
import.io,一个2012年成立的公司。至今已经有3m刀的...种子轮...为毛...
注意,这是一篇由脑残和图片组成的文章。

anyway,import.io是我用过最简单的爬虫,没有之一。简单到...只要输入一个网址(当然其实它可以更简单到不用输入http://),就可以获得一个该页面对应的API。更牛逼的是,这是一个我想寻找付费服务却寻觅不得的产品!
两步得到网站API
- 打开https://magic.import.io/ 输入要爬取的网址,比如http://producthunt.com
- 调整你需要的数据列,比如把url_link那列改为title
- 点击下面的GET API...
然后import.io就会给出一个GET API,一个POST API,甚至还有直接从Google sheets取数据的地址!

这个API足够足够简单吧!也不用[o]auth就直接拿数据!唯一可惜的一点是,似乎它有一些延迟,没法很实时获得数据(也正是这时候我开始满页面找pricing...)。
除了GET以外,你还可以往里拽(POST)其他URL,很适合那种同构的多页爬取。
当然,虽然你觉得Http GET已经足够简单了,但import.io不这么认为,它觉得你还是需要SDK的...好吧,其实我是为了展示他的API doc页面...里红色的那部分!想起了一个以前看到过别人分享的注释
//Attempt Handshake: Hello? This is London calling. Are we reaching you?
//Handshake Failed: I don't understand...he just hung up.
import.io不光是一个爬网页的平台,它还提供存储,搜索(是的...)等服务。赞一下里面的文档样式。

App
一个爬虫用的桌面App?想到了啥?像浏览器一样,圈圈点点?
从这里下载import.io的桌面应用,安装完了去桌面打开(谁知道为啥它不扔launcher里...),splash都cute到死...

打开以后呢,发现呢,就是个firefox内核的浏览器...区别就在与在这个app里可以使用chrome里无法使用的API from URL 2.0,API from Authenticated URL这些功能。估计就是为了把各种登陆cookie都很容易拿到,所以就做了个浏览器的壳吧。
用起来才发现这简直是...简直了...找到要爬的页面,鼠标选择要爬取的内容,搞定以后publish就可以产生一个某类页面的API了,以后只需要把新的文章URL扔给他就ok了。
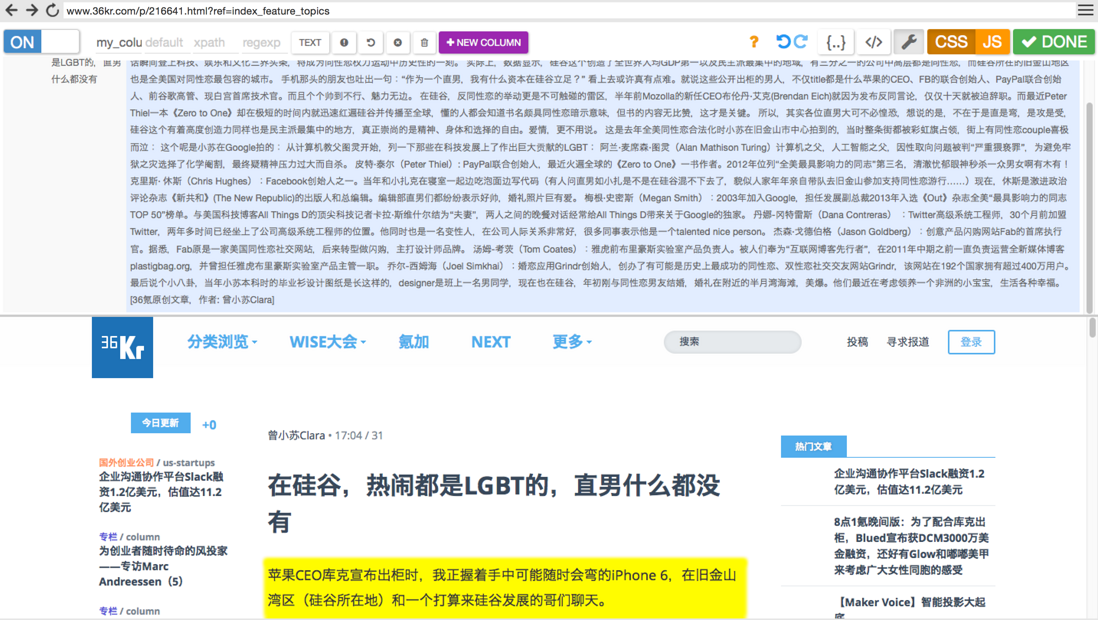
可以看出import.io其实没有diffbot那么智能,但对于那些懒得写xpath的程序员,import.io真的很方便!说到xpath,似乎我真的好久没写过了...可以看出import.io也是用xpath来实现的。

好啦,这篇真的是一行代码都没有(这完全是为了配合import.io的好用好吧)...好吧,我有姿势我自豪~

**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。