
Python的并发处理能力臭名昭著。先撇开线程以及GIL方面的问题不说,我觉得多线程问题的根源不在技术上而在于理念。大部分关于Pyhon线程和多进程的资料虽然都很不错,但却过于细节。这些资料讲的都是虎头蛇尾,到了真正实际使用的部分却草草结束了。
传统例子
在DDG https://duckduckgo.com/ 搜索“Python threading tutorial”关键字,结果基本上却都是相同的类+队列的示例。
标准线程多进程,生产者/消费者示例:
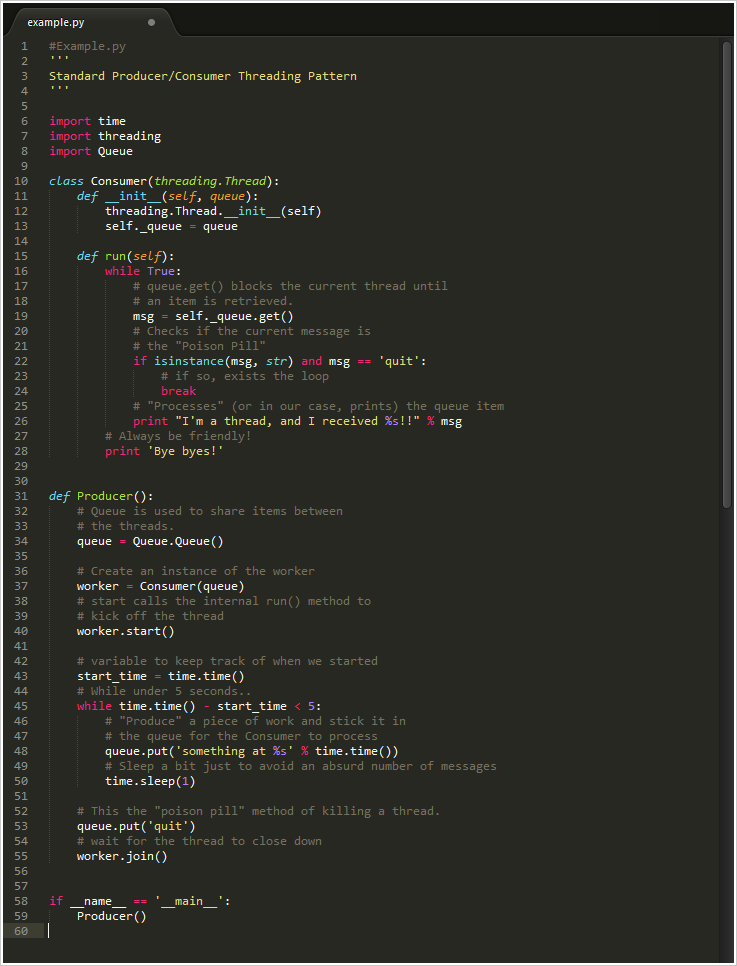
这里是代码截图,如果用其他模式贴出大段代码会很不美观。文本模式点这里 here
Mmm.. 感觉像是java代码
在此我不想印证采用生产者/消费者模式来处理线程/多进程是错误的— 确实没问题。实际上这也是解决很多问题的最佳选择。但是,我却不认为这是日常工作中常用的方式。
问题所在
一开始,你需要一个执行下面操作的铺垫类。接着,你需要创建一个传递对象的队列,并在队列两端实时监听以完成任务。(很有可能需要两个队列互相通信或者存储数据)
Worker越多,问题越大.
下一步,你可能会考虑把这些worker放入一个线程池一边提高Python的处理速度。下面是
IBM tutorial 上关于线程较好的示例代码。这是大家常用到的利用多线程处理web页面的场景
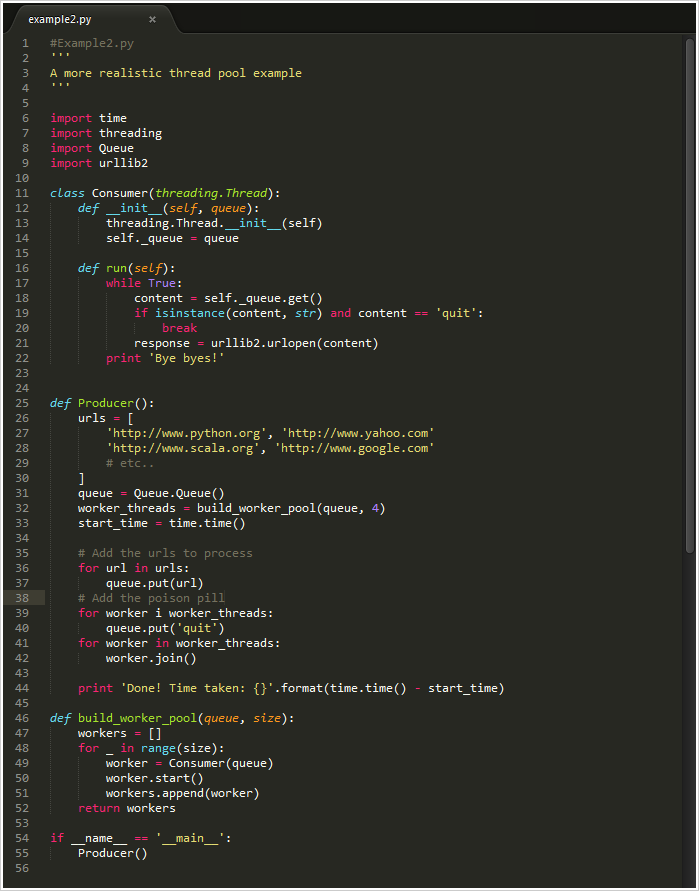
Seriously, Medium. Fix your code support. Code is Here.
感觉效果应该很好,但是看看这些代码!初始化方法、线程跟踪,最糟的是,如果你也和我一样是个容易犯死锁问题的人,这里的join语句就要出错了。这样就开始变得更加复杂了!
到现在为止都做了些什么?基本上没什么。上面的代码都是些基础功能,而且很容易出错。(天啊,我忘了写上在队列对象上调用task_done()方法(我懒得修复这个问题在重新截图)),这真是性价比太低。所幸的是,我们有更好的办法.
引入:Map
Map 是个很酷的小功能,也是简化Python并发代码的关键。对那些不太熟悉Map的来说,它有点类似Lisp.它就是序列化的功能映射功能. e.g.
urls = [', ']
results = map(urllib2.urlopen, urls)
这里调用urlopen方法,并把之前的调用结果全都返回并按顺序存储到一个集合中。这有点类似
results = []
for url in urls:
results.append(urllib2.urlopen(url))
Map能够处理集合按顺序遍历,最终将调用产生的结果保存在一个简单的集合当中。
为什么要提到它?因为在引入需要的包文件后,Map能大大简化并发的复杂度!
支持Map并发的包文件有两个:
Multiprocessing,还有少为人知的但却功能强大的子文件 multiprocessing.dummy. .
Digression这是啥东西?没听说过线程引用叫dummy的多进程包文件。我也是直到最近才知道。它在多进程的说明文档中也只被提到了一句。它的效果也只是让大家直到有这么个东西而已。这可真是营销的失误!
Dummy是一个多进程包的完整拷贝。唯一不同的是,多进程包使用进程,而dummy使用线程(自然也有Python本身的一些限制)。所以一个有的另一个也有。这样在两种模式间切换就十分简单,并且在判断框架调用时使用的是IO还是CPU模式非常有帮助。
准备开始
准备使用带有并发的map功能首先要导入相关包文件:
from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
然后初始化:
pool = ThreadPool()
就这么简单一句解决了example2.py中build_worker_pool的功能. 具体来讲,它首先创建一些有效的worker启动它并将其保存在一些变量中以便随时访问。
pool对象需要一些参数,但现在最紧要的就是:进程。它可以限定线程池中worker的数量。如果不填,它将采用系统的内核数作为初值。
一般情况下,如果你进行的是计算密集型多进程任务,内核越多意味着速度越快(当然这是有前提的)。但如果是涉及到网络计算方面,影响的因素就千差万别。所以最好还是能给出合适的线程池大小数。
pool = ThreadPool(4) # Sets the pool size to 4
如果运行的线程很多,频繁的切换线程会十分影响工作效率。所以最好还是能通过调试找出任务调度的时间平衡点。
好的,既然已经建好了线程池对象还有那些简单的并发内容。咱们就来重写一些example2.py中的url opener吧!
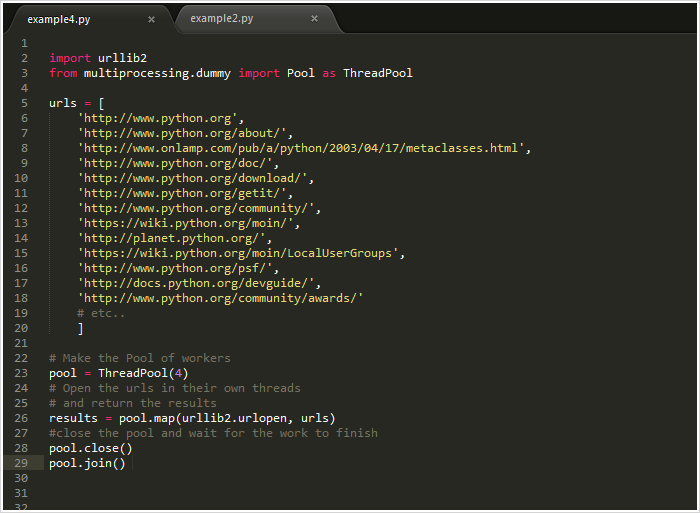
看吧!只用4行代码就搞定了!其中三行还是固定写法。使用map方法简单的搞定了之前需要40行代码做的事!为了增加趣味性,我分别统计了不同线程池大小的运行时间。
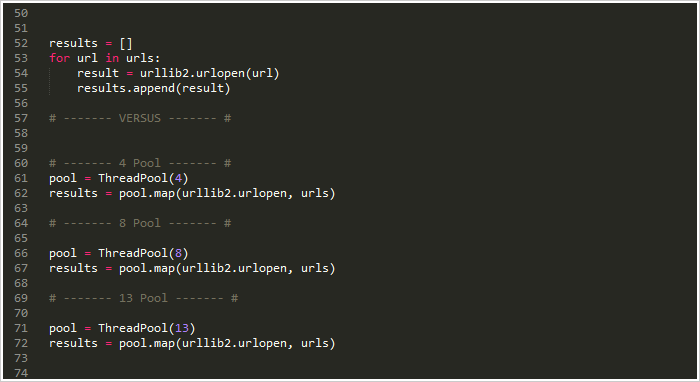
结果:
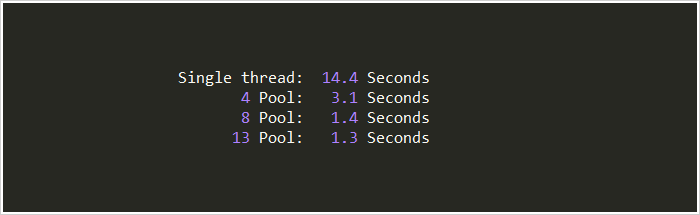
效果惊人!看来调试一下确实很有用。当线程池大小超过9以后,在我本机上的运行效果已相差无几。
示例 2:
生成上千张图像的缩略图:
现在咱们看一年计算密集型的任务!我最常遇到的这类问题之一就是大量图像文件夹的处理。
其中一项任务就是创建缩略图。这也是并发中比较成熟的一项功能了。
基础单线程创建过程
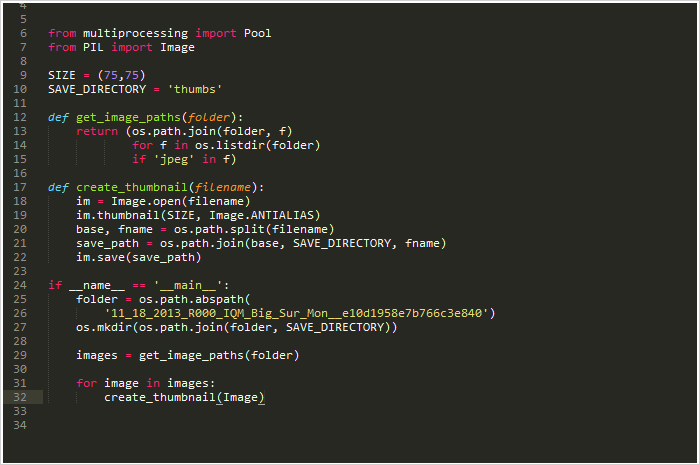
作为示例来说稍微有点复杂。但其实就是传一个文件夹目录进来,获取到里面所有的图片,分别创建好缩略图然后保存到各自的目录当中。
在我的电脑上,处理大约6000张图片大约耗时27.9秒.
如果使用并发map处理替代其中的for循环:
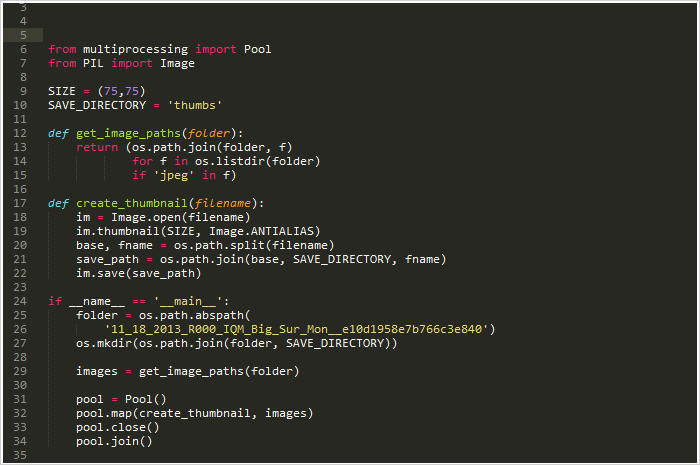
只用了5.6 秒!
就改了几行代码速度却能得到如此巨大的提升。最终版本的处理速度还要更快。因为我们将计算密集型与IO密集型任务分派到各自独立的线程和进程当中,这也许会容易造成死锁,但相对于map强劲的功能,通过简单的调试我们最终总能设计出优美、高可靠性的程序。就现在而言,也别无它法。
好了。来感受一下一行代码的并发程序吧。
原文:Parallelism in one line
转载自:开源中国 - petert







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。