
When executing query:
"""
YIELD JSON_EXTRACT('{"a": "foo", "b": 0.2, "c": true}') AS result;
"""
Then the result should be, in any order:
| result |
| {a: "foo", b: 0.2, c: true} |
When executing query:
"""
YIELD JSON_EXTRACT('{"a": 1, "b": {}, "c": {"d": true}}') AS result;
"""
Then the result should be, in any order:
| result |
| {a: 1, b: {}, c: {d: true}} |
When executing query:
"""
YIELD JSON_EXTRACT('{}') AS result;
"""
Then the result should be, in any order:
| result |
| {} |在添加了自己的一个新的 tck 测试用例文本文件之后,我们只需要在测试文件中临时增加标签,并在执行的时候指定标签,就可以单独执行新增的 tck 测试用例了:
# 还是在编译容器内部,进入到 tests 目录下
cd ../tests
# 安装 tck 测试所需依赖
python3 -m pip install -r requirements.txt
python3 -m pip install nebula3-python==3.1.0
# 运行一个单独为 tck 测试准备的集群
make CONTAINERIZED=true ENABLE_SSL=true CA_SIGNED=true up
# 给 tests/tck/features/function/json_extract.feature 以@开头第一行加上标签,比如 @wey
vi tests/tck/features/function/json_extract.feature
# 执行 pytest (包含 tck 用例),因为制定了 -m "wey",只有 tests/tck/features/function/json_extract.feature 会被执行
python3 -m pytest -m "wey"
# 关闭 pytest 所依赖的集群
make CONTAINERIZED=true ENABLE_SSL=true CA_SIGNED=true down再次邀请 review
待我们把需要的测试调通、再次提交 PR 并且 CI 用例全都通过之后,我们可以再次邀请之前帮助审查代码的同学做做最后的查看,如果一切都顺利,代码就会被合并了!

就这样,我的第一个 CPP PR 终于被合并成功,大家能看到我留在 NebulaGraph 中的代码了。
延伸阅读:
- 基于 BDD 理论的 NebulaGraph 集成测试框架重构,https://nebula-graph.com.cn/posts/bdd-testing-practice
- 如何向 NebulaGraph 增加一个测试用例,https://nebula-graph.com.cn/posts/bdd-testing-practice-add-test-case
- NebulaGraph 文档之架构介绍,https://docs.nebula-graph.com.cn/master/1.introduction/3.nebula-graph-architecture/1.architecture-overview/
- NebulaGraph 源码解读系列,https://www.nebula-graph.com.cn/posts/nebula-graph-source-code-reading-00
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。