
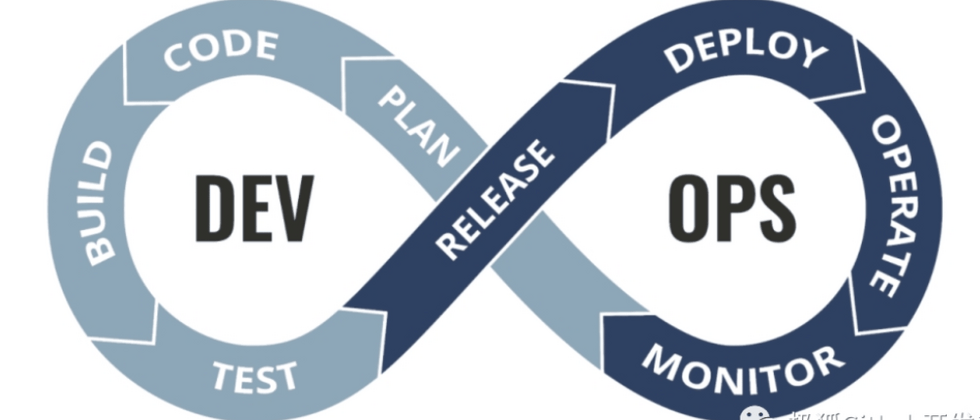
什么是 MLOps
首先我们可以这么定义机器学习(Machine Learning):通过一组工具和算法,从给定数据集中提取信息以进行具有一定程度不确定性的预测,借助于这些预测增强用户体验或推动内部决策。
同一般的软件研发流程比较起来,机器学习的研发流程是一个很特殊的存在,它无法仅仅由代码逻辑定义。训练样本集、标注样本方法、数据集处理方式、训练时的超参和实际运行环境数据等等,和它都有关联,而且上述任何数据和代码的更改都都会导致最终模型的变更,乃至影响到最终预测结果产生巨大变化。这意味着,预测或分类的实际结果不仅取决于数据科学家提出的神经网络架构和机器学习方法,还取决于开发团队如何实现这一模型,以及管理员如何在集群环境中部署这一模型。
此外,在机器学习解决方案的开发、测试、部署和支持过程中,多学科专家在互动中会遇到许多组织难题和技术障碍,这不仅延长了产品创建的时间,还降低了产品带给该项业务的实际价值。为了消除这些障碍,MLOps 这一概念应运而生。
我们可以认为:MLOps 就是机器学习时代的 DevOps。它的主要作用就是连接模型构建团队和业务,运维团队,建立起一个标准化的模型开发,部署与运维流程,使得企业组织能更好的利用机器学习的能力来促进业务增长。
维基百科中关于 MLOps 的定义是这样的:
MLOps 是 ModelOps 的子集,是数据科学家和操作专业人员之间进行协作和交流的一种做法,可帮助管理生产机器学习生命周期。与DevOps或DataOps方法相似,MLOps旨在提高自动化程度并提高生产ML的质量,同时还关注业务和法规要求。
MLOps 和 DevOps 的异同
DevOps 发展到现在已经非常成熟了,有丰富的理论和多样化的实践方式,DevOps 可以赋能软件开发的全生命周期,提供的端到端交付能力是主力企业数字化转型的关键。现在已经进入了 DevOps 平台化时代。

与 DevOps 不同的是,MLOps 还包含构建/训练机器学习模型所需的额外数据和模型步骤(见下图)。这意味着 MLOps 最终对工作流的每个组件都有一些细微差别。

在大部分情况下,上图中 “ML” 阶段的 “Data” 和 “Model”,代表了数据标记、数据转换/特征工程和算法选择过程。从大的方面看,一个 MLOps 的生命周期有如下几个过程:
1. 训练和测试
首先,数据科学家需要准备训练数据。将数据标准化,使其采用可重用格式并标识各自的“特征”或变量。将算法应用于数据,对机器学习模型进行训练。然后,通过新数据对其进行测试,了解其预测的准确性。
2. 打包
ML 工程师使用其环境将模型打包,比如:容器化。模型环境包含模型需要执行的元数据和配置等。
3. 验证
评估模型性能如何匹配其业务目标。
4. 重复步骤 1 到 3
实际生产环境中,找到合适的模型可以需要成百上千的训练小时。可以通过调整训练数据、优化算法超参或更改算法,对模型进行训练。最终确定哪个模型版本最适合当前业务。
5. 部署
将模型部署在指定生产或者测试环境中。
6. 监视和重新训练
对部署的模型相关指标持续监控,视情况进行数据或模型的降级,模型的重新训练与重新部署,确保预测的质量和效率。

由此可见,MLOps 整体流程和我们熟知的 DevOps 非常相似,之所以没有直接用 DevOp s来解决 Machine Learning 的开发,是因为二者之间依然存在着不小差异。
首先传统软件开发领域,软件(或代码)行为有明确的规则,是可预测的。我们与之交互的软件都是基于多样化的输入,通过各种编程语言复杂的控制结构和处理逻辑来对输入做出相应的响应;而 MLOps 领域没有明确的规则,它的规则是通过从训练数据中捕获模式来间接学习设置的,这使得ML更适合于处理数值类型的问题和分类问题,比如根据公司人员数目,从事领域,税收情况,行业发展趋势等预测公司季度营收;根据已有图像资料,分析给定图像是什么等等,这里ML的模型返回的是预测的值或者是落入特定类别的概率。
DevOps 领域最终的产出是可执行的二进制文件,MLOps 最终产出是一个序列化到文件,即模型,模型在实际环境中运行结果不仅仅由代码决定,模型训练数据,超参数配置的影响同样非常巨大,此外,MLOps的版本控制要求更高,除了代码和模型以外,还需要跟踪对应的模型训练数据,超参数配置等,相应的,这也就导致了在排错和调优时候难度也更大。
DevOps 领域产品理想情况下会一直稳定运行下去,外界环境和输入数据不会对自身行为造成影响;但 MLOps 产品不行,随着运行环境和输入数据的细微更改和调整,数据模型的预测数据会不可避免的产生飘移,此时需要视情况作出一些应对,比如:更改超参数配置;修改代码或者训练数据;甚至更改模型算法,因此相对于 DevOps CI/CD 流程,MLOps 新增了 CT 的概念,即持续训练(Continuous Training),使得模型在运行过程中可以持续得到自动化的训练与更新。
极狐GitLab 中的MLOps
既然 MLOps 和 DevOps 在整体流程上有高度相似度和重合度,而且极狐GitLab 已经是业界公认的 DevOps 领域的标杆,因此如何将极狐GitLab 应用于 MLOps 领域就是我们接下来面临的问题。
首先,极狐GitLab 在 MLOps 领域的定位和目标是什么?
这里我们引用极狐 GitLab 官方的说法:
Make GitLab the perfect companion for a Machine Learning Engineer or Data Scientist,and provide a better user experience for them across the entire Machine Learning life cycle (model creation, testing, deployment, monitoring, and iteration)让极狐GitLab 成为机器学习工程师和数据科学家的完美伙伴和工具,并在整个机器学习生命周期(模型创建、测试、部署、监控和迭代)中为他们提供更好的用户体验。
极狐GitLab 没有计划成为一个功能完善的 All-in-One 的 MLOps 平台,现阶段充分利用极狐GitLab 自身在 DevOps 方面的优势(尤其是CI/CD、pipeline、security方面),能够整合主流的 MLOps 平台或者服务,并为用户基于 极狐GitLab构建自己的 MLOps pipeline 提供便利即可。
结合上文提到的 MLOps 各个阶段,从技术角度理解就是:极狐GitLab 作为 SCM 保存相关代码算法,超参数配置,乃至训练数据,通过 CI/CD pipeline 串起并触发整个 MLOp s流程,根据整合的其他 MLOps 平台和实际情况,数据处理,模型训练,模型性能验证等步骤都可以在第三方平台完成。

MLOps 整体的pipeline 由 极狐GitLab 平台管理维护,DevOps 相关的阶段都由 极狐GitLab 平台自身的 CI/CD Pipeline 来实现,包括打包,测试,部署等等,ML 特定的步骤调用整合的第三方 MLOps 平台的 pipeline 实现(需要通过 SDK 或者 REST 方式传递代码和数据),将来这些阶段也可以在极狐GitLab 实现;通过极狐GitLab CI 的配置,当源代码/配置/训练数据集产生更改后,会自动触发 Model 的训练,此外,模型监控到出现飘移或者预测错误率达到到指定阈值后,同样会触发 Model 的重新训练。
对于 POC 性质或者简单的 ML 项目,上述所有阶段都可以基于极狐GitLab 来实现,下面就是一个用极狐Gitlab CI 来实现经典的 fashion-mnist 的 MLOps 示例:

如上图所示,MLOps 整体的 pipeline 都由极狐GitLab CI 实现,各 Stage 功能说明如下:
Train
加载 fashion_mnist 训练数据集(训练集 60000 张图片,测试集 10000 张图片),进行数据的预处理,然后依据指定算法训练 Model,生成的 Model 保存在极狐GitLab 的 artifact 中。Model 的 train 过程由极狐GitLab 来实现。本示例中是在 Specific Runner 中完成,也可以将 train 操作放在 Kubernetes 集群或者第三方 MLOps 平台完成。
Build
完成 Model 训练后,将 Model 打包为 docker 镜像。这里使用了极狐GitLab 开箱即用的镜像仓库服务,更多详情可以查看公众号文章:极狐GitLab 容器镜像仓库的使用技巧。生成的镜像最终会保存在极狐GitLab 的 Container Registry中。
Deploy
将 Model 服务部署到指定位置,可以是 VM 或者 Kubernetes 平台。为方便测试,本示例中直接部署在指定 Specific Runner 所在主机。
Inference
加载 fashion_mnist 测试数据集,然后调用刚刚部署的 Model 服务,查看 Model 对测试数据集的预测结果情况。
Cleanup
清理数据。
执行上述pipeline后,可以看到最终执行结果如下:

对于稍微复杂的 ML 项目,上述 demo 中采用的实现方式就不适用,有更多其他因素需要考虑,比如 Model 的保存和维护;ML 整体版本管理;Model 训练在哪里执行;Model 评估和再训练等等。
面临的挑战和展望
- 数据科学家和工程师需要熟悉基于极狐GitLab 的 GitOps 工作流程以及通过极狐GitLab CI 来构建 MLOps 管道的工作方式。
- 当前通过极狐GitLab 的 CI 来管理 MLOps 整个生命周期流程没有现成的模版可用。
- 这意味着对于每个 MLOps 项目,需要数据科学家自己手动编写各个阶段的 yml 脚本,比如准备环境、创建工作空间、提交作业进行培训,注册模型、比较、评分和发布等等。
缺少与主流 MLOps 平台整合和使用的相关文档。
当前模型训练、评估选择、模型保存这些 ML 特有功能是极狐GitLab 所不具备的,需要交由第三方平台完成,因此与主流 MLOps 平台(商业或者开源)整合和支持就是不可或缺的,比如 AML,MLFlow,DVC 等等。针对不同第三方平台需要提供不同的CI Job模版
- 极狐GitLab 作为基于 Git 的 DevOps 平台,不擅长保存处理海量数据,而 MLOps 面对的往往是大量数据的长时间处理,比如用于训练模型的数据集,可以是文本,图片,音频或者视频资料,动辄是TB数量级,一个模型的训练可能耗时几十上百小时,这种大数据量计算密集型任务,对极狐GitLab 的 SCM, Runner 和现有 CI/CD 工作机制都提出了不小挑战,比如:极狐GitLab 如何保存训练用的数据集;在模型训练和评估时,极狐GitLab 与第三方 MLOps 平台之间消息调用机制等等
极狐GitLab 针对这些问题和已知痛点,已经在着手提供解决方案,包括如下几个方面:
- 调研主流 MLOps 平台,集成到极狐GitLab,并提供对应的极狐GitLab CI 模版。
- 完善极狐GitLab 既有的 SCM、pipeline 功能,以便能更好支持 MLOps 相关的代码语言,比如完善对 jupyter notebook 类型脚本语句的支持。
- 提供与一些开源 MLOps 平台(比如 MLFlow,DVC)整合使用的示例项目,并提供完整代码和说明文档。
- 极狐GitLab 和第三方平台之间稳定可靠的消息事件传递或函数调用,确保在模型训练,飘移监测,性能评估等事件能被感知到并触发相应的pipeline。
MLOps 是个相对比较新颖的概念和领域,其理论和工具都还远没达到 DevOps 的成熟度,不过随着 MLOps 越来越被人们重视,极狐GitLab 也将在 MLOps 领域的持续发力,将来也会有让人亮眼的表现。
参考链接
- https://gitlab.com/gitlab-org/incubation-engineering/mlops/me...
- https://zhuanlan.zhihu.com/p/357897337
- https://www.phdata.io/blog/mlops-vs-devops-whats-the-difference/
- https://github.com/microsoft/MLOps
- https://about.gitlab.com/handbook/engineering/incubation/mlops/
- https://hackernoon.com/why-is-devops-for-machine-learning-so-...




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。