
本文作者:胡亦萍
业界有非常多优秀的API文档管理方案,大多都是基于IDE插件或maven插件的方式做集成。本文主要介绍云音乐自研的基于代码关系、中心化、自动化的API文档管理方案。
背景
随着微服务的发展,在前后端基于API协作的研发模式下,业界涌现了一批优秀的API文档管理工具,如网易自研的NEI、swagger、yapi、smart-docs等等,这些工具通过围绕API文档构建了一系列的能力,极大提升研发效率。
但随着研发流程的迭代更新,也对API文档管理提出了更高的要求。云音乐使用的NEI处于维护阶段,相关功能已经无法满足最新的研发要求,主要体现在:
- 依赖手动更新,比较依赖研发人员,文档信息变更时容易存在通知遗漏,影响下游测试或对接方获取最新信息。
- 与研发流程结合度低,NEI是基于项目维护API文档信息,缺少研发流程信息,与研发流程的其他系统存在割裂。
- API文档维护与代码分离严重,很多代码不维护API文档注释,信息只维护在NEI,随着时间的流逝信息的不一致也给维护带来了问题。
所以我们希望通过构建一个全新的API文档管理平台,解决当前存在的问题,推进API标准化,同时增强API文档的生命周期管理,与研发流程更紧密结合,进一步促进研发提效。
思路&方案
思路
API文档管理平台首先需要确保API文档准确性,在此基础上降低研发人员的维护成本,所以我们需要解决以下几个关键问题:
- 如何解决当前存在的文档与代码分离带来的维护问题?
业界的API文档管理工具基本上都给出了答案,使用javadoc注释。javadoc作为一个通用的类、方法、成员等注释提取标准,使用javadoc作为不需要额外的代码侵入,有天然的优势,而且市面上的AST工具也都支持javadoc提取;通过javadoc可以非常方便地实现代码即文档,降低维护成本。 - 如何及时完成API文档创建和更新,且同时保证等待耗时较小呢?
云音乐的代码都是使用gitlab进行管理,所以我们可以利用gitlab的webhook进行commit信息的推送,基于推送的变更信息做增量解析,避免全量代码的冗余处理;同时采用源码解析方式,减少编译带来的时间损耗;但这里也存在一个问题,就是依赖研发人员及时push代码。 - 增量的commit其实存在信息缺失的情况,如何保证完整的变更信息被有效识别?
API文档中的关系包含API与数据模型的关系、数据模型与数据模型的关系。如果我们能够有效地管理他们的关系,那在增量解析的时候就可以通过这些关系获取完整的信息,从而进行有效的API文档更新。使用传统的数据库无法高效地维护关系,但图数据库能很好地解决这个问题。当某一节点变更时,通过查询节点间的路径关系可以快速获取完整的受影响范围,从而进行有效的信息更新。
基于上述思考,我们确定了以代码为依据,基于AST解析的API文档管理方案。
整体方案

关键流程

- 新接入的应用(由研发协作平台通知)做全量的代码扫描,后续基于gitlab的推送进行增量代码扫描;全量扫描后生成基线的代码关系。
- 基于增量代码分析获取基础的变更信息,再基于代码关系获取完整的变更影响范围;每次变更分析后更新代码关系。。
- 基于完整的变更范围解析出完整的接口变更信息,更新API文档。
- 对更新的API文档进行变更分析,生成变化的差异表;下游可以通过差异表很容易获取变更的内容。
- 基于代码所属应用与需求的关系获取API的干系人并进行通知。
关系管理
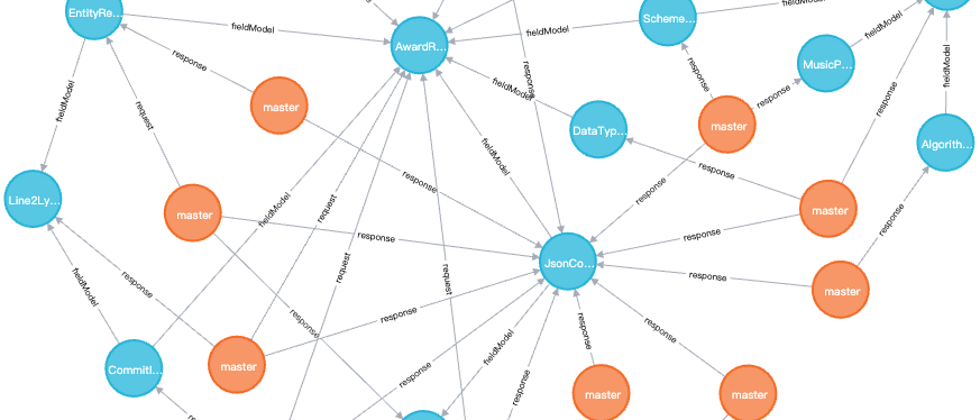
关系管理在是本方案中一个非常重要的支撑,如果关系无法有效管理,就无法实现高效准确的API文档更新。最终的关系如下图所示

图数据库中管理的关系包含:
- API节点与数据模型节点的关系:请求、响应等。
- 数据模型节点与数据模型节点关系:字段、关联、继承等。
其中所有的节点都包含分支属性,分支属性在节点中的维护的关系如下:

- 基线关系:master分支节点之间,如DtoA某个字段为DtoB,则关系为DtoA(master)-[field]->DtoB(master)
当进行分支开发时:
- 当在dev分支中DtoB节点变更,则此时的关系为DtoA(master)-[field]->DtoB(master),DtoA(dev)-[field]->DtoB(dev)
- 如DtoA节点变更,则此时的关系为DtoA(master)-[field]->DtoB(master),DtoA(dev)-[field]->DtoB(master)。
- 如果没有master分支,只有开发分支,则此时不存在基线关系,所有的分支都按相同分支名维护
功能展示
API文档详情

API文档变更内容

API文档变更通知

实践的过程遇到的一些问题
- 因为采用源码解析,如果API中引用了二方包,会导致API文档信息缺失
基本二方包的维护也是基于git仓库,所以我们约定采用相同分支名进行全局匹配的策略(存在极少的相同路径的情况使用特殊处理)。 虽然我们在定API标准的时候希望不要有非标的结构,但在实际的API文档的维护中,不可避免会有定义Map结构的场景。
针对这种情况,我们通过引入特殊的解析逻辑,如下所示@Data public class AppDTO { /** * 应用id */ private Integer id; /** * 测试map, * * @OxLink key1 描述1 {@link CanvasDTO} * @OxLink key2 描述2 {@link AppDTO} * @OxLink key3 描述3 {@link ComponentDTO} */ private Map<String, Object> addedMap; }

总结
这种代码即文档的中心化API文档管理实践带来了许多好处。首先,开发人员只需要在代码中进行Javadoc的修改,就能自动更新API文档,大大简化了文档维护的工作。其次,这种方案使得大部分场景下的API文档更新可以在30秒内完成,提高了开发效率。最重要的是,开发人员将API信息维护在代码中,保证了文档与实际代码的一致性。
最后

更多岗位,可进入网易招聘官网查看 https://hr.163.com/







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。