

概述
传统商品检索需要依赖人工解析和构建商品的描述字段,将商品信息存入 ElasticSearch 或数据库,然后通过分词查询结合多重条件(类别或其他属性)检索到匹配的商品。
但是在传统检索中,因为分词本身的特点,经常会遇到误匹配的问题,例如:我们检索 "苹果耳机"的时候,往往会出现苹果和耳机的相关商品,导致客户体验效果不佳。
为了让检索更人性化,我们可以借助 RAG 技术,在传统分词搜索的基础上融入向量检索的能力,从而获得更贴近人类需求的检索效果。
名词解释
在开始之前,我们先把本文中需要用到的一些技术/接口/产品的专有名词做个说明,方便大家更好地理解文档:
- RAG: 检索增强生成(Retrieval-augmented Generation),简称 RAG
- ES: Elasticsearch 是一个开源的分布式搜索和分析引擎,常用于实时搜索、日志分析、数据可视化等应用
- BES:百度 Elasticsearch(BES)是百度托管的 Elasticsearch 服务,完全兼容开源 Elasticsearch 的功能
- Embedding:向量是一种数学技术,用于将对象或概念映射到高维空间,通过向量表示捕捉语义关系和数据结构
- Prompt:用户或程序向模型提供的输入文本或指令,以引导模型生成特定类型或内容的响应
- ERINIE 4.0: 百度自行研发的文心产业级知识增强大语言模型 4.0 版本
思路分析
好了,我们看一下整体的实现思路:
- 数据准备:解析文档中的商品信息
- 数据切片:商品信息按照一定规则进行切片
- 向量化:对切片信息进行向量化处理
- 数据存储:将商品信息及其向量信息存储到向量数据库
- 数据检索:将检索的内容进行向量化存储,利用向量数据库的向量检索能力召回最近似的商品切片信息
- 重排序:对于召回的数据利用重排序算法,按照相似度由高到低重新排序
- 返回数据处理:利用大模型解读排序后的商品切片信息,输出给用户
本文使用python编码。
整体的实现流程如下图所示:

数据准备 & 数据切片
我们准备了一个示例文档,大家可以这个文档来解析商品信息,也可以自己准备对应的数据。
示例数据: https://bcets.bj.bcebos.com/smzdm\_product.pdf
准备好数据后,我们使用百度千帆 Appbuilder 的文档解析组件来提取文档内容(详细介绍和使用方法参考 DocParser )
DocParser支持 PDF、JPG、DOC、TXT、XLS、PPT 等 17 种文档内容的解析,可解析得到文档内容、版式信息、位置坐标、表格结构等信息。
我们使用下面的代码解析示例的 PDF 文件:
from appbuilder.core.components.doc_parser.doc_parser import DocParser
from appbuilder.core.message import Message
msg = Message(file_path)
parser = DocParser()
parse_result = parser(msg)
page_contents = parse_result.content.page_contents请注意 PageContent 类型信息比较零散,需要手动合并内容:
chunk = []
for layout in doc.page_layouts:
chunk.append(layout.text)
# 标题置顶
if doc.titles:
chunk.insert(0, doc.titles[0].text)
# 若有表格,此案例暂无
if doc.tables:
pass
return "\n".join(chunk)按页对数据进行合并,并添加元信息:
docs = []
metadata = []
for page_content in page_contents:
result = merge_chunk(page_content)
docs.append(result)
metadata.append({"page": page_content.page_num + 1, "filename": file_path.split("/")[-1], "type": "pdf"}) ##获取内容文件元数据信息,方便追溯召回数据
return docs, metadata提示:这时提取的数据粒度比较粗,要获取更好的最终效果,可以考虑将切分后的数据传给大模型,进一步提炼和完善。
向量化 & 数据存储
下面我们使用 千帆 embedding-v1 模型 进行数据向量转化,并将转化后的数据写入 BES 集群 索引中。
请注意传给模型的信息需要符合模型限制条件,通常文字长度更简短,语义更准确会有更好的向量检索效果:
- 参数中一次传入的文本数量不能超过 16 个
- 每个文本长度不能超过 384 tokens 且不能超过 1000 字符
将文本切分成小于 max\_tokens 的字符串数组,并确保每个切片有 overlap\_ratio 的重叠:
overlap_size = int(chunk_size * overlap_ratio)
chunks = []
start = 0
while start < len(text):
end = min(start + chunk_size, len(text))
chunks.append(text[start:end])
start += chunk_size - overlap_size
return chunks调用 embedding 模型将数据向量化,并存入 BES :
text_slices = []
if text_tokens > 500:
print(f"Notice: {text_tokens} tokens, too long. Splitting text...")
text_slices = split_text_with_overlap(page_text)
else:
text_slices = [page_text]
for slice_text in text_slices:
resp = qianfan.Embedding().do(model="embedding-v1", texts=[slice_text]) ##使用千帆 SDK 请求 embedding-v1 模型
data_list = resp.get('data', [])
if data_list and isinstance(data_list[0], dict):
embedding_info = data_list[0].get('embedding') ##获取 384 维的向量数据
page_info = {
"filename": file_path.name,
"page_num": page_content.page_num+1,
"text": slice_text,
"embeddings": embedding_info
}
res = es.index(index="intellisearchproduct", body=page_info) ##调用 es 接口将数据写入对应索引,注意索引对应向量字段也得是 384 维
#print(f"es write info: {page_info}\n,write result: {res}")数据检索(我们省略了重排序步骤,感兴趣的小伙伴可以自行了解以下 rerank 模型)
接下来需要将客户查询的内容也转为向量数据:
input_text = request.json.get('input_text')
if not input_text:
return jsonify({'error': 'Missing input_text parameter'}), 400
resp = qianfan.Embedding().do(model="embedding-v1", texts=[input_text])
data_list = resp.get('data', [])
if data_list and isinstance(data_list[0], dict):
results = search_es(input_text, data_list[0].get('embedding'))
if results:
final_json = perform_source_tracking(input_text,results)
else:
return jsonify({'message': '未找到相关结果'})
else:
return jsonify({'message': '向量转化接口异常,数据列表为空或格式不正确'})
return jsonify(final_json)然后传给 BES 发起 向量检索 ,这里可以灵活构建聚合查询请求,比如配置常规查询与向量检索权重等,以提升检索效果。
以下是一个简单得查询示例:
query_body = {
"size": 3,
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "bpack_knn_script",
"lang": "knn",
"params": {
"k": 10, ##查询的最近邻的数量
"ef": 20, ##通过ef参数指定在每个shard检索时的候选队列大小,用于平衡查询性能和召回率,等同于ES8的num_candidates参数
"space": "cosine",
"field": "embeddings",
"vector": embedding_text
}
}
}
}
}
res = es.search(index="intellisearchproduct", body=query_body)
docs = []
for r in res["hits"]["hits"]:
print({"text": r["_source"]["text"], "filename": r["_source"]["filename"], "page_num": r["_source"]["page_num"], "score": r["_score"]})
docs.append({"text": r["_source"]["text"], "filename": r["_source"]["filename"], "page_num": r["_source"]["page_num"], "score": r["_score"]})
return docs返回数据处理
将召回的结果传给大模型,通过提示词让大模型理解并提供更人性化的输出:
texts = ""
results_list = []
for idx, result in enumerate(results):
url = f"http://xxxx/{result['filename']}?x-bce-process=doc/preview,tt_image,p_{result['page_num']}"
result_info = {
"页码": result['page_num'],
"分数": result['score'],
"文本": result['text'],
"图片URL": url
}
results_list.append(result_info)
texts += result['text']
querytext = f"""用户问题:{input_text}
[参考资料]:{texts}
```
根据参考资料里的知识点回答用户问题,未检索到的礼貌拒答
"""
resp = qianfan.ChatCompletion().do(endpoint="completions_pro", messages=[{"role":"user","content": querytext}], temperature=0.95, top_p=0.8, penalty_score=1, disable_search=False, enable_citation=False)
## 通过千帆 SDK 调用 ERINIE-4.0-8K 模型解读客户的查询
final_json = {
"results": results_list,
"resp_body_result": resp.body['result']
}
return final_json
到这里就初步完成了,当然除了本文中列出来的这些技术点,还有很多其他的优化手段,感兴趣的小伙伴可以自行探索一下。最终的实现效果是这个样子:
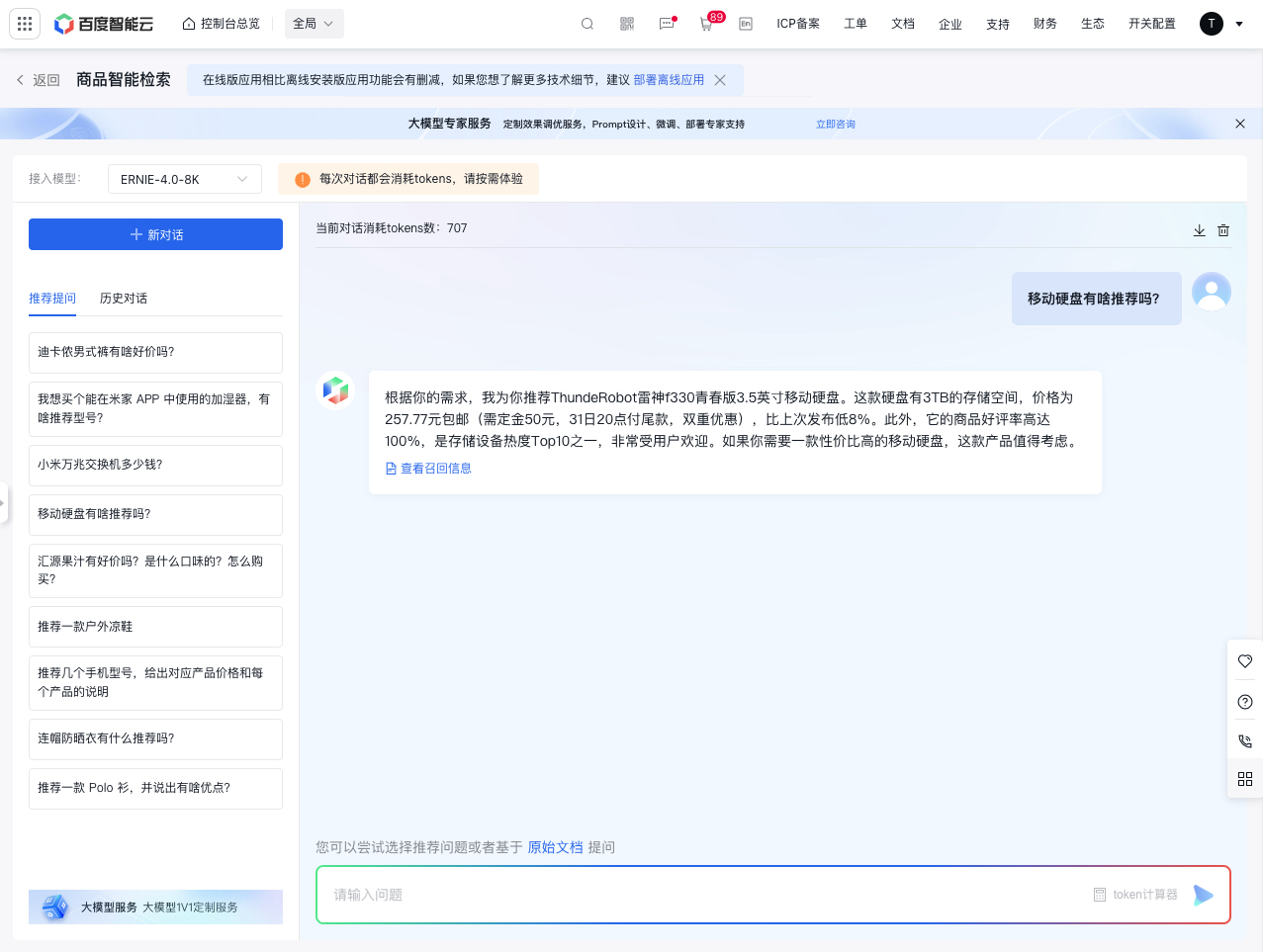
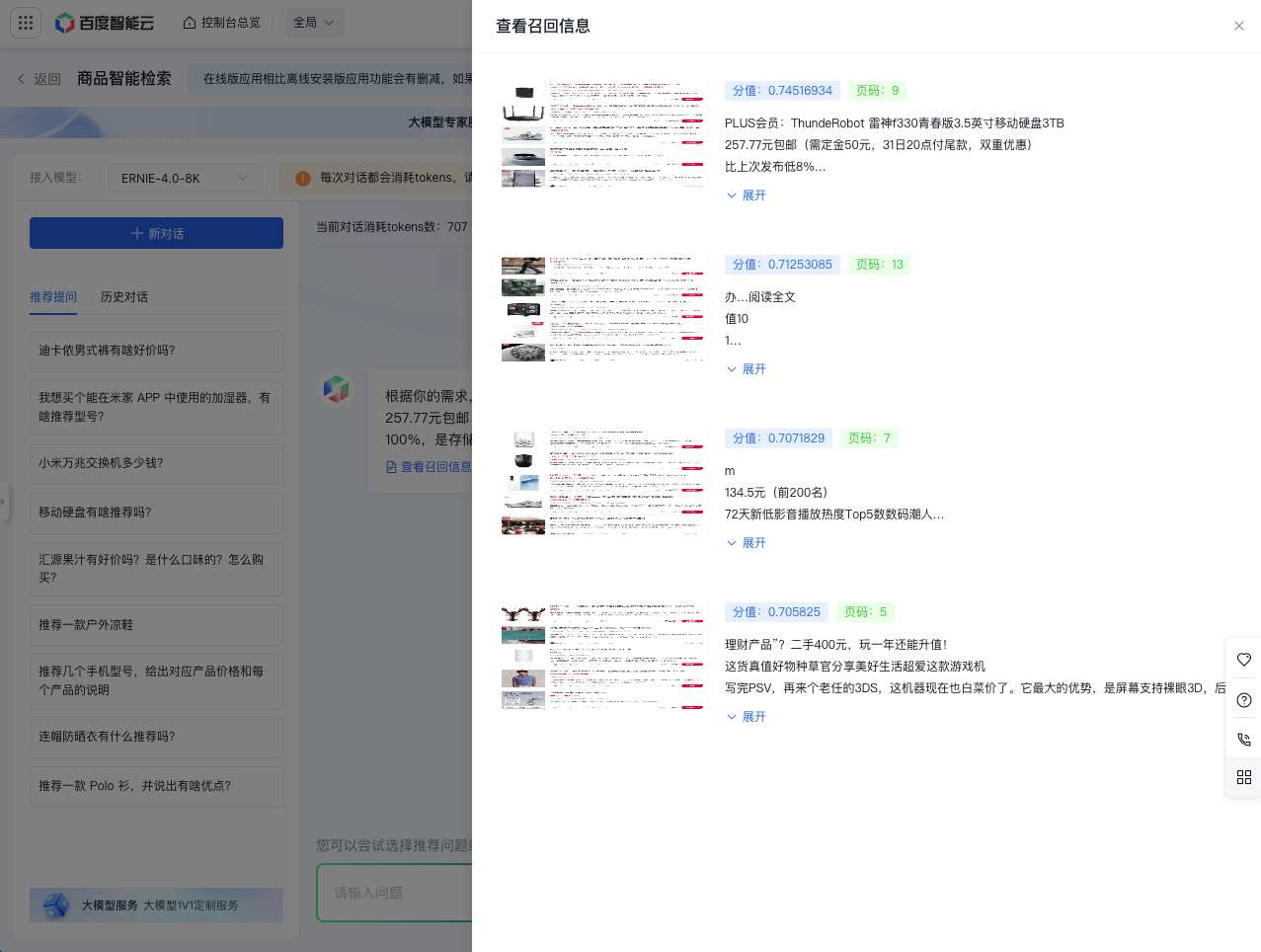
针对大模型的实际业务场景,我们也提供了非常多的示例样板间供大家参考,欢迎体验: [https://console.bce.baidu.com/support/?u=bce-head#/sampleAppCenter](https://console.bce.baidu.com/support/?u=bce-head#/sampleAppCenter/chat-demo)





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。