
这几天翻了翻SequoiaDB的代码,记了点笔记。不保证下面内容的正确性(肯定有错的地方)
个人观感
优点
1.代码还不错,设计也算简洁。
2.EDU和CB的使用让整个系统变得简单很多,让代码更关注逻辑。
3.从设计上应该就是一个分布式系统,麻雀虽小五脏俱全。
4.没用什么乱七八糟的东西改,基本是自己的代码(虽然支持SQL但是基本可以认为是通过Postgresql支持的)。
八卦&吐槽
1.八卦一下Sequoia这个名字,本意是红杉的意思,同时丰田有款车叫这个名字,还有那个著名的红杉资本。不知道有什么关系没有。
2.扫了一眼他们的招聘列表,居然没有招数据库开发的,不知道是数据库的人已经够了还是不打算搞了。
3.吐槽一下缩写,我实在无法从代码的缩写里分辨出含义来,比如bar这个文件夹,里面包含了barBackup和barRestore,难道bar = backup + restore? 问题是barrier情何以堪?ixm = index mananger?dps = Data Protection Service?PD=Problem Determination ? PMD = Process MoDel ? 又比如_extentInsertRecord的参数叫deletedRecordPtr, 而_extentRemoveRecord的参数叫做recordPtr
4.注释极少,基本上还是没有营养的重复一下类名什么的,也没有找到TODO之类,更关键的是注释基本都是用缩写表示,不排除开源版本特意把注释都删掉了。代码显得有点太干净了,干净的有点过了。
综述
关于整体介绍,要看官方文件(这份文件看起来有些原始,应该是不同时期不同人的文件堆积起来的,创业公司不能要求太高),如果只关注一个摘要的话,请参考这个ppt。
SequoiaDB 数据库是一款新型企业级分布式非关系型数据库,帮助企业用户降低 IT
成本,并对大数据的存储与分析提供了一个坚实,可靠,高效与灵活的底层平台。优势 • 通过非结构化存储与分布式处理,提供了近线性的水平扩张能力,让底层的存储不再成为瓶颈 •
提供了精确到分区级别的高可用性,预防服务器,机房故障以及人为错误,让数据24x7永远在线 •
提供了完善的企业级功能,让用户轻松管理高并发性任务,以及海量数据分析 •
增强的非关系型数据模型,帮助企业快速开发和部署应用程序,做到应用程序的随需应变 • 提供了最终一致性的保障,从根本上杜绝数据缺失 •
提供了在线应用与大数据分析的后台数据库的结合,通过读写分离机制做到同系统中数据分析与在线业 务互不干扰
系统架构
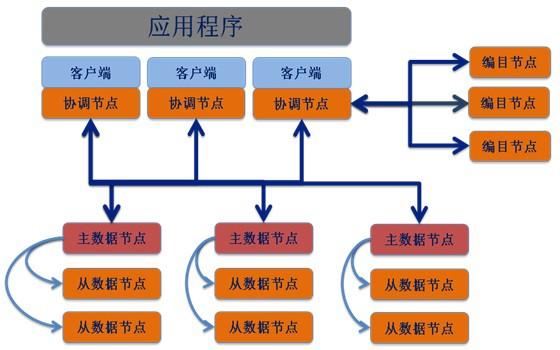
SequoiaDB 使用分布式架构,下图提供了对 SequoiaDB 体系结构的一般概述。
在客户机端(或应用程序端),本地或/和远程应用程序都与 SequoiaDB 客户机库链接。本地与远程客户机 使用 TCP/IP 协议与协调节点进行通讯。
协调节点不保存任何用户数据,仅作为请求分发节点将用户请求分发至相应的数据节点。 编目节点保存系统的元数据信息,协调节点通过与编目节点通讯从而了解数据在数据节点中的实际分布。一
个或多个编目节点可组成复制组集群。
数据节点保存用户的数据信息。一个或多个数据节点可以构成一个复制组(又称分区组)。复制组中每个数 据节点都存储该复制组的一份完整数据,又称为复制组实例(或分区组实例);复制组中的数据节点之间采 用最终一致性同步数据,不同的复制组中保存的数据无重复。
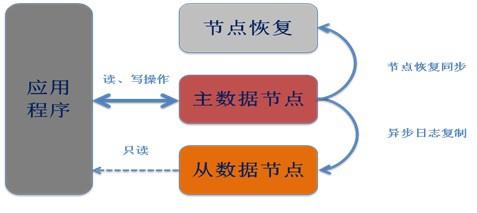
每个复制组中可以包含一个或多个数据节点。当存在多个数据节点时,节点间数据进行异步复制。复制组中 可以存在最多一个主节点与若干从节点。其中主节点可以进行读写操作,从节点进行只读操作
从节点离线不影响主节点的正常工作。主节点离线后会在从节点中自动选举出新的主节点处理写请求
节点恢复后,或新的节点加入复制组后会进行自动同步,保障数据在同步完成时与主节点一致。


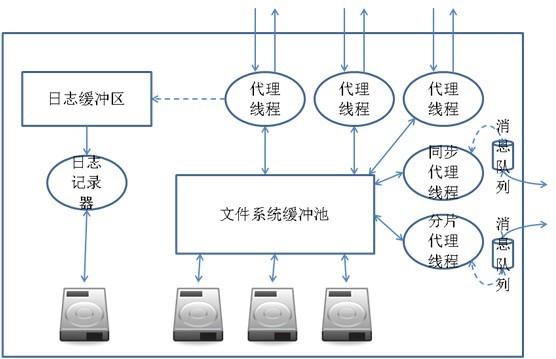
在单个数据节点中的体系结构如下:
在数据节点,活动由引擎可调度单元(EDU)控制。每一个节点为操作系统中的一个进程。每个 EDU 在节点 中为一个线程。对于外部用户请求其处理线程为代理线程,对于集群内部请求则由同步代理线程处理分区内 同步事件;或分区代理线程处理分区间同步事件。
所有对数据的写操作均会记录入日志缓冲区,通过日志记录器将其异步写入磁盘。 用户数据会由代理线程直接写入文件系统缓冲池,然后由操作系统将其异步写入底层磁盘。
对外接口
基本上和MongoDB区别不大,用js搞得,接口粗看起来也差不多,努努力估计双方能兼容。SQL的支持通过postgresql实现,同时还实现了rest接口。
数据模型
SequoiaDB 数据库使用 JSON 数据模型,而非传统的关系型数据模型。
JSON 数据结构的全称为 JavaScript Object Notation,是一种轻量级的数据交换格式,非常易于人阅读和编 写,同时也易于机器生成和解析。其底层存储是BSON。The same as MongoDB
单个文件的限制依然是16MB。
存储模型
其具体实现也是经典的文件--数据段---数据页结构
文件可以跨页(废话,页的大小最大64k),但是跨不了块。
不知道是copy mongoDB还是处于系统简化的考虑,底层实际上还是mmap,也就是说读和换页什么的还是靠系统自己去搞得,相对于mongoDB的改进在于有后台任务刷脏页到磁盘。
一致性和持久性
事务模型
SequoiaDB 是 ACID 兼容文档级别,支持提交回滚等事务操作。默认情况下,SequoiaDB为了保证性能关闭事务的支持,如果用户需要则可以在启动数据库时指定参数打开事务。
在关闭事务支持时,一个单一操作能够写一个或多个字段,包括多个子文档的更新和数组元素更新。SequoiaDB 的 ACID 保证了文档更新的完整隔离性,任何错误都会引发回滚操作,以及客户能得到文档的一致性视图。
而当事务打开时,任何在事务启动到提交(回滚)之间的操作都会在数据节点写入事务日志并跟踪事务 ID。更改的记录在事务提交(回滚)前持有互斥锁,不可被其他会话更改。当前 SequoiaDB 事务的隔离级别为 UR。
一致性
SequoiaDB 采用集合级别的可配置一致性策略,允许用户在对记录修改时,根据该记录所在集合判断是否需要等待备节点的确认。
譬如,对于一个对性能要求较高、对数据可靠性要求一般的集合来说,可以在创建集合时将 write concern 参数设置为 1,代表只要写入主节点就可以返回成功信息。而该操作会在后台异步地发送给从节点执行。
而对于性能要求较低、对数据可靠性要求很高的集合来说,可以在创建集合时指定 write concern 参数为 3,代表该操作最少被三个节点确认执行成功后才能够返回。
当 write concern 的数量与该集合所在每个副本集中包含节点数量相等时,系统可以被认为是强一致,否则为最终一致。
对比
VS MongoDB
整体感觉,SequoiaDB就是一个refine版的mongoDB。修正或者说加强了mongoDB的很多问题,比如那个臭名昭著的锁啊,页管理了,有限的支持事务啥的。这个应该就是所谓的后发优势了,前面有人给你趟过一遍坑了,问题简化了很多。
至于说双方谁的质量高,谁的分布式架构好,谁皮实耐用那就是一个仁者见仁智者见智的问题。
一切交给时间去考察吧。
个人理解的有点在于
1.实现了行级锁,相对mongoDB极大的改善了插入性能,一些测试报告 也证明了这一点。
2.虽然依然是mmap但是似乎做了一些精细化管理。
3.有了最基础的事务支持。
4.没做复杂的mempool,缓存池之类的事情;把有限的精力投入到了最需要的地方。(窃以为即使依赖系统实现总比自己山寨一个乱七八糟的东西强,写内核的人是顶尖程序员,即使他们的程序不是为数据库优化的)。
VS FounderXML
这里的比较忽略XML和Json的巨大不同之处。
和FounderXML相比,SequoiaDB放弃了或者说不支持很多东西:
事务。换到的是相对简单的设计(C:SequoiaDB支持到read uncommit,比完全不支持好那么一点点),不用引入复杂的Postgresql或其的事务数据库/引擎。当然可以自己开发一个,嗯,这么天才的主意还是算了吧。
大文件支持,有没有,这是一个有点复杂的选择,支持吧,确实给系统带来更多的复杂性,性能也受到拖累;不支持吧,确实有实际需要。就快速出一个产品的角度说,还是不支持的好。
相对于FounderXML,SequoiaDB主要的进步点在于:
用简化的设计(代价是牺牲某些功能)快速完成一个产品。
依赖相对较少,其核心代码基本上都是自己开发的。只依赖boost,php,parser,crypto等少数东西。突然想起一个哥们吐槽某数据库是学化学的人写的,少依赖点离化学就远了一点点。
其它和代码相关的
CB
CB的含义是control block。在SequoiaDB中这是很重要的接口:控制相关的逻辑就靠它了
/*
_IControlBlock define
*/
class _IControlBlock : public SDBObject, public _ISDBRoot {
public:
_IControlBlock () {}
virtual ~_IControlBlock () {}
virtual SDB_CB_TYPE cbType() const = 0 ;
virtual const CHAR* cbName() const = 0 ;
virtual INT32 init () = 0 ;
virtual INT32 active () = 0 ;
virtual INT32 deactive () = 0 ;
virtual INT32 fini () = 0 ;
virtual void onConfigChange() {}
} ; typedef _IControlBlock IControlBlock ;
代码入口
整个数据库的入口在pmdMain.cpp中,基本上是读配置,初始化一堆mananger,恢复上次失败的数据的。关键代码是根据启动类型的不同启动不同的code block(CB):
void _pmdController::registerCB( SDB_ROLE dbrole )
{
if ( SDB_ROLE_DATA == dbrole )
{
PMD_REGISTER_CB( sdbGetDPSCB() ) ; // DPS
PMD_REGISTER_CB( sdbGetTransCB() ) ; // TRANS
PMD_REGISTER_CB( sdbGetClsCB() ) ; // CLS
PMD_REGISTER_CB( sdbGetBPSCB() ) ; // BPS
}
else if ( SDB_ROLE_COORD == dbrole )
{
PMD_REGISTER_CB( sdbGetTransCB() ) ; // TRANS
PMD_REGISTER_CB( sdbGetCoordCB() ) ; // COORD
PMD_REGISTER_CB( sdbGetFMPCB () ) ; // FMP
}
else if ( SDB_ROLE_CATALOG == dbrole )
{
PMD_REGISTER_CB( sdbGetDPSCB() ) ; // DPS
PMD_REGISTER_CB( sdbGetTransCB() ) ; // TRANS
PMD_REGISTER_CB( sdbGetClsCB() ) ; // CLS
PMD_REGISTER_CB( sdbGetCatalogueCB() ) ; // CATALOGUE
PMD_REGISTER_CB( sdbGetBPSCB() ) ; // BPS
PMD_REGISTER_CB( sdbGetAuthCB() ) ; // AUTH
}
else if ( SDB_ROLE_STANDALONE == dbrole )
{
PMD_REGISTER_CB( sdbGetDPSCB() ) ; // DPS
PMD_REGISTER_CB( sdbGetTransCB() ) ; // TRANS
PMD_REGISTER_CB( sdbGetBPSCB() ) ; // BPS
}
else if ( SDB_ROLE_OM == dbrole )
{
PMD_REGISTER_CB( sdbGetDPSCB() ) ; // DPS
PMD_REGISTER_CB( sdbGetTransCB() ) ; // TRANS
PMD_REGISTER_CB( sdbGetBPSCB() ) ; // BPS
PMD_REGISTER_CB( sdbGetAuthCB() ) ; // AUTH
PMD_REGISTER_CB( sdbGetOMManager() ) ; // OMSVC
}
//Data Management Service Control Block
//This file contains code logic for data management control block, which is the metat// data information for DMS component.
// 包括collection space等
PMD_REGISTER_CB( sdbGetDMSCB() ) ; // DMS
// 和context相关,create和delete context
PMD_REGISTER_CB( sdbGetRTNCB() ) ; // RTN
// SQL
PMD_REGISTER_CB( sdbGetSQLCB() ) ; // SQL
// 集合
PMD_REGISTER_CB( sdbGetAggrCB() ) ; // AGGR
//启动服务器/rest服务器/管理sessionInfo
PMD_REGISTER_CB( sdbGetPMDController() ) ; // CONTROLLER
}
可调度单元(EDU)
对于不同的EDU有不同的入口函数,比如监听一个端口的做法就是
rc = pEDUMgr->startEDU( EDU_TYPE_TCPLISTENER, (void*)_pTcpListener,
&eduID ) ;
其定义为:
// 根据type,启动一个线程(实际比这个复杂),把参数传递进去,并把eduid返回
INT32 _pmdEDUMgr::startEDU ( EDU_TYPES type, void* arg, EDUID *eduid )
系统会在启动一个线程,并调用pmdTcpListenerEntryPoint函数。
static const _eduEntryInfo entry[] = {
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_SHARDAGENT, FALSE,
pmdAsyncSessionAgentEntryPoint,
"ShardAgent" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_COORDAGENT, FALSE,
pmdAgentEntryPoint,
"CoordAgent" ),
// 最终调用_pmdDataProcessor::processMsg处理每条,顺便提一句这里有所有命令的列表
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_AGENT, FALSE,
pmdLocalAgentEntryPoint,
"Agent" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_REPLAGENT, FALSE,
pmdAsyncSessionAgentEntryPoint,
"ReplAgent" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_HTTPAGENT, FALSE,
pmdHTTPAgentEntryPoint,
"HTTPAgent" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_RESTAGENT, FALSE,
pmdRestAgentEntryPoint,
"RestAgent" ),
// 端口监听
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_TCPLISTENER, TRUE,
pmdTcpListenerEntryPoint,
"TCPListener" ),
// rest监听
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_RESTLISTENER, TRUE,
pmdRestSvcEntryPoint,
"RestListener" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_CLUSTER, TRUE,
pmdCBMgrEntryPoint,
"Cluster" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_CLUSTERSHARD, TRUE,
pmdCBMgrEntryPoint,
"ClusterShard" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_CLSLOGNTY, TRUE,
pmdClsNtyEntryPoint,
"ClusterLogNotify" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_REPR, TRUE,
pmdAsyncNetEntryPoint,
"ReplReader" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_LOGGW, TRUE,
pmdLoggWEntryPoint,
"LogWriter" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_SHARDR, TRUE,
pmdAsyncNetEntryPoint,
"ShardReader" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_PIPESLISTENER, TRUE,
pmdPipeListenerEntryPoint,
"PipeListener" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_BACKGROUND_JOB, FALSE,
pmdBackgroundJobEntryPoint,
"Task" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_CATMAINCONTROLLER, TRUE,
pmdCBMgrEntryPoint,
"CatalogMC" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_CATNODEMANAGER, TRUE,
pmdCBMgrEntryPoint,
"CatalogNM" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_CATCATALOGUEMANAGER, TRUE,
pmdCBMgrEntryPoint,
"CatalogManager" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_CATNETWORK, TRUE,
pmdAsyncNetEntryPoint,
"CatalogNetwork" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_COORDNETWORK, TRUE,
pmdCoordNetWorkEntryPoint,
"CoordNetwork" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_DPSROLLBACK, TRUE,
pmdDpsTransRollbackEntryPoint,
"DpsRollback"),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_LOADWORKER, FALSE,
pmdLoadWorkerEntryPoint,
"MigLoadWork" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_PREFETCHER, FALSE,
pmdPreLoaderEntryPoint,
"PreLoader" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_OMMGR, TRUE,
pmdCBMgrEntryPoint,
"OMManager" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_OMNET, TRUE,
pmdAsyncNetEntryPoint,
"OMNet" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_SYNCCLOCK, TRUE,
pmdSyncClockEntryPoint,
"SyncClockWorker" ),
ON_EDUTYPE_TO_ENTRY1 ( EDU_TYPE_MAXIMUM, FALSE,
NULL,
"Unknow" )
};
内存管理
虽然定义了SDBObject,很多类都是从这个类继承而来,这个类重写了new/delete,不过到底层还是使用了malloc解决问题,不排除以后会升级成mempool。目前还是只加了一些checking而已。
看起来查询时用的内存都是临时分配的,而系统的内存应该还是消耗在了mmap上。
查询执行
一个基本的query执行方式:
1.rtnQuery 完成查询计划的build(查询优化似乎做了一些事情,还没来得及细看),定位到第一个结果处。
2.rtnGetMore 从第一个结果处继续扫描结果。
从而避免了可能的查询结果过大的问题。
操作系统封装
在OSS中封装了常见的系统调用,比如read,create,open,malloc之类的。btw,有的文档中只列出了linux支持的版本,从代码上看windows应该也是支持的。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。