
原创 PowerData叶翔 PowerData

producer核心流程
一个Producer客户端由两个线程协调运行,主线程和Sender线程。

- 主线程中由 KafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。注:这里的消息拦截器可以在发消息的之前对数据进行预处理,因此没有必要存在。
RecordAccumulator主要用来缓存消息以便 Sender线程可以批量发送,进而减少网络传输的资源消息以提升性能。RecordAccumulator缓存的大小可以通过生产者客户端参数buffer.memory配置,默认值为 32M。如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候 KafkaProducer.send()方法调用被阻塞,要么抛出异常,这个取决于参数max.block.ms的配置,此参数的默认值为 60000,即 60秒。
主线程中发送过来的消息会迫加到 RecordAccumulator的某个双端队列(Deque)中,RecordAccumulator内部为每个分区都维护了一个双端队列,即 Deque< ProducerBatch >。消息写入缓存时,追加到双端队列的尾部;
ProducerBatch大小和 batch.size参数也有关系。当一条消息(ProducerRecord)流入RecordAccumulator时,会先寻找与消息分区所对应的双端队列(如果没有则新建),再从这个双端队列的尾部获取一个 ProducerBatch(如果没则新建),查看 ProducerBath中是否还可以写入这个 ProducerRecord,如果可以写入就写入,如果不可以就需要新创建一个ProducerBatch。在新建的 ProducerBatch时评估这条消息的大小是否超过 batch.size,如果不超过,那么就以batch.size参数的大小来创建 ProducerBatch,否则以消息大小创建。
Sender读取消息时,从双端队列的头部读取。注意:ProduceBatch是指一个消息批次;与此同时,会将较小的Producer凑成一个较大的 ProducerBatch,也可以减少网络请求的次数以提升整体的吞吐量。
如果生产者需要向多个分区发送消息,可以将 buffer.memory参数适当调大以增加整体的吞吐量。(对于 batch.size大小设置影响在参数讲解中分析)
Sender 从 RecordAccumulator 获取缓存的消息之后 ,会进 一步将 <分区,Deque< ProducerBatch >>的形式转变为<Node,List< ProducerBatch >>的形式,其中Node表示 Kafka集群 broker节点。对于网络连接来说,生产者是与具体 broker节点建立连接,也就是向具体的 broker节点发送消息,而不关心消息属于哪一个分区,而对于KafkaProducer的应用逻辑而言,我们只关心向那个分区中发送哪些消息,所以这里需要做一个应用逻辑层面到网络 I/O层面的转换。在转换成<Node,List< Producer >>的形式之后,Sender会进一步封装成<Node,Request>的形式,这样就可以将 Request请求发送各个 Node了,这里的 Request是 Kafka各种协议请求;
注: 这里需要用到集群中的元数据信息,通过元数据信息,建立这种映射关系。bootstrap-driver表示一台机器就可以了,每台机器都有集群中的完整元数据,通过元数据就知道消息应该发生给哪个机器。
- 注:当然有的时候,我们需要维护消息发送的顺序,那么这个时候需要设置 InFlightRequests的大小为 1来维持,因为消息只能按顺序接收后,下一条消息才能发送。
Producer初始化
org.apache.kafka.clients.producer.KafkaProducer
- 构造一个KafkaProducer,其中比较基本的初始化包括:
配置一些用户自定义的参数:

配置客户端ID:

配置Metrics,用于指标监控, 注:其实这里同flink一样,Metrics用于指标监控,在分析源码的时候可以忽略不计
设置分区器

配置一些默认参数,这里只列举部分,Metadata表示元数据对象,用于存储元数据信息:
- retry.backoff.ms:表示两次重试之间的时间间隔,设置合理值,可以避免无效的频繁重试。
- metadata.max.age.ms:设置配置的元数据的过期时间,默认值为300000ms,即5分钟,表示,在5分钟内,元数据没有被更新时,会被强制进行更新。
- max.request.size:表示生产者能发送的消息的最大值,默认为1048576B,即1MB。此参数最好不要随意修改,因为还涉及一些和其他参数的联动,比如和broker端message.max.bytes参数,配合使用来限制消息的大小。
- buffer.memory:用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。

设置序列化器

设置拦截器,类似过滤器

KafkaProducer中相对比较重要的初始化组件:
创建
RecordAccumulator

创建消息累加器后,去更新元数据信息 注:这里的更新,实际上是绑定MetaData和Cluster,初始化的时候,MeatData并没有和Kafka集群绑定

初始化NetworkClient,
- connections.max.idle.ms:一次网络连接最多空闲多级,超过这个空闲时间,就关闭这个网络连接。默认值是9分钟。
- max.in.flight.requests.per.connection:从producer发送消息到broker的时候,其实有多个网络连接。每个网络连接可以忍受Producer 端发送给broker消息,但是消息没有响应的个数。因为kafka有消息重试机制,所以有可能会造成数据乱序,如果想要保证有序,这个值设置为1。
- send.buffer.bytes:socket发送数据的缓存区的大小,默认值是128K。
- receive.buffer.bytes:socket接收数据的缓冲区的大小,默认值是32K。

初始化并开启Sender线程,Sender implements Runnable,并不是执行继承了Thread,核心目的是为了把业务代码和线程代码隔离开,对于两者之间的区别,参考:https://blog.csdn.net/zhaojia...
- retries:重试的次数
acks:0:producer发送数据到broker后,就完了,没有返回值,不管写成功还是写失败都不管了。1:producer发送数据到broker后,数据成功写入leader partition以后返回响应。但是其他副本节点宕机,有可能无法成功保存数据。-1:producer发送数据到broker后,数据要写入到leader partition里面,并且数据同步到所有的follower partition里面以后,才返回响应。这个方式可以保证数据不丢失。

代码中,使用KafkaThread是可以设置为守护进程,继承了Thread

Producer端的元数据管理
- 元数据对象
Metadata属性分析:A class encapsulating some of the logic around metadata. org.apache.kafka.clients.Metadata
- refreshBackoffMs:两次更新元数据请求的最小的时间间隔,默认值是100ms。目的是减少网络压力
- metadataExpireMs:多久自动更新一次元数据,默认值是5分钟更新一次
- version:对于producer端来讲,元数据是有版本号的,每次更新元数据,都会更新版本号
- lastRefreshMs:上一次更新元数据的时间
- lastSuccessfulRefreshMs:上一次成功更新元数据的时间;正常情况下,如果每次更新都是成功的,那么lastRefreshMs和lastSuccessfulRefreshMs应该是相同的
- cluster:Kafka集群的信息,可以理解为集群本身的元数据信息
- needUpdate:这是一个标识,用来判断是否更新元数据的标识之一
- topics:记录已有的topics
listener:用于定义 Kafka Broker 监听客户端连接的网络地址、端口和通信协议

- Kafka集群类,
ClusterA representation of a subset of the nodes, topics, and partitions in the Kafka cluster. org.apache.kafka.common.Cluster
- List< Node > nodes:Kafka节点信息
- unauthorizedTopics:没有授权的topic

为了性能,在这里封装了一些和分区相关的冗余信息
- partitionsByTopicPartition:代表的事一个partition和partition对应的信息;
- partitionsByTopic:一个topic对象有哪些副本
- availablePartitionsByTopic:一个topic对应有哪些可以用的partition
- partitionsByNode:一台服务器上面有哪些partition(服务器用的是服务器的变化)
- nodesById:服务器和服务器编号的关系,之前安装kafka集群的时候,需要再配置文件中修改- Kafka上一个节点的信息,
NodeInformation about a Kafka node org.apache.kafka.common.Node
- id:ID编号,这个编号是我们配置参数的时候指定的
- host:主机名
- port:端口号,9092
- rack:机架

- topic和分区的关系,
TopicPartitionA topic name and partition number,用于表示一个topic和一个特定分区之间的关系,例如,要读取 "test\_topic" 主题的某一个分区。org.apache.kafka.common.TopicPartition

- 一个Topic的分区信息,
PartitionInfoInformation about a topic-partition,获取主题的元数据信息,包括分区数量、每个分区的 ISR 列表和领导者等 org.apache.kafka.common.PartitionInfo
- topic:主题
- partition:分区编号
- leader:Leader节点信息
- replicas:这个分区的所有replica在哪些节点
- inSyncReplicas:ISR列表

Producer核心流程概述
以为kafka.examples.Producer例,异步调用send方法

执行后,调用org.apache.kafka.clients.producer.KafkaProducer的doSend()方法,核心流程如下:
- 同步等待,拉取元数据
- maxBlockTimeMs:最长等待时间
- this.maxBlockTimeMs - waitedOnMetadataMs:还剩余多长时间可以使用

- 对消息的key和value进行序列化

- 根据分区器选择消费应该发送的分区

- 确认消息的大小是否超过了最大值,默认是1M,实际使用过程会修改

- 根据元数据信息,封装分区对象

- 给每一条消息都绑定回调函数,因为样例中使用的是异步调用的方式

- 把消息放入
accumulator(32M),然后经过accumulator把消息封装为一个批次一个批次的去发送

- 如果批次满了,或者创建一个新的批次,
唤醒sender线程

一个不错的编程思路,异常捕获,为了能更直观的看到异常信息,kafka在doSend()方法中,将try{代码块}遇到的异常,通过catch的方式集中处理ensureValidRecordSize()遇到的异常,通过自定义RecordTooLargeException抛给doSend()方法处理

Producer加载元数据
org.apache.kafka.clients.producer.KafkaProducer
整体流程图解:

waitOnMetadata():Wait for cluster metadata including partitions for the given topic to be available.
- 如果
metadata中不存在当前Topic,把当前Topic存到元数据里面;metadata.fetch()返回cluster,集群信息,如果之前已经有这个Topic,那就直接返回0 注:第一次执行的时候,这里都是null

- 如果上面条件不成立,
这个时候就真正的去服务端拉取元数据543:获取当前元数据的版本,Producer在管理元数据的时候,每次成功更新元数据,都会递增版本号;元数据的needUpdate标识赋值为true 544:唤醒sender线程,拉取元数据的操作是由sender线程完成的。545:等待元数据的更新,如果超时,抛出异常,结束while循环546:elapsed,计算当前花费的时间 547~550:如果超时或者没有授权,抛出异常 551:remainingWaitMs,获取剩余时间 553:返回花费的时长

awaitUpdate():Wait for metadata update until the current version is larger than the last version we know of version:当前元数据的版本号,如果当前的这个version小于等于上一次的version,说明元数据还没有更新;sender线程更新完元数据,一定会回去累加这个version。129:wait(remainingWaitMs),如果在等待时间内没有被唤醒,则自己唤醒自己。131~132:同样地,因为不是核心流程,因此会捕获异常往上面抛,在doSend里面catch。

sender.wakeup();在获取元数据的时候,实际上底层调用的是Sender线程自定义的run(time)方法;
- 第一次获取元数据的时候,Cluster对象为null,下面的所有和send message的代码直接跳过执行

- 在代码的最后一行,才是去拉取集群元数据

- Producer初始化时候创建的NetworkClient负责具体获取集群元数据 org.apache.kafka.clients.NetworkClient 258:封装了一个拉取集群元数据的请求,去获取元数据信息
260:发送请求,进行复杂的网络IO操作,这块目前先跳过\=发送网络请求

maybeUpdate():封装一个请求,用于拉取Cluster的元数据信息;这里的doSend()方法仍然没有发生请求,二是将请求存储起来,真正发还是通过selector.poll()实现注:继续追踪这里的doSend()方法,Queue the given request for sending in the subsequent,实际上相当于在org.apache.kafka.common.network.KafkaChannel中setSend(),并不是真正的send()

- 根据request,判断请求类型,处理关于元数据的响应

- 将返回的信息封装成
MetaDataResponse,并把Cluster相关元数据信息填充,标黄的部分真正的去更新元数据,update()方法里面的notifyAll();会唤醒之前处于wait状态的主线程,version+1

Producer分区器选择
org.apache.kafka.clients.producer.internals.DefaultPartitioner
- 分区策略:
- 如果消息没有键,则使用轮询策略将消息均匀地发送到可用分区中
- 如果消息包含键,则使用哈希函数根据键来选择分区
注:使用key,可以理解为提前在数据存储的时候就做了一次聚合

7、Producer的RecordAccumulator
org.apache.kafka.clients.producer.internals.RecordAccumulatorkafka生产者内存池可以参考一下:https://blog.csdn.net/CSDNgao...
- check if we have an in-progress batch。一开始这里肯定是需要创建一个队列,但是append肯定会失败,因为这里没有分配内存。

- we don't have an in-progress record batch
try to allocate a new batch。根据数据大小或者默认批次大小(16K)去分配内存

数据池里面的批次buffer没有分配给dq,这里写的到dq里面仍然会失败,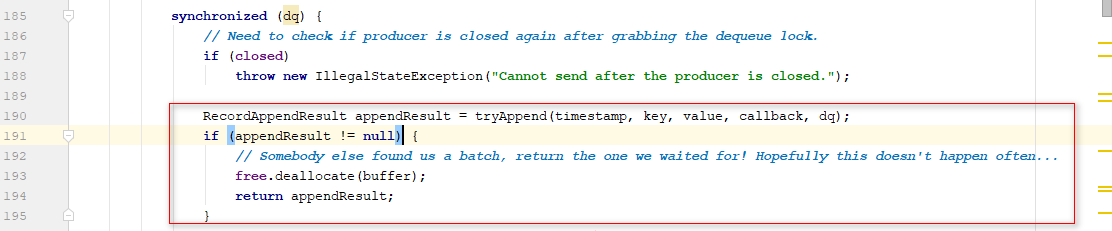- 根据内存大小封装
RecordBatch,Deque< RecordBatch > dq把batch添加到队尾

private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches;集中管理kafka中的分区队列,使用的数据结构是CopyOnWriteMap,
- 读数据:每生产一条消息,都会从batches里面读取数据,假如每秒中生产10万条消息,意味着每秒要读取10万次
- 写数据:假如有100个分区,那么会插入100次数据,并且队列只需要插入一次就可以了。这是一个低频的操作。
核心看一下里面的put()和get()方法CopyOnWriteMap:A simple read-optimized map implementation that synchronizes only writes and does a full copy on each modification.
- put()方法,每次插入的时候都会开辟新的内存空间,缺点,插入数据的时候,会耗费内存空间。

- get()方法,不加锁

分段加锁机制,假定现在有两个线程,线程一、线程二:
- 线程1和线程2分别进入,都不会产生把Batch添加成功,因为没有分配内存,到位置5的时候才会添加成功
- 尝试申请内存
- 再次加锁,尝试把key和value写入到Batch
- 释放申请的内存,因为是多线程,放在内存空间申请没有释放
- 初次产生Batch的时候,通过这种方式加入队列中

BufferPool:用来给每个Batch分配内存大小 org.apache.kafka.clients.producer.internals.BufferPool
- 如果申请的大小等于
poolableSize(默认配置为16KB),那就直接返回队列里面的空闲内存块ByteBuffer

- 如果目前可用总内存大于要申请的内存,进行内存扣减,直接分配内存,

- 如果申请的内存不够,位置1等待其他的
Batch被释放,位置2循环分配内存

当有内存被是否的时候,会唤醒这个线程

当内存池的内存大小还是不够的时候,会继续从availableMemory扣减内存

- 释放内存的时候,如果释放的大小=
poolableSize,则放入内存池,否则放入availableMemory,目的是为了防止产生内存碎片

Producer的sender线程
org.apache.kafka.clients.producer.internals.Sender
- 获取kafka集群的元数据信息;根据元数据信息,判断对于分区的数据应该发送到哪个集群

如果>0,表示内存池的内存不够用

307行,遍历所有的分区 308行,获取到分区 309行,获取分区对应的队列 310行:根据分区,获取到这个分区的Leader Partition是在那一台机器上

获取Deque<RecordBatch>首部的RecordBatch, backingOff:是否到了重新发送数据的时间 waitedTimeMs:这个批次已经等待时间 lingerMs:限定时间,到时间就发送,默认值是0,表示来一条消息就发送, timeToWaitMs:最多能等到多久 timeLeftMs:剩下等到时间
- attempts:重试的次数
- lastAttemptMs:上一次重试的时间
- retryBackoffMs:重新发送数据的时间间隔
- nowMs:当前时间
kafka发送消息的策略 1、expired:过期,到了发送消息的时间 2、full:是否已经写满了批次(无论时间是否到了) 3、exhausted:内存不够(消息发送出去以后,就会释放内存) 4、closed:关闭生产者线程,发送完成缓存数据

- 标识无法获取到Partition的对应的Leader信息

- 检查与要发送数据的broker是否已经建立好联系

org.apache.kafka.clients.NetworkClient可以发送消息的条件:1、发送消息的时候元数据没有更新 2、缓存里面的连接(个数同broker节点)是否已经建立好, 3、selector相当于java NIO中的selector,一个KafkaChannel就代表了一个连接。4、是否在可以最多容忍发送的消息没有收到响应的个数范围内

可以建立连接的条件:1、state==null,表示当前没有建立连接 2、state.state == ConnectionState.DISCONNECTED,当前连接状态处于未连接

将<Topic分区,Deque< RecordBatch>>转变为<broker,List< RecordBatch >>假定发送的Partition有很多个,则可能存在不同分的Partition是在一台机器上,这种方式可以减少请求的数量;

- 放弃超时的Batch

- 创建发送消息的请求

- 真正执行网络操作的都是
NetWorkClient这个组件,包括:发送请求,处理响应

Producer的NetworkClient
org.apache.kafka.clients.NetworkClient,本质上是Java中的NIO编程部分,
与Broker建立连接,本质上是SocketChannel的建立连接过程
org.apache.kafka.common.network.Selector:封装了java NIO中的SelectornioSelector:java NIO里面的Selector,负责网络的建立,发送网络请求,处理实际的网络IO。channels:broker和KafkaChannel的映射,KafkaChannel类似SocketChannel,代表一个网络连接 completedSends:已经完成发送的请求 completedReceives:已经接收到的,并且处理完了的响应 stagedReceives:已经接收到了,但是没来得及处理的响应 disconnected:没有建立连接的主机 connected:完成建立的主机 failedSends:建立连接失败的主机

Selector的connect()方法 Begin connecting to the given address and add the connection to this nioSelector associated with the given id number. 获取一个SocketChannel,设置为非阻塞模式,发送消息和接收消息的Buffer大小socket.setTcpNoDelay(true),这个值默认是false,代表要开启Nagle算法,即组合网络中小包为大的数据包,然后再发送出去,因为网络中有大量的小包传输可能会导致网络阻塞,kafka中这里不能设置为false,因为数据包本身可能比较小,需要正常发送。

接下来,尝试连接服务器,socketChannel.connect(address):由于是非阻塞式的,这里可能马上成功,也可能要很久

SocketChannel向Selector上注册了一个OP_CONNECT

KafkaChannel:根据SocketChannel封装得到;然后将得到的key和KafkaChannel关联起来,后面使用起来会比较方便;最后将KafkaChannel和broker关联起来

最后,如果连接成功,key取消注册的OP_CONNECT,通常情况下,上面的连接是不成功的,因为上面是非阻塞的,生产这和broker不在一个机器上,执行到这里的时候,仍然没有连接成功

问题:什么时候真正连接成功?根据producer的例子驱动,this.client.poll(pollTimeout, now);,真正连接成功的位置在Selector的pollSelectionKeys()方法中,首先根据key找到Channel

完成连接后,就把这个Channel.id存储到this.connected

建立网络连接后,生产者开始发送网络请求在Java NIO中,如果需要使用NIO去发送请求,或读取响应,那么需要往Selector上绑定下面两个事件:SelectionKey.OP\_WRITE:写数据,发送网络请求 SelectionKey.OP\_READ:读取数据,接受响应
PlaintextTransportLayer注册READ事件,SelectionKey.OP_READorg.apache.kafka.common.network.PlaintextTransportLayer

- Sender的run方中,
client.send(request, now);循环遍历,但是这里只是标记为OP\_WRITE事件,并没有送请求, 在NetworkClient的doSend()中,inFlightRequests这个角色开始出现,他在这里缓存了我们正在发送的请求,

在KafkaChannel中,为这个请求注册SelectionKey.OP_WRITE事件
SelectionKey.OP_WRITE区分操作方式,最终在KafkaChannel中的send()方法中发送请求,完成后删除OP_WRITE,

网络编程中经典问题,如何处理粘包和拆包?注:什么是TCP的“粘包”和“拆包”?如何解决?org.apache.kafka.common.network.NetworkReceive,readFromReadableChannel()
- 粘包问题 1:读取指定字节大小(默认4个字节)的数据,表示后面消息的字节数 2:分配一个内存空间,即刚刚读取的内存空间的大小 3:去读取数据到刚刚分配的内存空间
- 拆包问题 4:判断申请的4字节的空间是否都满,都满则执行5, 5:如果读满,就同样分配内存空间,知道内存空间都满

核心点:判断4字节空间和真正存储消息的空间是否已满

如何处理暂存状态的响应,staged receives?
- 添加接收到的响应到指定Channel中的队列中
private final Map<KafkaChannel, Deque<NetworkReceive>> stagedReceives;

- 把队列中的响应封装到
private final List<NetworkReceive> completedReceives;

org.apache.kafka.clients.NetworkClient最终处理接收到的响应消息

ClientResponse由body,存储的事响应的内容和req,发送出去的哪个请求信息,并

- 调用响应里面对应请求的回调函数

-->回调函数的定义在Sender的produceRequest()中,Create a produce request from the given record batches

handleProduceResponse()请求的回调函数response.wasDisconnected()是发送请求,但是发现broker失去了连接,小概率事件

位置1:从节点的响应转变为分区的响应位置2:生产环境下,一般不会把acks设置为0, 注:completeBatch()如果这里响应消息异常,会调用this.accumulator.reenqueue(batch, now);重新发送消息

- 位置1,找到响应所对应发送的一系列消息
Thunk;位置2调用我们在编写生产者生产消息时候定义的回调函数,如果出现异常 org.apache.kafka.clients.producer.internals.RecordBatch

具体回调函数的的传入,参考kafka.examples.Producer:

**消息发送完成,内存如何处理?**(自定义回调函数已经回调,说明完成整个消息发送,成功处理响应) org.apache.kafka.clients.producer.internals.BufferPool
- 内存回收策略:
RecordAccumulator已经说过,这里略 - 唤醒等待分配内存的线程


问题:如何处理超时发送的批次?
- 判断超时的条件,
org.apache.kafka.clients.producer.internals.RecordBatchrequestTimeoutMs:请求发送的超时时间,默认值是30S now:当前时间 lastAppendTime:批次创建的时间,或者上一次重试的时间 lingerMs:形成批次的最长时间,超过就发送消息 createdMs:批次创建的时间 retryBackoffMs:重试的时间间隔 最后调用done()方法,抛出异常,用户可以通过自定义的回调函数处理异常

- 对超时的Batch,还是会回收内存,释放资源,后期重试

问题:如何处理长时间没有响应的消息?
- 关闭请求超时的连接,关闭连接状态,
org.apache.kafka.clients.NetworkClient

- 连接broker节点状态设置为
DISCONNECTED,可以重新尝试建立连接,org.apache.kafka.clients.ClusterConnectionStates

- 最后,
封装一条异常响应,disconnected=true,这种自定义响应的方式可以学习一下,最后仍然会在completeBatch()方法中处理

- 专注数据开源,推动大数据发展 -
我们是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的PowerData数据之力社区。
如果你也想要加入学习,可关注下方公众号后点击“加入我们”,与PowerData一起成长!

**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。