
本文章属于爬虫入门到精通系统教程第五讲
在爬虫入门到精通第四讲中,我们了解了如何下载网页,这一节就是如何从下载的网页中获取我们想要的内容
万能匹配
html = u"""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>文章的标题</title>
</head>
<body>
<div id="app" class="container">
<h1>h1文字</h1>
<label for="input">Input</label>
<textarea id="input" rows="10" class="form-control">
</body>
</html>
"""
我们要获取的html 如上所示,
假如我们要获取文章的标题这几个文字,那么我们应该怎么做呢?
我们只要能定位到它,也就能获取到它
那么,如何定位到它呢?
很简单,根据它两边的内容.
我们很简单的能发现 它 左边是<title> ,右边是</title>
所以,我们如何找到文章的标题这几个文字呢,只要左边是<title> ,右边是</title>,那么中间就是我们要找的
下面用程序写出来
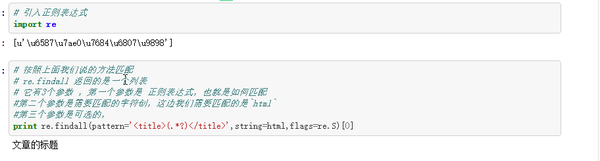
可以看到我们正确匹配到了文章的标题,
我们首先来看 pattern = '<title>(.*?)</title>'
我们可以发现这就是我们上面讲的,左边是<title> ,右边是</title>,那么中间的(.*?)是什么呢?这其实是来用来声明我们要匹配的字符串是什么,这边我们用的是(.*?),表示我们要匹配的字符串可以是任何东西,没有格式要求。也就是俗称"万能匹配",大家可以下图的正则表达式语法,来解释下为什么 .*? 是万能匹配, .*? 外面的 () 又是什么鬼
string=html 表示我们当前要被匹配的是我们定义的html
最后flags=re.S 表示(.*?)中的 . 可以匹配包括换行符(见下面表)
[0] 是取返回列表中的第一个,主要是方便演示
正则表达式语法(声明我们要匹配的字符串是什么格式的)
图片来自 博客园
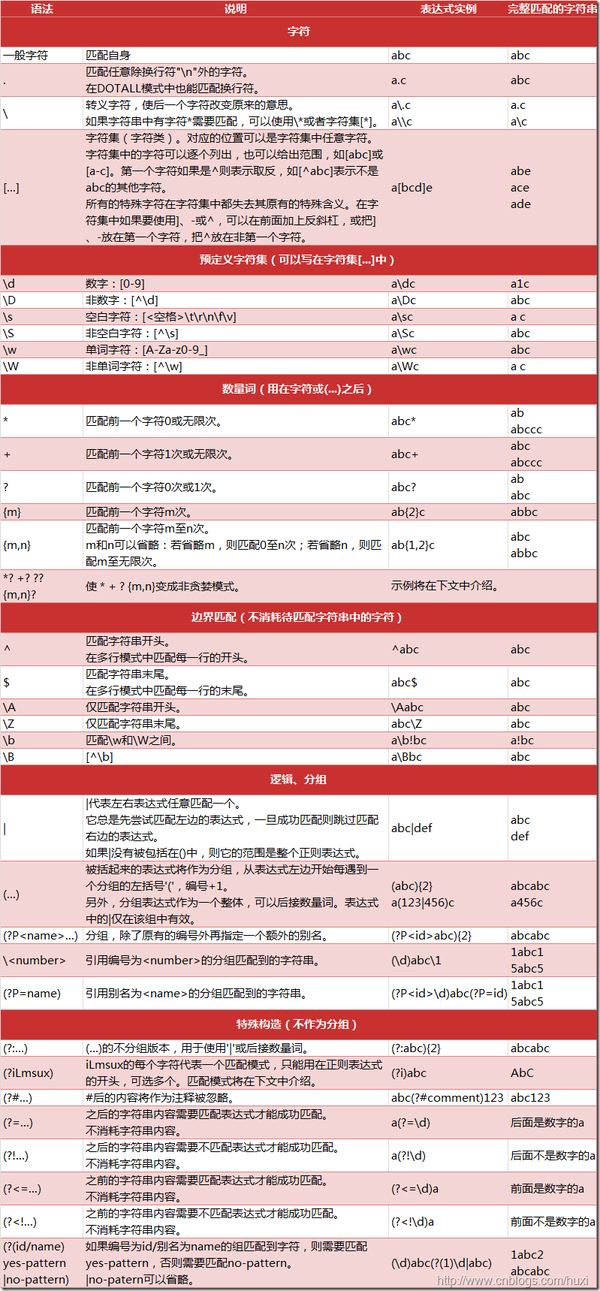
re中所有的flags解释

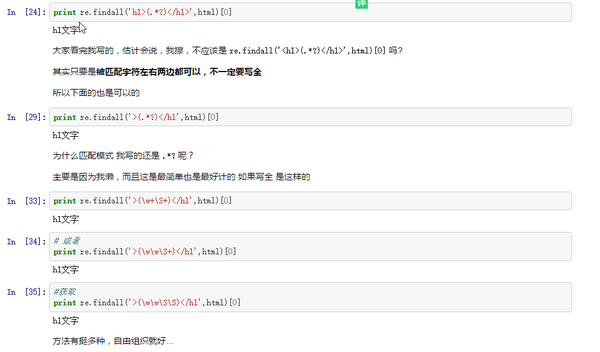
最后再来一个案例,还是上面的html,我们需要匹配的内容是h1文字
代码如下
本文使用notebook编写完成,全文在github上
总结
看完本篇文章后,你应该要:
学会最通用的一种正则表达式
re.findall('左右的字符串(.*?)右边的字符串',等待匹配的字符串,flags)
大家想深入了解正则表达式的话
请 先看这一篇 正则表达式30分钟入门教程
再看这一篇 Regular expression operations
最后的最后,收藏的大哥们,能帮忙点个赞么~






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。