

背景
Redis 热 key 问题是指单位时间内,某个特定 key 的访问量特别高,导致某个 Redis 节点承载了绝大部分流量,而其他 Redis 节点却处于”空闲“状态。极短的流量倾斜问题就可能会将某个 Redis 节点打挂。从数据层角度看,Redis 集群某个分片的数据缺失,导致缓存雪崩。从应用层角度看,用户请求将大量超时和不可访问
出现 Redis 热 key 的场景有很多,比如:爆款商品、刷子用户、秒杀商品等。不过我们很多时候是无法提前预知热 key 的发生的
同时,解决 Redis 热 key 问题不能单单通过扩容解决,因为热点的发生是短暂、集中且流量巨大的,我们不可能在极短的时间内实现对某个 Redis 节点扩容。同时热点也是随时变化的。如果是对所有 Redis 节点扩容,那成本划不来,因为实际上只有极小一部分 Redis 节点被热 key 问题影响了
所以,接下来我们就来看看,如何「发现+解决」热 key 问题
发现热 key
Redis Monitor 命令
Redis 提供了 Monitor 命令,可以实时监听 Redis 服务器上的所有请求。通过分析这些命令,可以识别哪些键被频繁访问,从而发现热 key
存在问题
- 性能开销非常大,尤其是在高并发环境下。Monitor 会影响 Redis 服务器的响应时间,甚至可能导致 Redis 宕机
- 还需要进一步通过请求流量分析来识别热 key,而无法提供关于热键本身的直接统计信息
抓包分析
RESP 是 Redis 基于 TCP 实现的应用层协议。可以通过正向代理或抓包工具解析 RESP,来统计 key 的访问频率
存在问题
- 通过抓包分析会带来额外的性能损耗
- 实现复杂
Client 端收集
客户端收集所有访问的 key,在本地计算出热 key
存在问题
- 客户端负载增加
- 内存开销大。如果对 key 进行全量统计,那么对内存可能会是个巨大的挑战。如果不全量统计,可能无法甄别出热 key
- 缺乏全局视图。如果客户端分布较广,无法从全局视角判断热 key
- 额外的开发成本。每种语言都要开发自己的 SDK
聚合服务收集
客户端将访问的 key 上报到聚合服务,由聚合服务统计出热 key
目前,有赞自研分布式缓存系统 zanKV、京东零售开源的热 key 探测框架(JD-hotkey)、得物热点探测框架(Burning)都是类似这种方案
存在问题
- 额外的开发成本。每种语言都要开发自己的 SDK
- 运维成本高。需要额外维护聚合服务的正常运行。同时可能会出现因聚合服务不可用,导致业务服务不可用的情况
Redis 源码改造
改造 Redis 源码,加入热点探测功能。对业务无侵入
存在问题
成本高,需要对 Redis 的源码开发
其他
当读取到 Redis 的 key-value 信息后,就直接写入到 JVM 缓存,但整体缓存命中率偏低
还可以凭经验主动预热,不过实时性差
解决热 key
热 key 的终极解决方案——本地缓存
我们再来想想热 key 会有什么危害?实际上就是短时间内大规模的请求访问到少数的 Redis 节点,Redis 因为无法承载这么大的流量,导致响应速度变慢甚至被打挂。那 Redis 自身无法承载这么大的流量,就干脆不向 Redis 发送请求不就好了?我们直接将数据缓存到本地。之后我们想获取数据,直接从本地缓存获取,不用再去访问 Redis 了,这样就彻底避免了热 key 对 Redis 的影响,因为请求都没发送出去,就被客户端自己“消化”了
同时,本地缓存的读写性能比读写 Redis 性能更高。虽然 Redis 很快了,但 JVM 中的本地缓存更快。譬如有 1000 台服务器,某 key 所在的 Redis 集群能支撑 20 万/s 的访问,那么平均每台机器每秒大概能访问该 key 200 次,超过的部分就会进入等待。由于 Redis 的瓶颈,将极大地限制 Server 的性能。
Java 客户端发送给 Redis,需要经历序列化/反序列化、网络传输、压缩/解压缩,还受带宽限制。而在 JVM 中直接缓存的就是对象本身,所以可以避免序列化和压缩,也不需要在 JVM 与 Redis 进行网络通讯,进一步降低了带宽,顺带解决了大 key 占用大量网络带宽而导致 Redis 吞吐量无法上去的问题
本地缓存既降低了 Redis 的访问压力,还带来了更高的性能。一石二鸟。不过这里还存在些问题需要解决
需要解决的问题
- 内存:客户端的内存是有限的,我们肯定不能将全量的 key 存储到客户端中,而只将真正热门的 key 缓存到本地。即,用有限的本地内存,响应尽可能多的请求
- 实时性:热 key 往往是突发的,不可预知的。如果短时间内没能进到内存,就有 Redis 集群被打爆的风险。如何在极短时间内快速统计出热 key?
- 数据一致性:前置在应用层的本地缓存,各个客户端之间相互独立,如何保障客户端与分布式缓存系统的数据一致性?
- 高性能:高性能带来的就是低成本,做热 key 探测目的就是为了降低数据层的负载,提升应用层的性能,节省服务器资源。理论上,在不影响实时性的情况下,要完成实时热 key 探测,所消耗的机器资源越少,那么经济价值就越大。
大厂落地方案
对于热 key 的解决方案,核心在于:通过热点检测算法统计 TopK,并将其设置为本地缓存。通过访问 JVM 当中缓存的数据,而不是访问 Redis,从而避免了热 key 对 Redis 的影响
接下来让我们看看,大厂是如何解决热 key 问题的?
篇幅有限,只能简单介绍。具体实现原理建议阅读原文
京东
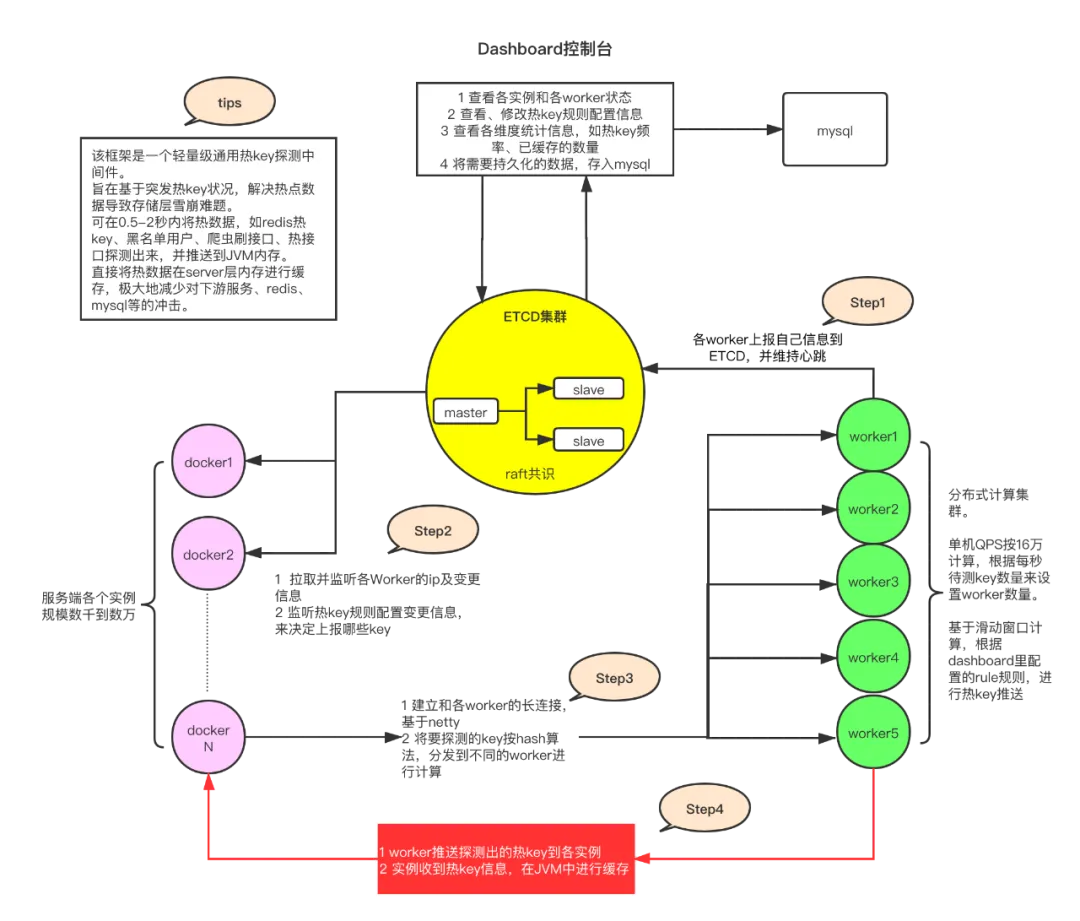
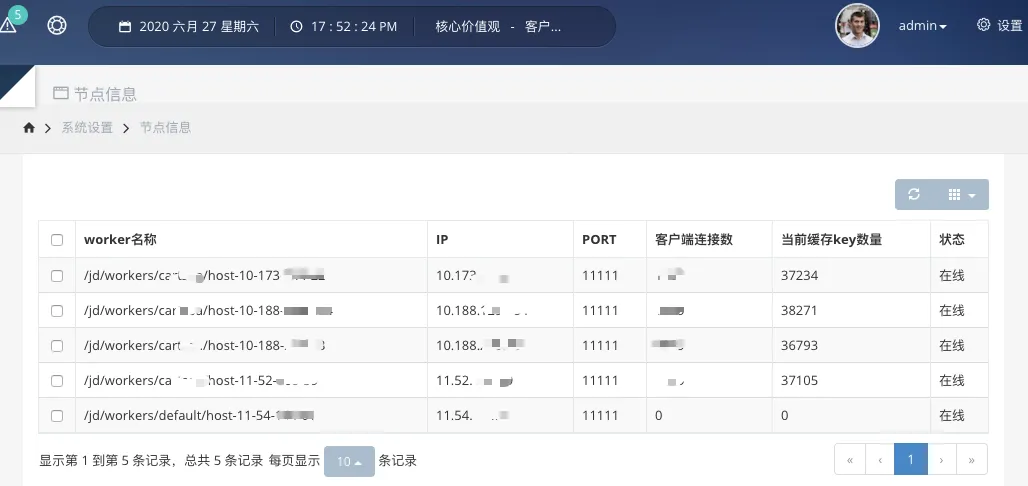
部署 Worker 集群,收集客户端异步上传的 key,滑动窗口统计 TopK,辨别热 key,将其推送给客户端的本地缓存中。
之后客户端可以直接通过本地缓存获取数据,从而避免了对 Redis 的访问,解决了热 key 对 Redis 的影响
原文地址:京东毫秒级热 key 探测框架设计与实践,已实战于 618 大促
同时,有赞也采用类似的方式统计热 key:有赞透明多级缓存解决方案(TMC)
热点检测
- 分布式计算:框架中的 worker 端集群负责对来自各个客户端的待测 key 进行累加计算。当某个 key 的访问频率达到了预设的阈值(例如,在 2 秒内出现了 20 次),该 key 就会被认定为热 key。主要依赖「滑动窗口」实现对热 key 的统计
- 规则配置:通过 etcd 集群存储规则配置信息,这些规则定义了什么条件下一个 key 被认为是热 key。比如,对于以
userId_或skuId_开头的 key,可以设置不同的时间窗口和出现次数作为判断热 key 的标准。 - 实时性保障:为了确保及时发现热 key,默认情况下,框架可以在 500 毫秒内完成对热 key 的探测,并将结果推送到所有相关的客户端内存中。
- 集群一致性:一旦某个 worker 发现了热 key,它会立即推送这个信息给所有的客户端以及更新到 etcd 中,保证整个集群内的所有节点都能同步获取最新的热 key 状态。
本地缓存
- 推送至 JVM 内存:一旦确定了热 key,这些信息会被推送到所有服务端的 JVM 内存中,以减轻后端存储层的压力。
- 过期策略:每个热 key 都会根据最初设定的规则配有相应的过期时间。这意味着即使一个 key 曾经是热 key,如果它的热度下降了,那么它也会从本地缓存中自动移除。
- 动态更新:当 dashboard 控制台手工添加或删除热 key 时,这些更改会被推送到 etcd,并由所有客户端监听并相应地更新它们的本地缓存。
- 避免重复发送:已经识别为热 key 的数据不会再次被发送回 worker 进行评估,除非本地缓存已过期。这减少了不必要的网络传输开销。
特性
- 高并发处理:单机 QPS 15 万
- 实时性:能够在极短时间内完成热 key 的探测与推送,适用于需要快速响应的场景,如抢购活动
- 性能优化:采用 protobuf 序列化提升了性能表现,CPU 使用率维持在较低水平。同时,使用 UDP 协议和异步批量上报,提高性能并降低网络带宽的影响
- 架构优势:worker 和 client 之间通过长连接通信,保证了低延迟的数据传递;使用 etcd 作为配置中心,利用其过期删除特性管理热 key 生命周期。
缺陷
引入额外的 worker 节点和 etcd 配置中心增加了系统的复杂度,运维带来了额外的挑战。
得物
改造 Redis 内核实现的热 key 统计方案
原文地址:基于 Redis 内核的热 key 统计实现方案|得物技术
热点检测
- LRU 队列:在 Redis-server 端使用固定大小的 LRU 队列来统计每个 key 的访问次数。这个队列记录了数据结构,能够以非常紧凑的格式设计,确保高效统计的同时不消耗过多内存资源
- 时间周期:热 key 统计默认以每秒为一个周期,统计每个 key 在每秒内的访问次数。当访问次数达到预设阈值时,key 被判定为热 key
区分读写操作:热 key 统计会区分读和写操作,这有助于业务进行更细致的缓存或其他处理 - 通知与订阅:提供了热 key 订阅与主动通知功能,通过三个订阅通道(读热 key、写热 key、热 key 失效)广播热 key 消息给客户端或代理

本地缓存
客户端订阅热 key 消息,及时将热 key 更新到本地缓存。当某个 key 失效时,将对应的缓存删除,保证数据的一致性
特性
- 实时性强:统计粒度为每秒,可以实时获取热 key 信息
- 非侵入式:基于 Redis 内核实现,无需修改客户端代码
- 低开销:利用紧凑的数据结构和 LRU 队列,保证了较低的内存消耗
- 支持订阅与查询:提供热 key 日志记录查询与重置命令,便于管理和监控
缺陷
需要修改 Redis 源码,开发和维护成本高
b 站
在客户端中实现的热点检测算法。使用有限的内存较为准确地统计出热 key
原文地址:热点检测治理
热点检测
使用 HeavyKeeper 算法,仅使用几 MB 内存就可以高效统计流数据的 TopK
当计数值越大时,衰减概率越低,可以保证低频元素被快速剔除,同时保证高频元素较低的衰减概率从而保证频次的精确度
传统统计 TopK 算法
HashMap + 堆排序。在大规模的流数据下将占用非常大的内存
HeavyKeeper 算法
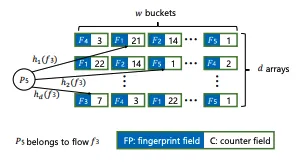
有点点类似布隆过滤器的思想:允许一定的哈希冲突,牺牲一定的准确性,换取时间和空间
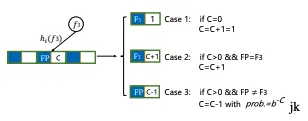
HeavyKeeper 的数据结构保存了一个哈希指纹和一个计数值,使用多个独立的哈希函数将输入元素映射到二维数组的不同位置。每个元素会通过所有哈希函数被映射多次,并更新对应位置的计数值
为了更好地应对突发热点,引入了时间衰减机制。这意味着随着时间推移,所有元素的历史频次都会逐渐减少,从而使得新出现的热点能够更快地被识别出来
HeavyKeeper 使用最小堆来跟踪前 k 个最频繁的元素。每当一个新的元素到来时,如果它的估计频次超过了堆顶元素,则替换掉堆顶元素。这样可以确保始终维持最新的 top-k 列表
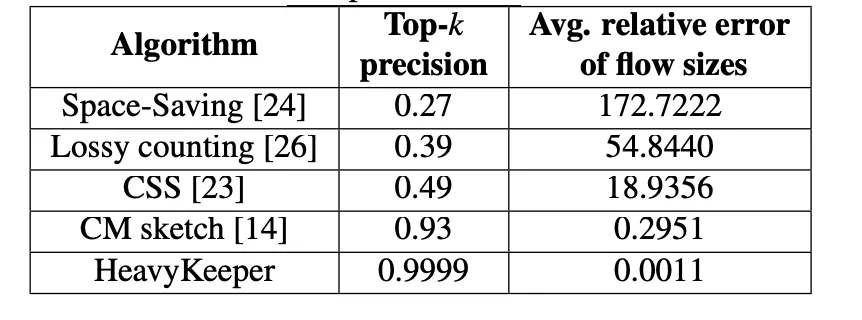
本地缓存
- 采用 LRU 算法,判断其是否为热点元素,只有当它是热点时才会被添加到 LRU 中,这样可以避免低频请求占用宝贵的缓存空间
- 缓存白名单。对于可以预见的热点事件(如特定活动),提前将相关 ID 加入白名单,一旦这些 ID 被访问到,就会立即加入本地缓存,而无需等待热点检测模块的确认
特性
- 接入成本低。只需对 Redis 客户端 SDK 改造,无需修改 Redis 源码、无需部署单独的热 key 统计 Server
- 仅使用几 M 内存的情况下日常高峰期的本地缓存命中率达到 35%
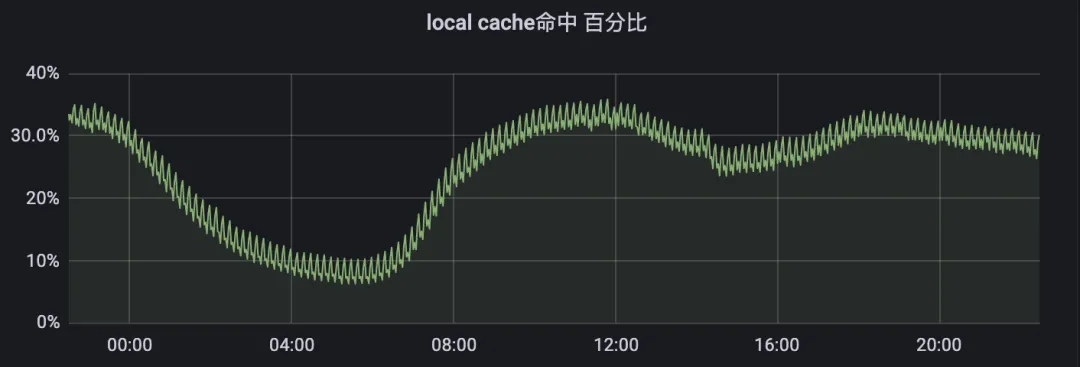
缺陷
如果服务器比较多,存在用户请求被分散的情况,本地计算达不到甄别出热 key。比如有 1000 台机器,刷子用户每秒请求 1000 次,通过负载均衡,每台服务器实际才被访问 1 次,不足以判定为热 key
结语
热 key 的解决方案无非就是「热点检测 + 本地缓存」
难点在于「热点检测」。京东用的是单独的 Worker 集群专门用来统计热 key,得物是在 Redis 内核中统计,b 站是在客户端中统计
如果大家感觉有帮助,欢迎点赞收藏+关注,有问题可以在评论区评论哦!
公众号【牛肉烧烤屋】
B 站【爱烤猪蹄的乔治】
参考资料
https://mp.weixin.qq.com/s/xOzEj5HtCeh_ezHDPHw6Jw
https://mp.weixin.qq.com/s/5JPF-7UYQvntMhUuGeOosg
https://mp.weixin.qq.com/s?__biz=MzkxNTE3ODU0NA==&mid=2247535...


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。