
摘要: 还有一些问题场景下下应用的内存泄漏非常严重和迅速,甚至于在我们的告警系统感知之前就已经造成应用的 OOM 了,这时我们来不及或者说根本没办法获取到堆快照,因此就没有办法借助于之前的办法来分析为什么进程会内存泄漏到溢出进而 Crash 的原因了。
楔子
实践篇一中我们也看到了一个比较典型的由于开发者不当使用第三方库,而且在配置信息中携带了三方库本身使用不到的信息,导致了内存泄漏的案例,实际上类似这种相对缓慢的 Node.js 应用内存泄漏问题我们总是可以在合适的机会抓取堆快照进行分析,而且堆快照一般来说确实是分析内存泄漏问题的最佳手段。
但是还有一些问题场景下下应用的内存泄漏非常严重和迅速,甚至于在我们的告警系统感知之前就已经造成应用的 OOM 了,这时我们来不及或者说根本没办法获取到堆快照,因此就没有办法借助于之前的办法来分析为什么进程会内存泄漏到溢出进而 Crash 的原因了。这种问题场景实际上属于线上 Node.js 应用内存问题的一个极端状况,本节将同样从源自真实生产的一个案例来来给大家讲解下如何处理这类极端内存异常。
本书首发在 Github,仓库地址:https://github.com/aliyun-node/Node.js-Troubleshooting-Guide,云栖社区会同步更新。
最小化复现代码
同样我们因为例子的特殊性,我们需要首先给出到大家生产案例的最小化复现代码,建议读者自行运行一番此代码,这样结合起来看下面的排查分析过程会更有收获。最小复现代码还是基于 Egg.js,如下所示:
'use strict';
const Controller = require('egg').Controller;
const fs = require('fs');
const path = require('path');
const util = require('util');
const readFile = util.promisify(fs.readFile);
class DatabaseError extends Error {
constructor(message, stack, sql) {
super();
this.name = 'SequelizeDatabaseError';
this.message = message;
this.stack = stack;
this.sql = sql;
}
}
class MemoryController extends Controller {
async oom() {
const { ctx } = this;
let bigErrorMessage = await readFile(path.join(__dirname, 'resource/error.txt'));
bigErrorMessage = bigErrorMessage.toString();
const error = new DatabaseError(bigErrorMessage, bigErrorMessage, bigErrorMessage);
ctx.logger.error(error);
ctx.body = { ok: false };
}
}
module.exports = MemoryController;这里我们还需要在 app/controller/ 目录下创建一个 resource 文件夹,并且在这个文件夹中添加一个 error.txt,这个 TXT 内容随意,只要是一个能超过 100M 的很大的字符串即可。
值得注意的是,其实这里的问题已经在 egg-logger >= 1.7.1 的版本中修复了,所以要复现当时的状况,你还需要在 Demo 的根目录执行以下的三条命令以恢复当时的版本状况:
rm -rf package-lock.json
rm -rf node_modules/egg/egg-logger
npm install egg-logger@1.7.0最后使用 npm run dev 启动这个问题最小化复现的 Demo。
感知进程出现问题
这个案例下,实际上我们的线上 Node.js 应用几乎是触发了这个 Bug 后瞬间内存溢出然后 Crash 的,而平台预设的内存阈值告警,实际上是由一个定时上报的逻辑构成,因此存在延时,也导致了这个案例下我们无法像 冗余配置传递引发的内存溢出 问题那样获取到 Node.js 进程级别的内存超过预设阈值的告警。
那么我们如何来感知到这里的错误的呢?这里我们的服务器配置过了 ulimit -c unlimited ,因此 Node.js 应用 Crash 的时候内核会自动生成核心转储文件,而且性能平台目前也支持核心转储文件的生成预警,这一条规则目前也被放入了预设的快速添加告警规则中,可以参考工具篇中 Node.js 性能平台使用指南 - 配置合适的告警 一节,详细的规则内容如下所示:

这里需要注意的是,核心转储文件告警需要我们在服务器上安装的 Agenthub/Agentx 依赖的 Commandx 模块的版本在 1.5.2 之上(包含),这一块更详细的信息也可以看官方文档 核心转储分析能力 一节。
问题排查过程
I. 分析栈信息
依靠上面提到的平台提供的核心转储文件生成时给出的告警,我们在收到报警短信时登录控制台,可以看到 Coredump 文件列表出现了新生成的核心转储文件,继续参照工具篇中 Node.js 性能平台使用指南 - 核心转储分析 中给出的转储和 AliNode 定制分析的过程,我们可以看到如下的分析结果展示信息:
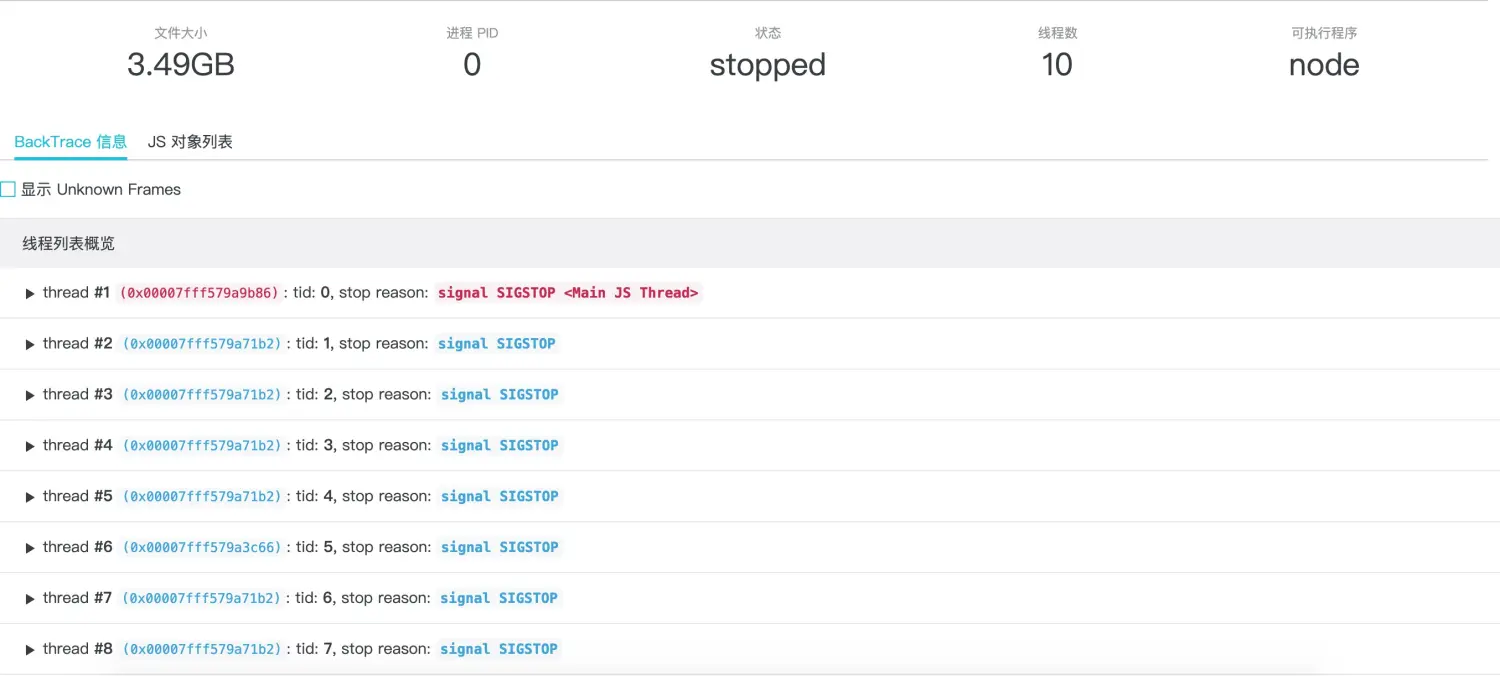
同样我们直接展开 JavaScript 栈信息查看应用 Crash 那一刻的栈信息:
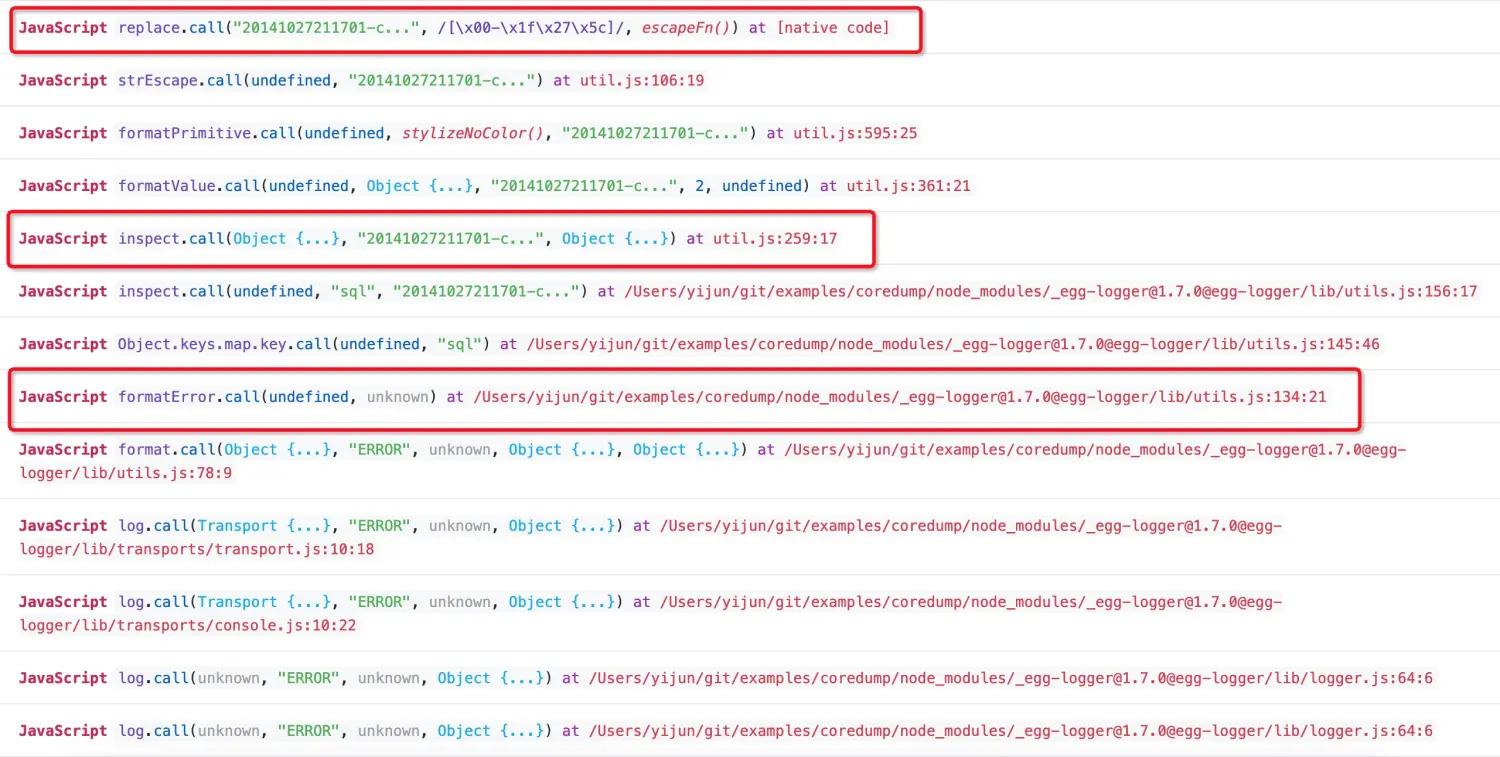
截图中忽略掉了 Native C/C++ 代码的栈信息,这里其实仅仅看 JavaScript 栈信息就能得到结论了,通过翻阅比对出问题的 egg-logger@1.7.0 中 lib/utils.js 的代码内容:
function formatError(err) {
// ...
// 这里对 Error 对象的 key 和 value 调用 inspect 方法进行序列化
const errProperties = Object.keys(err).map(key => inspect(key, err[key])).join('\n');
// ...
}
// inspect 方法实际上是调用 require('util').inspect 来对错误对象的 value 进行序列化
function inspect(key, value) {
return `${key}: ${util.inspect(value, { breakLength: Infinity })}`;
}这样我们就知道了线上 Node.js 应用在 Crash 的那一刻正在使用 require('util').inspect 对某个字符串进行序列化操作。
II. 可疑字符串
那么这个序列化的动作究竟是不是造成进程 Crash 的元凶呢?我们接着来点击 inspect 函数的参数来展开查看这个可疑的字符串的详细信息,如下图所示:

点击红框中的参数,得到字符串的详情页面链接,如下图所示:

再次点击这里的 detail 链接,既可在弹出的新页面中看到这个可疑字符串的全部信息:
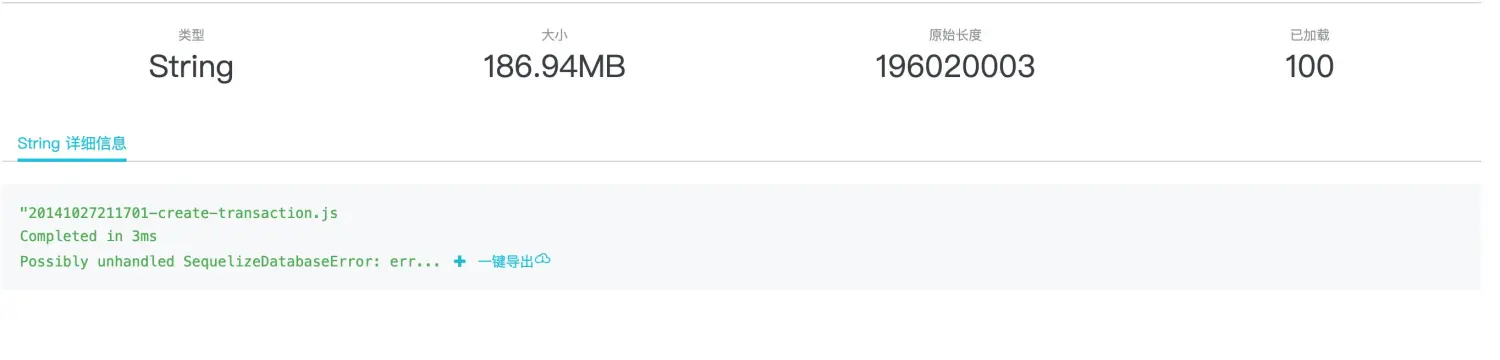
这里可以看到,这个正在被 util.inspect 的字符串大小高达 186.94 兆,显然正是在序列化这么大的字符串的时候,造成了线上 Node.js 应用的堆内存雪崩,几乎在瞬间就内存溢出导致 Crash。
值得一提的是,我们还可以点击上图中的 + 号来在当前页面展示更多的问题字符串内容:
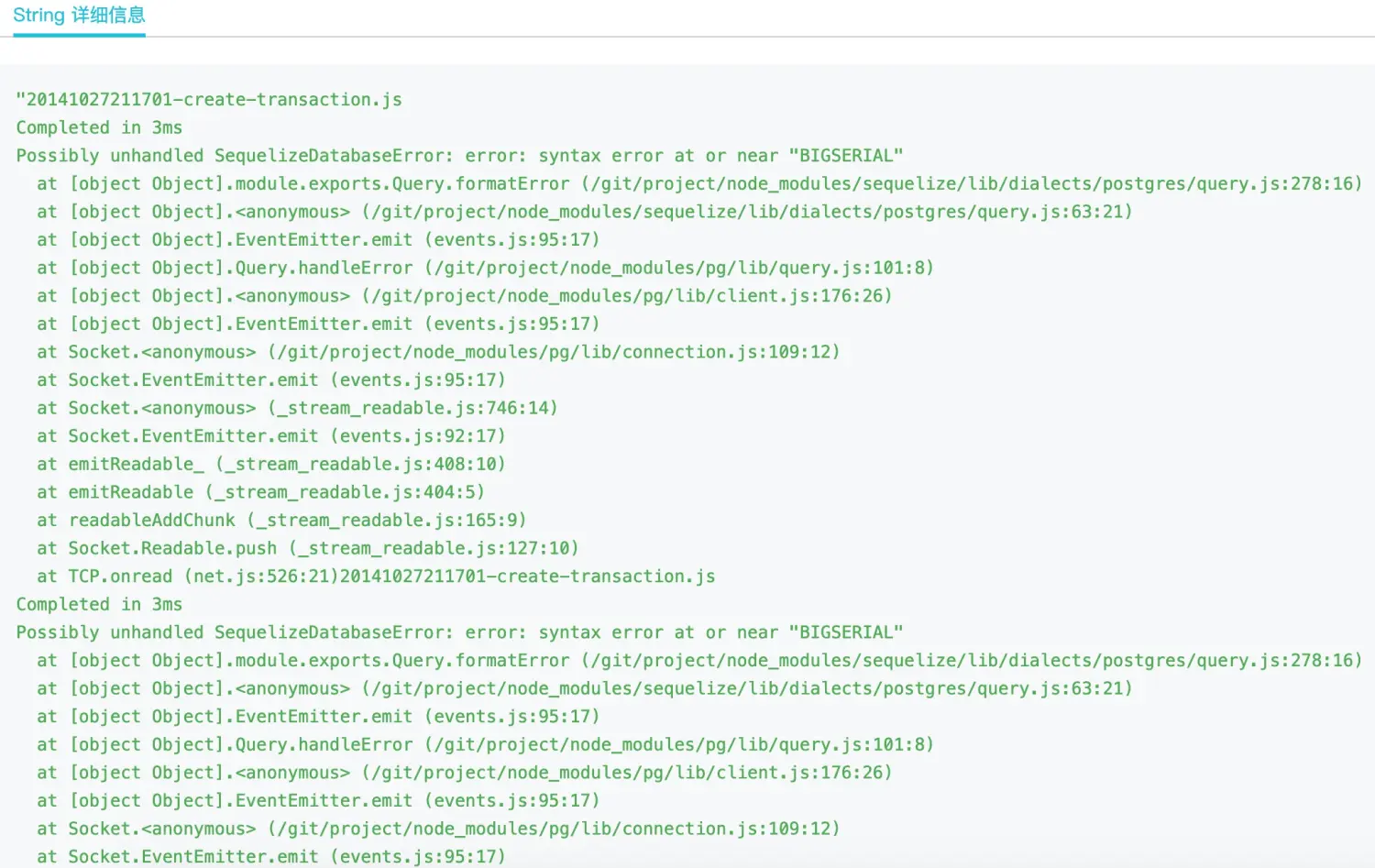
也可以在页面上点击 一键导出 按钮下载问题完整的字符串:
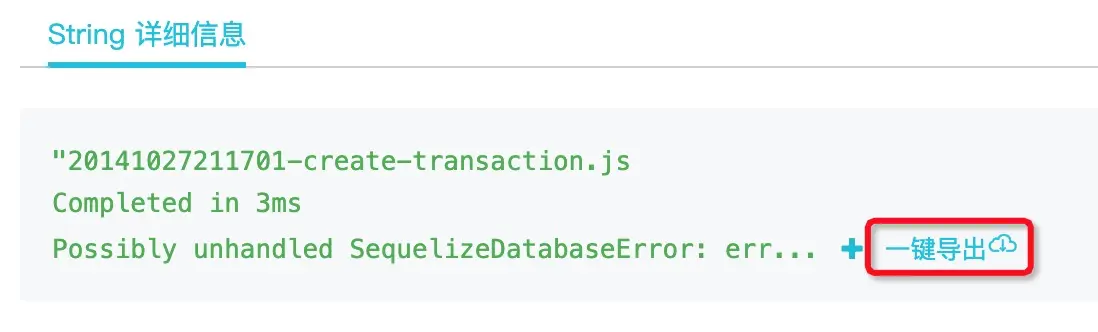
毕竟对于这样的问题来说,如果能抓到产生问题的元凶参数,起码能更方便地进行本地复现。
III. 修复问题
那么知道了原因,其实修复此问题就比较简单了,Egg-logger 官方是使用 circular-json 来替换掉原生的 util.inspect 序列化动作,并且增加序列化后的字符串最大只保留 10000 个字符的限制,这样就解决这种包含大字符串的错误对象在 Egg-logger 模块中的序列化问题。
结尾
本节的给大家展现了对于线上 Node.js 应用出现瞬间 Crash 问题时的排查思路,而在最小化复现 Demo 对应的那个真实线上故障中,实际上是拼接的 SQL 语句非常大,大小约为 120M,因此首先导致数据库操作失败,接着数据库操作失败后输出的 DatabaseError 对象实例上则原封不动地将问题 SQL 语句设置到属性上,从而导致了 ctx.logger.error(error) 时堆内存的雪崩。
在 Node.js 性能平台 提供的 核心转储告警 + 在线分析能力 的帮助下,此类无法获取到常规 CPU Profile 和堆快照等信息的进程无故崩溃问题也变得有迹可循了,实际上它作为一种兜底分析手段,在很大程度上提升了开发者真正将 Node.js 运用到服务端生产环境中的信心。
本文作者:奕钧
本文为云栖社区原创内容,未经允许不得转载。







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。