
引言
如果决策引擎是风控的大脑,那么规则引擎则是大脑内的重要构成,其编排了各种对抗黑产的规则,是多年对抗黑产的专家经验的累计,本文将向你介绍规则引擎的构成及实现。
背景
什么是规则引擎?
规则引擎可以帮助企业将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务规则。这使得企业可以更灵活地管理和修改业务规则,而无需修改应用程序代码。
规则引擎可以接受数据输入,并根据业务规则解释数据,做出业务决策。这些业务决策可以是自动的,也可以是人工干预的。
规则引擎通常包含如下几个部分:
- 规则库:规则库包含了所有可用的规则。这些规则可以是预先定义好的,也可以是动态生成的。
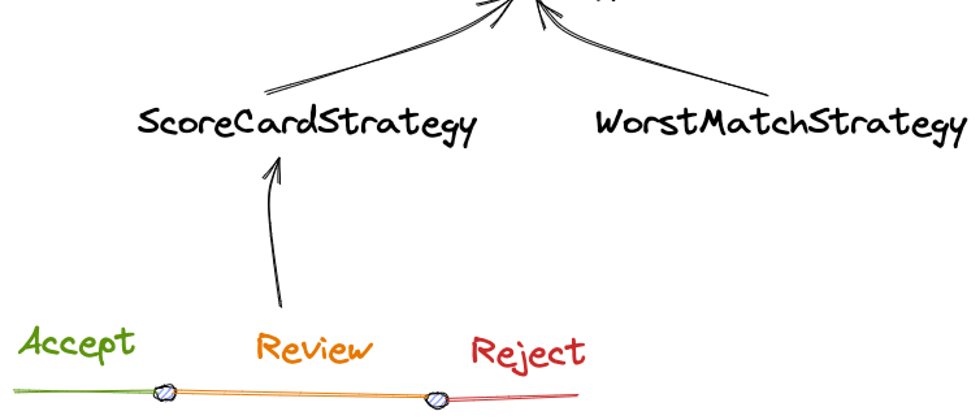
- 策略:用于管理规则,是对规则的条件组装,如评分卡策略、最坏匹配策略等。
- 规则执行引擎:负责规则的执行。读取规则库中所有可用规则,根据规则的条件执行规则。
为什么需要规则引擎?
规则引擎可以帮助企业更有效的管理和执行业务规则,提高决策的质量、效率和可靠性。
特点如下:
- 将业务决策从代码中剥离出来:运营人员可以更灵活有效的管理和修改业务规则,而无需修改业务代码,节省对抗时间
- 提高决策质量:规则引擎按照业务规则自动做出决策,无需依赖人为干预
- 提效:规则配置好后,可永久自动执行,减少人力消耗
- 稳定性:减少发版,减少测试,减少人为错误
设计实现
技术选型
在选择规则引擎时,需要考虑如下几点:
- 业务需求:应该根据企业的业务需求来选择规则引擎。如果企业需要快速执行大量规则,则应选择性能较高的规则引擎。
- 技术平台:选择与企业现有技术平台相兼容的规则引擎。如果企业使用的是 Java 技术平台,则应选择支持 Java 的规则引擎。
- 成本:考虑规则引擎的购买成本、实施成本和运行成本。是否开源也是很多技术团队的选择因素。
- 可维护性:选择易于维护的规则引擎,在需要时能够快速修改和更新规则。
- 市场占有率:选择市场占有率较高的规则引擎,在需要时能够获得较好的技术支持和培训。
- 技术支持:选择提供较好技术支持的规则引擎,以便在使用过程中能够得到及时的帮助。
当然,如果人力足够,可以考虑自己实现规则引擎亦可,自实现版本的规则引擎肯定灵活性更高,但是在性能和稳定性上需要较长时间的验证和考验。
如下是市场上热门的开源规则引擎:
| 规则引擎 | 简介 |
|---|---|
| JBoss Drools | JBoss Drools 是一款开源的规则引擎,支持 Java 和其他语言。 |
| OpenRules | OpenRules 是一款开源的规则引擎,支持 Java 和其他语言。 |
| Hippo Rules Engine | Hippo Rules Engine 是一款开源的规则引擎,支持 Java 和其他语言 |
| Apache Flink | Apache Flink 是一款开源的流处理框架,也可以用作规则引擎 |
| Easy Rules | Easy Rules 是一个基于 Java 的开源规则引擎框架,它提供了简单易用的 API,使得开发人员可以轻松地使用规则引擎。 |
| 基于 Groovy 实现规则引擎 | Groovy 是一种动态语言,可以运行在 Java 平台上。由于 Groovy 的语法简单,因此可以通过使用 Groovy 来实现规则引擎。 |
规则引擎术语
- 规则(Rule):规则是描述业务决策的规则或条件的语句。规则通常由两部分组成:条件和动作。条件是描述规则被触发的判断,动作是描述规则执行的操作。
- 事实(Fact):事实是描述业务场景的数据。事实可以是一个单独的数据项,也可以是一组数据。规则引擎会根据事实来触发规则。
- 决策表:决策表是一种以表格形式表示规则的数据结构。决策表通常由多个条件列和一个结果列组成。当条件列的值都满足时,决策表就会触发结果列的规则。
- 规则集合:规则集合是一种由规则组成的数据结构。规则集合通常以树形结构存储,每个规则都有一个条件和一个动作。当条件满足时,规则集合就会执行规则的动作。
规则配置解析
规则引擎最终是需要交付给运营人员去配置使用的,所以必须能满足灵活的配置编排,且易懂,才能最大发挥它的威力。
规则配置
说明:

- 触发条件:任意一个、满足所有、自定义。其中自定义最灵活,用户可以使用条件表达式配置任意想要的触发与或条件
- 变量(指标):左值,指标是输入数据衍生、或查询、或计算所得的值
- 比较符:等于、不等于、包含、属于、大于、小于、空 等等
- 阈值:右值,与指标计算所得值相比较,如果比较符关系成立,则认为命中当前规则
- 默认值:当指标执行出错或者超时,默认返回的值
策略配置
说明:

- 评分卡模式:依据每条规则命中所得分数之和,判定是否命中相应分数段的决策
- 最坏匹配:只要有一条规则命中,则立即拒绝
- 阈值:如果是评分卡模式,需要设置三个段位并且指定阈值
性能调优
决策引擎每天承载企业业务全部的风险决策,峰值 QPS 基本过万,但是风控的决策耗时需要足够的短,在不影响业务的情况下,尽可能快的返回决策结果,这是一大挑战。
从以往的调优经验来看,可以从以下几点来优化规则引擎:
- 并行执行规则:一次决策流中可能包含 N 个规则节点,每个规则节点包含 M 个规则,充分利用多核 CPU 优势,发挥最大威力,但同时需要考虑多线程数据安全问题
- 预加载指标:规则执行都是在内存中的,但是所需要的指标值往往都是需要调用外部系统得到的,一是网络开销,二是指标计算开销。可以在执行规则集之前,全部预加载一次指标再缓存,这样执行时直接从内存取值就会快很多。但是需要注意成本问题(如付费指标,存储成本,架构复杂度等),废调用问题(前置规则已拒绝)等等
- 规则加载预编译:规则首次加载往往比较耗时,此时最好能
warm up一下,这样在流量进来后,即可立即执行,但是使用预编译可能会增加系统的启动开销时间,需要做好相应的平衡工作 - 规则执行优化:运营配置规则时可能不会考虑规则执行顺序问题,但是程序在执行的时候可以智能编排一下,通过加入
与或及顺序关系,尽可能的把大耗时和大成本的指标放在最后面执行,优先执行内存指标,万一命中则直接断言,后续指标则不会再执行,节省了时间。要做到这一点,需要对指标进行较为详细的归类及元数据管理,需要全域的数据配合,对风控这种需要大数据的接口来说是一大挑战。
总结
规则引擎在风控整体架构内的重要性毋庸置疑,它的稳定性直接关系到风控决策的性能、数据质量。同时,对运营来说,好的决策引擎是足够灵活,足够智能,满足规则数据编排需求,且能立即生效上线,这是保障他们对抗黑产的前提,希望本文对构建高效的规则引擎又较好的启发。
往期精彩
●性能优化必备——火焰图
●我是怎么入行做风控的
●Flink 在风控场景实时特征落地实战
欢迎关注公众号:咕咕鸡技术专栏
个人技术博客:https://jifuwei.github.io/






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。