
判断数组的方式有哪些
- 通过Object.prototype.toString.call()做判断
Object.prototype.toString.call(obj).slice(8,-1) === 'Array';
- 通过原型链做判断
obj.__proto__ === Array.prototype;
- 通过ES6的Array.isArray()做判断
Array.isArrray(obj);
- 通过instanceof做判断
obj instanceof Array
- 通过Array.prototype.isPrototypeOf
Array.prototype.isPrototypeOf(obj)
JS 整数是怎么表示的?
- 通过 Number 类型来表示,遵循 IEEE754 标准,通过 64 位来表示一个数字,(1 + 11 + 52),最大安全数字是 Math.pow(2, 53) - 1,对于 16 位十进制。(符号位 + 指数位 + 小数部分有效位)
实现 LazyMan
题目描述:
实现一个LazyMan,可以按照以下方式调用:
LazyMan(“Hank”)输出:
Hi! This is Hank!
LazyMan(“Hank”).sleep(10).eat(“dinner”)输出
Hi! This is Hank!
//等待10秒..
Wake up after 10
Eat dinner~
LazyMan(“Hank”).eat(“dinner”).eat(“supper”)输出
Hi This is Hank!
Eat dinner~
Eat supper~
LazyMan(“Hank”).eat(“supper”).sleepFirst(5)输出
//等待5秒
Wake up after 5
Hi This is Hank!
Eat supper
实现代码如下:
class _LazyMan {
constructor(name) {
this.tasks = [];
const task = () => {
console.log(`Hi! This is ${name}`);
this.next();
};
this.tasks.push(task);
setTimeout(() => {
// 把 this.next() 放到调用栈清空之后执行
this.next();
}, 0);
}
next() {
const task = this.tasks.shift(); // 取第一个任务执行
task && task();
}
sleep(time) {
this._sleepWrapper(time, false);
return this; // 链式调用
}
sleepFirst(time) {
this._sleepWrapper(time, true);
return this;
}
_sleepWrapper(time, first) {
const task = () => {
setTimeout(() => {
console.log(`Wake up after ${time}`);
this.next();
}, time * 1000);
};
if (first) {
this.tasks.unshift(task); // 放到任务队列顶部
} else {
this.tasks.push(task); // 放到任务队列尾部
}
}
eat(name) {
const task = () => {
console.log(`Eat ${name}`);
this.next();
};
this.tasks.push(task);
return this;
}
}
function LazyMan(name) {
return new _LazyMan(name);
}
手写发布订阅
class EventListener {
listeners = {};
on(name, fn) {
(this.listeners[name] || (this.listeners[name] = [])).push(fn)
}
once(name, fn) {
let tem = (...args) => {
this.removeListener(name, fn)
fn(...args)
}
fn.fn = tem
this.on(name, tem)
}
removeListener(name, fn) {
if (this.listeners[name]) {
this.listeners[name] = this.listeners[name].filter(listener => (listener != fn && listener != fn.fn))
}
}
removeAllListeners(name) {
if (name && this.listeners[name]) delete this.listeners[name]
this.listeners = {}
}
emit(name, ...args) {
if (this.listeners[name]) {
this.listeners[name].forEach(fn => fn.call(this, ...args))
}
}
}异步任务调度器
描述:实现一个带并发限制的异步调度器 Scheduler,保证同时运行的任务最多有 limit 个。
实现:
class Scheduler {
queue = []; // 用队列保存正在执行的任务
runCount = 0; // 计数正在执行的任务个数
constructor(limit) {
this.maxCount = limit; // 允许并发的最大个数
}
add(time, data){
const promiseCreator = () => {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(data);
resolve();
}, time);
});
}
this.queue.push(promiseCreator);
// 每次添加的时候都会尝试去执行任务
this.request();
}
request() {
// 队列中还有任务才会被执行
if(this.queue.length && this.runCount < this.maxCount) {
this.runCount++;
// 执行先加入队列的函数
this.queue.shift()().then(() => {
this.runCount--;
// 尝试进行下一次任务
this.request();
});
}
}
}
// 测试
const scheduler = new Scheduler(2);
const addTask = (time, data) => {
scheduler.add(time, data);
}
addTask(1000, '1');
addTask(500, '2');
addTask(300, '3');
addTask(400, '4');
// 输出结果 2 3 1 4
首屏和白屏时间如何计算
首屏时间的计算,可以由 Native WebView 提供的类似 onload 的方法实现,在 ios 下对应的是 webViewDidFinishLoad,在 android 下对应的是onPageFinished事件。
白屏的定义有多种。可以认为“没有任何内容”是白屏,可以认为“网络或服务异常”是白屏,可以认为“数据加载中”是白屏,可以认为“图片加载不出来”是白屏。场景不同,白屏的计算方式就不相同。
方法1:当页面的元素数小于x时,则认为页面白屏。比如“没有任何内容”,可以获取页面的DOM节点数,判断DOM节点数少于某个阈值X,则认为白屏。 方法2:当页面出现业务定义的错误码时,则认为是白屏。比如“网络或服务异常”。 方法3:当页面出现业务定义的特征值时,则认为是白屏。比如“数据加载中”。
参考 前端进阶面试题详细解答
列表转成树形结构
题目描述:
[
{
id: 1,
text: '节点1',
parentId: 0 //这里用0表示为顶级节点
},
{
id: 2,
text: '节点1_1',
parentId: 1 //通过这个字段来确定子父级
}
...
]
转成
[
{
id: 1,
text: '节点1',
parentId: 0,
children: [
{
id:2,
text: '节点1_1',
parentId:1
}
]
}
]
实现代码如下:
function listToTree(data) {
let temp = {};
let treeData = [];
for (let i = 0; i < data.length; i++) {
temp[data[i].id] = data[i];
}
for (let i in temp) {
if (+temp[i].parentId != 0) {
if (!temp[temp[i].parentId].children) {
temp[temp[i].parentId].children = [];
}
temp[temp[i].parentId].children.push(temp[i]);
} else {
treeData.push(temp[i]);
}
}
return treeData;
}
发布订阅模式(事件总线)
描述:实现一个发布订阅模式,拥有 on, emit, once, off 方法
class EventEmitter {
constructor() {
// 包含所有监听器函数的容器对象
// 内部结构: {msg1: [listener1, listener2], msg2: [listener3]}
this.cache = {};
}
// 实现订阅
on(name, callback) {
if(this.cache[name]) {
this.cache[name].push(callback);
}
else {
this.cache[name] = [callback];
}
}
// 删除订阅
off(name, callback) {
if(this.cache[name]) {
this.cache[name] = this.cache[name].filter(item => item !== callback);
}
if(this.cache[name].length === 0) delete this.cache[name];
}
// 只执行一次订阅事件
once(name, callback) {
callback();
this.off(name, callback);
}
// 触发事件
emit(name, ...data) {
if(this.cache[name]) {
// 创建副本,如果回调函数内继续注册相同事件,会造成死循环
let tasks = this.cache[name].slice();
for(let fn of tasks) {
fn(...data);
}
}
}
}
其他值到字符串的转换规则?
- Null 和 Undefined 类型 ,null 转换为 "null",undefined 转换为 "undefined",
- Boolean 类型,true 转换为 "true",false 转换为 "false"。
- Number 类型的值直接转换,不过那些极小和极大的数字会使用指数形式。
- Symbol 类型的值直接转换,但是只允许显式强制类型转换,使用隐式强制类型转换会产生错误。
- 对普通对象来说,除非自行定义 toString() 方法,否则会调用 toString()(Object.prototype.toString())来返回内部属性 [[Class]] 的值,如"[object Object]"。如果对象有自己的 toString() 方法,字符串化时就会调用该方法并使用其返回值。
HTTP状态码
- 1xx 信息性状态码 websocket upgrade
2xx 成功状态码
- 200 服务器已成功处理了请求
- 204(没有响应体)
- 206(范围请求 暂停继续下载)
3xx 重定向状态码
- 301(永久) :请求的页面已永久跳转到新的url
- 302(临时) :允许各种各样的重定向,一般情况下都会实现为到
GET的重定向,但是不能确保POST会重定向为POST - 303 只允许任意请求到
GET的重定向 - 304 未修改:自从上次请求后,请求的网页未修改过
- 307:
307和302一样,除了不允许POST到GET的重定向
4xx 客户端错误状态码
- 400 客户端参数错误
- 401 没有登录
- 403 登录了没权限 比如管理系统
- 404 页面不存在
- 405 禁用请求中指定的方法
5xx 服务端错误状态码
- 500 服务器错误:服务器内部错误,无法完成请求
- 502 错误网关:服务器作为网关或代理出现错误
- 503 服务不可用:服务器目前无法使用
- 504 网关超时:网关或代理服务器,未及时获取请求
大数相加
题目描述:实现一个add方法完成两个大数相加
let a = "9007199254740991";
let b = "1234567899999999999";
function add(a ,b){
//...
}
实现代码如下:
function add(a ,b){
//取两个数字的最大长度
let maxLength = Math.max(a.length, b.length);
//用0去补齐长度
a = a.padStart(maxLength , 0);//"0009007199254740991"
b = b.padStart(maxLength , 0);//"1234567899999999999"
//定义加法过程中需要用到的变量
let t = 0;
let f = 0; //"进位"
let sum = "";
for(let i=maxLength-1 ; i>=0 ; i--){
t = parseInt(a[i]) + parseInt(b[i]) + f;
f = Math.floor(t/10);
sum = t%10 + sum;
}
if(f!==0){
sum = '' + f + sum;
}
return sum;
}
对Service Worker的理解
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用 Service Worker的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。
Service Worker 实现缓存功能一般分为三个步骤:首先需要先注册 Service Worker,然后监听到 install 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。以下是这个步骤的实现:
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register('sw.js')
.then(function(registration) {
console.log('service worker 注册成功')
})
.catch(function(err) {
console.log('servcie worker 注册失败')
})
}
// sw.js
// 监听 `install` 事件,回调中缓存所需文件
self.addEventListener('install', e => {
e.waitUntil(
caches.open('my-cache').then(function(cache) {
return cache.addAll(['./index.html', './index.js'])
})
)
})
// 拦截所有请求事件
// 如果缓存中已经有请求的数据就直接用缓存,否则去请求数据
self.addEventListener('fetch', e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response
}
console.log('fetch source')
})
)
})
打开页面,可以在开发者工具中的 Application 看到 Service Worker 已经启动了: 在 Cache 中也可以发现所需的文件已被缓存:
如何避免React生命周期中的坑
16.3版本
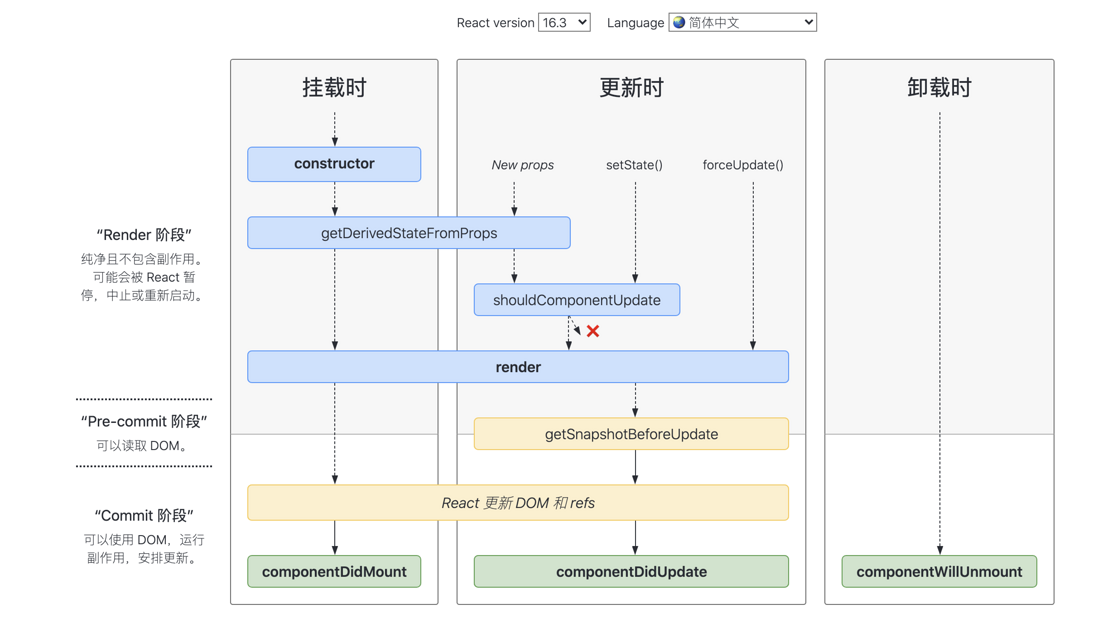
>=16.4版本

在线查看 :https://projects.wojtekmaj.pl/react-lifecycle-methods-diagram(opens new window)
- 避免生命周期中的坑需要做好两件事:不在恰当的时候调用了不该调用的代码;在需要调用时,不要忘了调用。
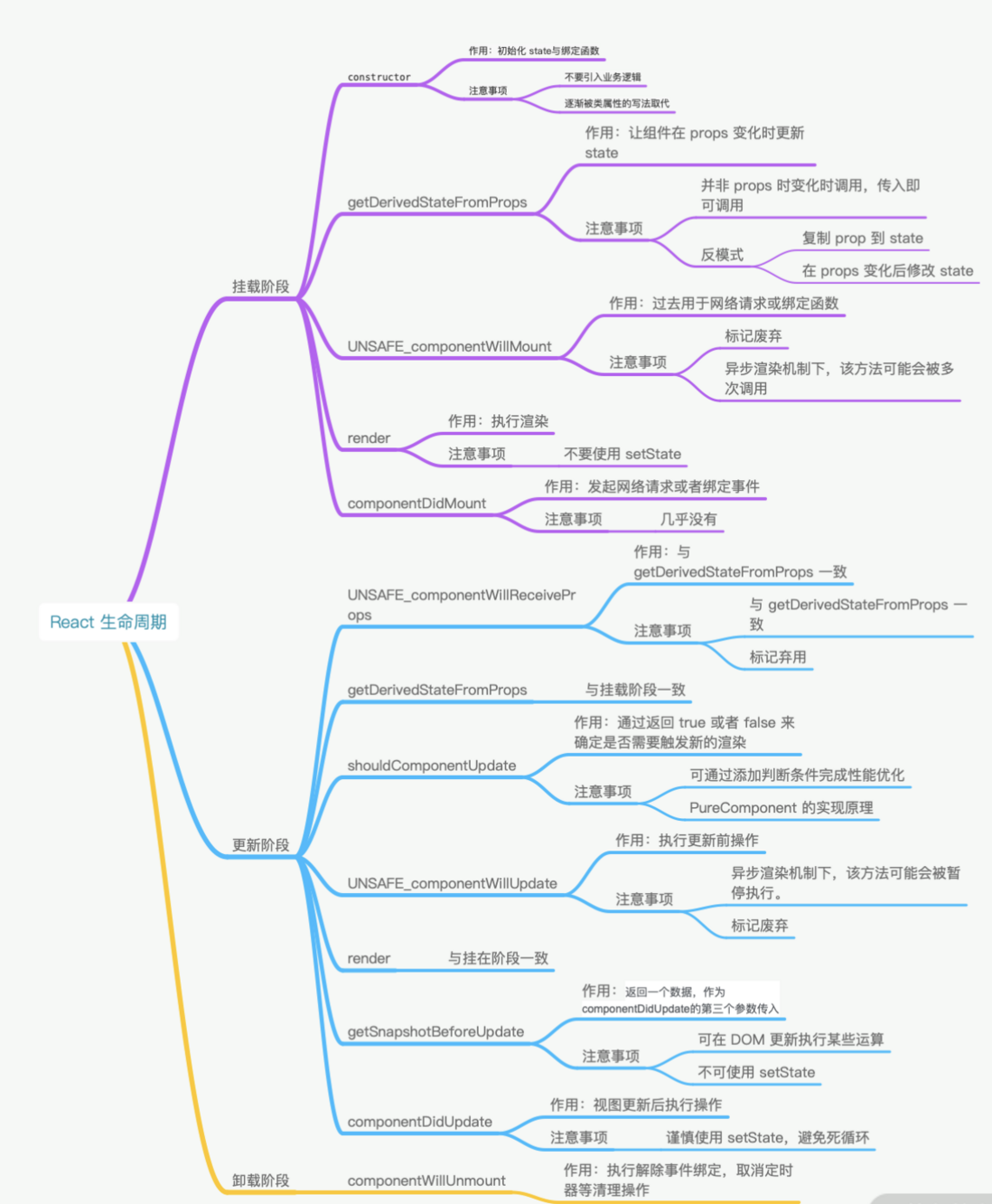
那么主要有这么 7 种情况容易造成生命周期的坑
getDerivedStateFromProps容易编写反模式代码,使受控组件与非受控组件区分模糊componentWillMount在 React 中已被标记弃用,不推荐使用,主要原因是新的异步渲染架构会导致它被多次调用。所以网络请求及事件绑定代码应移至componentDidMount中。componentWillReceiveProps同样被标记弃用,被getDerivedStateFromProps所取代,主要原因是性能问题shouldComponentUpdate通过返回true或者false来确定是否需要触发新的渲染。主要用于性能优化componentWillUpdate同样是由于新的异步渲染机制,而被标记废弃,不推荐使用,原先的逻辑可结合getSnapshotBeforeUpdate与componentDidUpdate改造使用。- 如果在
componentWillUnmount函数中忘记解除事件绑定,取消定时器等清理操作,容易引发 bug - 如果没有添加错误边界处理,当渲染发生异常时,用户将会看到一个无法操作的白屏,所以一定要添加
“React 的请求应该放在哪里,为什么?” 这也是经常会被追问的问题。你可以这样回答。
对于异步请求,应该放在 componentDidMount 中去操作。从时间顺序来看,除了 componentDidMount 还可以有以下选择:
- constructor:可以放,但从设计上而言不推荐。constructor 主要用于初始化 state 与函数绑定,并不承载业务逻辑。而且随着类属性的流行,constructor 已经很少使用了
- componentWillMount:已被标记废弃,在新的异步渲染架构下会触发多次渲染,容易引发 Bug,不利于未来 React 升级后的代码维护。
- 所以React 的请求放在
componentDidMount 里是最好的选择。
透过现象看本质:React 16 缘何两次求变?
Fiber 架构简析
Fiber 是 React 16 对 React 核心算法的一次重写。你只需要 get 到这一个点:Fiber 会使原本同步的渲染过程变成异步的。在 React 16 之前,每当我们触发一次组件的更新,React 都会构建一棵新的虚拟 DOM 树,通过与上一次的虚拟 DOM 树进行 diff,实现对 DOM 的定向更新。这个过程,是一个递归的过程。下面这张图形象地展示了这个过程的特征:

如图所示,同步渲染的递归调用栈是非常深的,只有最底层的调用返回了,整个渲染过程才会开始逐层返回。这个漫长且不可打断的更新过程,将会带来用户体验层面的巨大风险:同步渲染一旦开始,便会牢牢抓住主线程不放,直到递归彻底完成。在这个过程中,浏览器没有办法处理任何渲染之外的事情,会进入一种无法处理用户交互的状态。因此若渲染时间稍微长一点,页面就会面临卡顿甚至卡死的风险。
而 React 16 引入的 Fiber 架构,恰好能够解决掉这个风险:Fiber 会将一个大的更新任务拆解为许多个小任务。每当执行完一个小任务时,渲染线程都会把主线程交回去,看看有没有优先级更高的工作要处理,确保不会出现其他任务被“饿死”的情况,进而避免同步渲染带来的卡顿。在这个过程中,渲染线程不再“一去不回头”,而是可以被打断的,这就是所谓的“异步渲染”,它的执行过程如下图所示:

换个角度看生命周期工作流
Fiber 架构的重要特征就是可以被打断的异步渲染模式。但这个“打断”是有原则的,根据“能否被打断”这一标准,React 16 的生命周期被划分为了 render 和 commit 两个阶段,而 commit 阶段又被细分为了 pre-commit 和 commit。每个阶段所涵盖的生命周期如下图所示:
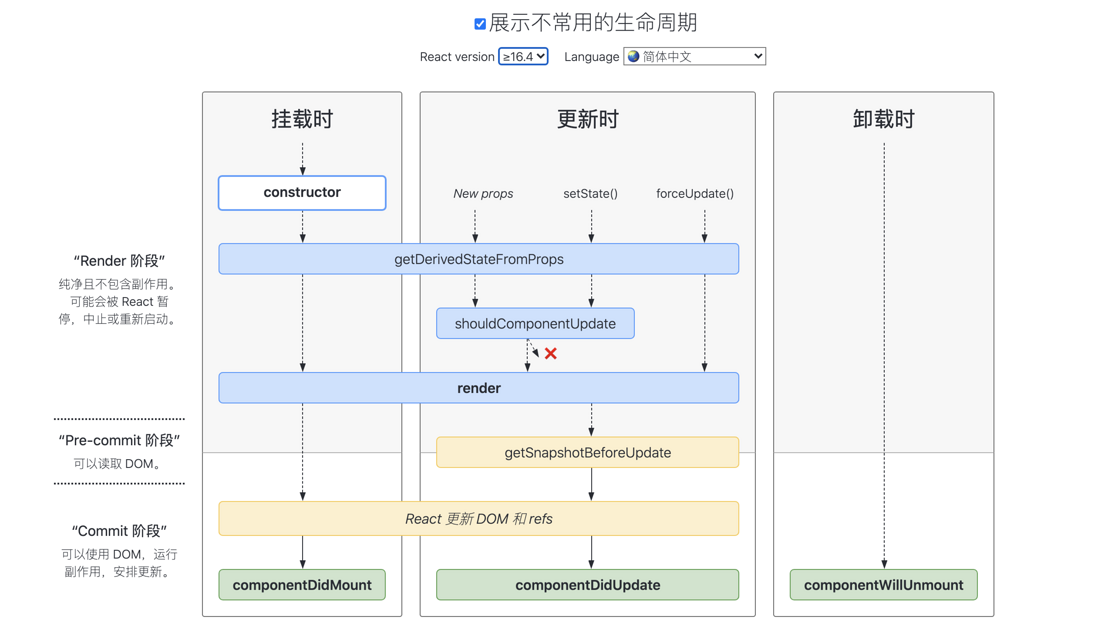
我们先来看下三个阶段各自有哪些特征
render 阶段:纯净且没有副作用,可能会被 React 暂停、终止或重新启动。pre-commit 阶段:可以读取 DOM。commit 阶段:可以使用 DOM,运行副作用,安排更新。
总的来说,render 阶段在执行过程中允许被打断,而 commit 阶段则总是同步执行的。
为什么这样设计呢?简单来说,由于 render 阶段的操作对用户来说其实是“不可见”的,所以就算打断再重启,对用户来说也是零感知。而commit 阶段的操作则涉及真实 DOM 的渲染,所以这个过程必须用同步渲染来求稳。
函数柯里化
什么叫函数柯里化?其实就是将使用多个参数的函数转换成一系列使用一个参数的函数的技术。还不懂?来举个例子。
function add(a, b, c) {
return a + b + c
}
add(1, 2, 3)
let addCurry = curry(add)
addCurry(1)(2)(3)
现在就是要实现 curry 这个函数,使函数从一次调用传入多个参数变成多次调用每次传一个参数。
function curry(fn) {
let judge = (...args) => {
if (args.length == fn.length) return fn(...args)
return (...arg) => judge(...args, ...arg)
}
return judge
}
数组去重
实现代码如下:
function uniqueArr(arr) {
return [...new Set(arr)];
}
对虚拟DOM的理解
虚拟dom从来不是用来和直接操作dom对比的,它们俩最终殊途同归。虚拟dom只不过是局部更新的一个环节而已,整个环节的对比对象是全量更新。虚拟dom对于state=UI的意义是,虚拟dom使diff成为可能(理论上也可以直接用dom对象diff,但是太臃肿),促进了新的开发思想,又不至于性能太差。但是性能再好也不可能好过直接操作dom,人脑连diff都省了。还有一个很重要的意义是,对视图抽象,为跨平台助力
其实我最终希望你明白的事情只有一件:虚拟 DOM 的价值不在性能,而在别处。因此想要从性能角度来把握虚拟 DOM 的优势,无异于南辕北辙。偏偏在面试场景下,10 个人里面有 9 个都走这条歧路,最后9个人里面自然没有一个能自圆其说,实在让人惋惜。
为什么需要浏览器缓存?
对于浏览器的缓存,主要针对的是前端的静态资源,最好的效果就是,在发起请求之后,拉取相应的静态资源,并保存在本地。如果服务器的静态资源没有更新,那么在下次请求的时候,就直接从本地读取即可,如果服务器的静态资源已经更新,那么我们再次请求的时候,就到服务器拉取新的资源,并保存在本地。这样就大大的减少了请求的次数,提高了网站的性能。这就要用到浏览器的缓存策略了。
所谓的浏览器缓存指的是浏览器将用户请求过的静态资源,存储到电脑本地磁盘中,当浏览器再次访问时,就可以直接从本地加载,不需要再去服务端请求了。
使用浏览器缓存,有以下优点:
- 减少了服务器的负担,提高了网站的性能
- 加快了客户端网页的加载速度
- 减少了多余网络数据传输
介绍一下 webpack scope hosting
作用域提升,将分散的模块划分到同一个作用域中,避免了代码的重复引入,有效减少打包后的代码体积和运行时的内存损耗;
常见的浏览器内核比较
- Trident: 这种浏览器内核是 IE 浏览器用的内核,因为在早期 IE 占有大量的市场份额,所以这种内核比较流行,以前有很多网页也是根据这个内核的标准来编写的,但是实际上这个内核对真正的网页标准支持不是很好。但是由于 IE 的高市场占有率,微软也很长时间没有更新 Trident 内核,就导致了 Trident 内核和 W3C 标准脱节。还有就是 Trident 内核的大量 Bug 等安全问题没有得到解决,加上一些专家学者公开自己认为 IE 浏览器不安全的观点,使很多用户开始转向其他浏览器。
- Gecko: 这是 Firefox 和 Flock 所采用的内核,这个内核的优点就是功能强大、丰富,可以支持很多复杂网页效果和浏览器扩展接口,但是代价是也显而易见就是要消耗很多的资源,比如内存。
- Presto: Opera 曾经采用的就是 Presto 内核,Presto 内核被称为公认的浏览网页速度最快的内核,这得益于它在开发时的天生优势,在处理 JS 脚本等脚本语言时,会比其他的内核快3倍左右,缺点就是为了达到很快的速度而丢掉了一部分网页兼容性。
- Webkit: Webkit 是 Safari 采用的内核,它的优点就是网页浏览速度较快,虽然不及 Presto 但是也胜于 Gecko 和 Trident,缺点是对于网页代码的容错性不高,也就是说对网页代码的兼容性较低,会使一些编写不标准的网页无法正确显示。WebKit 前身是 KDE 小组的 KHTML 引擎,可以说 WebKit 是 KHTML 的一个开源的分支。
- Blink: 谷歌在 Chromium Blog 上发表博客,称将与苹果的开源浏览器核心 Webkit 分道扬镳,在 Chromium 项目中研发 Blink 渲染引擎(即浏览器核心),内置于 Chrome 浏览器之中。其实 Blink 引擎就是 Webkit 的一个分支,就像 webkit 是KHTML 的分支一样。Blink 引擎现在是谷歌公司与 Opera Software 共同研发,上面提到过的,Opera 弃用了自己的 Presto 内核,加入 Google 阵营,跟随谷歌一起研发 Blink。
数组扁平化
题目描述:实现一个方法使多维数组变成一维数组
最常见的递归版本如下:
function flatter(arr) {
if (!arr.length) return;
return arr.reduce(
(pre, cur) =>
Array.isArray(cur) ? [...pre, ...flatter(cur)] : [...pre, cur],
[]
);
}
// console.log(flatter([1, 2, [1, [2, 3, [4, 5, [6]]]]]));
扩展思考:能用迭代的思路去实现吗?
实现代码如下:
function flatter(arr) {
if (!arr.length) return;
while (arr.some((item) => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
// console.log(flatter([1, 2, [1, [2, 3, [4, 5, [6]]]]]));







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。