
Redis 项目中,一个名为 "[BUG] Deadlock with streams on redis 7.2" 的 issue 12290 吸引了我的注意。这个 bug 中,redis 服务器在处理特定的客户端请求时陷入了死循环,这个现象在 redis 这样的高性能、高可靠性的数据库系统中是极为罕见的。
这个 Issue 不仅仅是一个普通的 bug 报告,它实际上是一次深入探索 Redis 内部机制的学习过程。从问题的发现,到复现步骤的详细描述,再到问题的深入分析,最后到解决方案的提出,每一步都充满了挑战和发现。无论你是 Redis 的使用者,还是对数据库内部机制感兴趣的开发者,我相信你都能从这个 issue 中获得有价值的启示。
在开始研究这个 bug 之前,我们先简单了解下这里的背景知识:redis 的流数据类型。
Redis streams 介绍
为了支持更强大和灵活的流处理能力,Redis 在 5.0 支持了流数据类型, 包含 XADD, XREAD 和 XREADGROUP。
XADD命令允许用户向 Redis 流中添加新的消息。每个消息都有一个唯一的 ID 和一组字段-值对。这种数据结构非常适合表示时间序列数据,例如日志、传感器读数等。通过 XADD,用户可以将这些数据存储在 Redis 中,然后使用其他命令进行查询和处理。XREAD命令用于从一个或多个流中读取数据。你可以指定从每个流的哪个位置开始读取,以及最多读取多少条消息。这个命令适合于简单的流处理场景,例如,你只需要从流中读取数据,而不需要跟踪读取的进度。XREADGROUP命令是 Redis 消费者组功能的一部分。消费者组允许多个消费者共享对同一个流的访问,同时还能跟踪每个消费者的进度。这种功能对于构建可扩展的流处理系统非常有用。例如,你可以有多个消费者同时读取同一个流,每个消费者处理流中的一部分消息。通过 XREADGROUP,每个消费者都可以记住它已经读取到哪里,从而在下次读取时从正确的位置开始。
我们可以用 XREADGROUP 命令从一个特定的流中读取数据,如果这个流当前没有新的数据,那么发出 XREADGROUP 命令的客户端就会进入一种阻塞等待状态,直到流中有新的数据为止。同样的,我们可以用 XADD 命令向流中添加新的数据,当新的数据被添加到流中后,所有在这个流上"等待"的客户端就会被唤醒,然后开始处理新的数据。
注意这里的"等待"并不是我们通常理解的那种让整个服务器停下来的阻塞。实际上,只有发出 XREADGROUP 命令的那个客户端会进入"等待"状态,而 Redis 服务器还可以继续处理其他客户端的请求。这就意味着,即使有一些客户端在等待新的数据,Redis 服务器也能保持高效的运行。
更多内容可以参考 Redis 官方文档:Redis Streams tutorial。
Bug 复现
好了,我们可以来深入研究这个 bug 了,首先我们来看下复现脚本。一共两个脚本,一个消费订阅者,一个发布者,其中:
- subscriber.py:这个脚本创建了一组订阅者,每个订阅者都尝试创建一个名为 'test' 的任务队列,并持续从该队列中读取新的流。如果没有新的流,订阅者会暂停 5 秒钟,然后继续尝试读取。如果读取到新的流,订阅者会打印出新的流。这个脚本会持续运行,直到所有的订阅者进程都结束。
- feeder.py:这个脚本在同一个任务队列中添加新的任务。它创建了一组发布者,每个发布者都会在任务队列中添加新的任务,并在每次添加任务后暂停 0.1 秒钟。这个脚本会持续运行,直到所有的发布者进程都结束。
subscriber.py 代码如下
import time
from multiprocessing import Process
from redis import Redis
nb_subscribers = 3
def subscriber(user_id):
r = Redis(unix_socket_path='cache.sock')
try:
r.xgroup_create(name='tasks_queue', groupname='test', mkstream=True)
except Exception:
print('group already exists')
while True:
new_stream = r.xreadgroup(
groupname='test', consumername=f'testuser-{user_id}', streams={'tasks_queue': '>'},
block=2000, count=1)
if not new_stream:
time.sleep(5)
continue
print(new_stream)
processes = []
for i in range(nb_subscribers):
p = Process(target=subscriber, args=(i,))
p.start()
processes.append(p)
while processes:
new_p = []
for p in processes:
if p.is_alive():
new_p.append(p)
processes = new_p
time.sleep(5)
print('all processes dead')feeder.py 代码如下:
import time
import uuid
from multiprocessing import Process
from redis import Redis
nb_feeders = 1
def feeder():
r = Redis(unix_socket_path='cache.sock')
while True:
fields = {'task_uuid': str(uuid.uuid4())}
r.xadd(name='tasks_queue', fields=fields, id='*', maxlen=5000)
time.sleep(.1)
processes = []
for _ in range(nb_feeders):
p = Process(target=feeder)
p.start()
processes.append(p)
while processes:
new_p = []
for p in processes:
if p.is_alive():
new_p.append(p)
processes = new_p
time.sleep(5)
print('all processes dead')注意这里 unix_socket_path 要改为自己 server 配置的 socket path。我们先启动发布者 feeder.py 往流里面写数据,再用 subscriber.py 来消费流。预期的正常表现(Redis server v=7.0.8上就是这个表现)是 subscriber 会持续取出 feeder 往流里面写入的数据,同时 redis 还能响应其他 client 的请求,server 的 CPU 占用也是在一个合理的水平上。
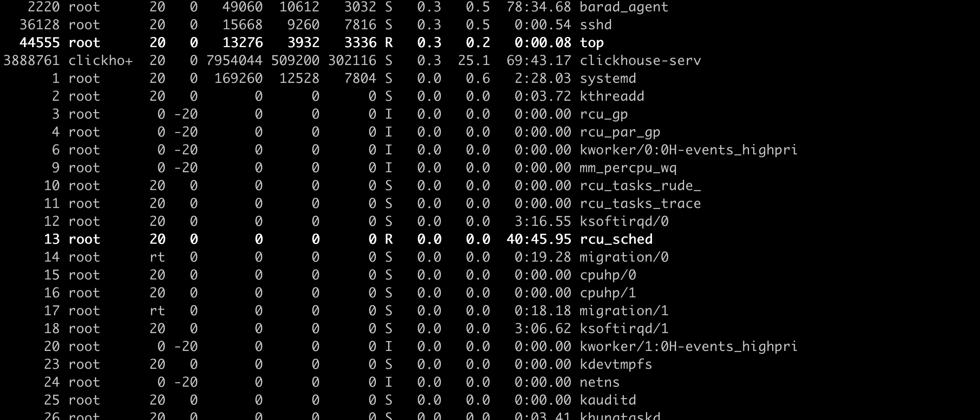
但是在 7.2.0 版本(源码是 7.2.0-rc2,编译好的 server 版本是 v=7.1.241)上,这里就不太正常了。我们直接从 Github Release 7.2-rc2 下载 Reids 7.2 的源码,然后编译二进制。这里编译指令带上这两个 Flag make REDIS_CFLAGS="-Og -fno-omit-frame-pointer"",方便后续分析工具能够拿到堆栈信息。复现步骤很简单,启动 Redis server,接着运行 feeder.py 和 subscriber.py 这两个脚本。我们会看到订阅者在处理部分流之后会阻塞住,不再有输出。同时 Redis 进程的 CPU 直接飙到了100%,新的 redis client 也连不上去服务器了,如下图。

杀了两个脚本后,问题依然存在,除非重启 server 才行。

ebpf 分析
我们先不去看 Issue 上对于问题原因的分析,直接用一般方法来分析这里 CPU 占用高的原因。分析 CPU 首选 profile 采样,然后转成火焰图来看。这里强烈推荐 brendangregg 的博客 CPU Flame Graphs,介绍了针对不同语言的服务,如果用工具来分析 CPU 占用。对于 Redis 来说,官方也给出了文档,我们这里参考官方的 Redis CPU profiling,用 ebpf 生成 CPU 火焰图。
如何安装 bcc-tools 可以看官方文档,这里不展开了,然后我们就可以用 profile 工具来做 cpu 采样。
$ profile -F 999 -f --pid $(pgrep redis-server) 60 > redis.folded.stacks
$ ../FlameGraph/flamegraph.pl redis.folded.stacks > redis.svgprofile 是 BCC(BPF Compiler Collection)工具集中的一个工具,用于采集 CPU 的堆栈跟踪信息。这个命令的参数含义如下:
- -F 999,设置采样频率为 999 Hz,即每秒采样 999 次,采样频率选择奇数 999 是为了避免与其他活动产生同步,从而可能导致误导性的结果。如果采样频率与系统中的某些周期性活动(如定时器中断、上下文切换等,一般都是偶数周期,比如 100Hz)同步,那么采样结果可能会偏向于这些活动,从而导致分析结果的偏差。
- -f 折叠堆栈跟踪信息,使其更适合生成 Flame Graphs。
- --pid $(pgrep redis-server),指定要采集的进程 ID,这里使用 pgrep redis-server 来获取 redis-server 进程的 PID。
- 60,采集的持续时间,单位为秒,redis 官方文档给的 profile 命令可能不适用某些版本。
接着使用了 flamegraph.pl 脚本,它是 FlameGraph 工具集中的一个脚本,用于将堆栈跟踪信息转换为 SVG 格式的 Flame Graphs。最终生成的 CPU 火焰图如下,这里手动过滤了极少部分 unknow 的调用堆栈(不然图片看起来太长了,有点影响阅读)。

通过火焰图,我们找到了 CPU 跑满的执行堆栈,下一篇文章,我们继续分析为啥一直在执行这里的代码了。
本文由selfboot 发表于个人博客,采用署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议。
非商业转载请注明作者及出处。商业转载请联系作者本人
本文标题为:Redis Issue 分析:流数据读写导致的“死锁”问题(1)
本文链接为:https://selfboot.cn/2023/06/14/bug_redis_deadlock_1/







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。