
1.计算每年同月份增长比
esproc
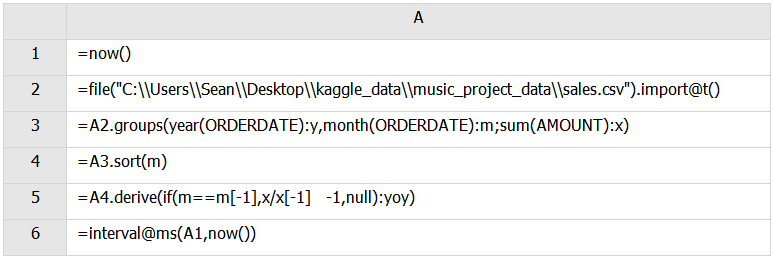
A3:用ORDERDATE的年份和月份分组,并将该列命名为y,m,同时计算该组的销售量
group()函数分组但不汇总,groups分组同时汇总。
A4:按照月份m进行排序
A5:新增一列,如果月份等于前一行的月份,则计算增长比并赋值,否则赋值null,将该列命名为yoy。
python:
import time
import numpy as np
import pandas as pd
s = time.time()
sales = pd.read_csv("C:\Users\Sean\Desktop\kaggle_data\music_project_data\sales.csv",sep='\t')
sales['ORDERDATE']=pd.to_datetime(sales['ORDERDATE'])
sales['y']=sales['ORDERDATE'].dt.year
sales['m']=sales['ORDERDATE'].dt.month
sales_g = sales[['y','m','AMOUNT']].groupby(by=['y','m'],as_index=False)
amount_df = sales_g.sum().sort_values(['m','y'])
yoy = np.zeros(amount_df.values.shape[0])
yoy=(amount_df['AMOUNT']-amount_df['AMOUNT'].shift(1))/amount_df['AMOUNT'].shift(1)
yoy[amount_df['m'].shift(1)!=amount_df['m']]=np.nan
amount_df['yoy']=yoy
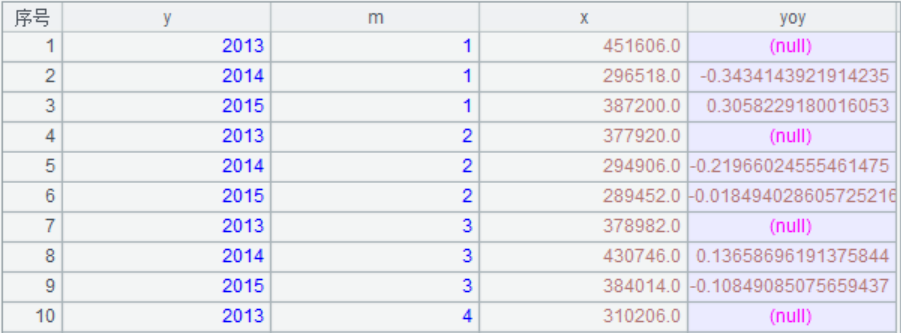
print(amount_df)
e = time.time()
print(e-s)
pd.to_datetime(),转换为日期格式。新增加y和m列表示年和月。df.groupby(by,as_index)按照某个字段或者某几个字段进行分组,其中参数as_index=False是否返回以组标签为索引的对象。df.sort_values()将新的dataframe按照月份和年份进行分组.新建一个数组,准备存放计算出来的同期增长比。df.shift(1)表示将原来的df下一行,即相对于当前行为上一行,给该数组赋值为增长比(当前行减上一行的值除以上一行的值),由于月份不同,所以将上一行与该行相同的月份赋值为nan,最后将该数组赋值给df新增加的列yoy。
结果:
esproc
python

2. 计算1998年销售额占到一半的前 n 个客户
esproc
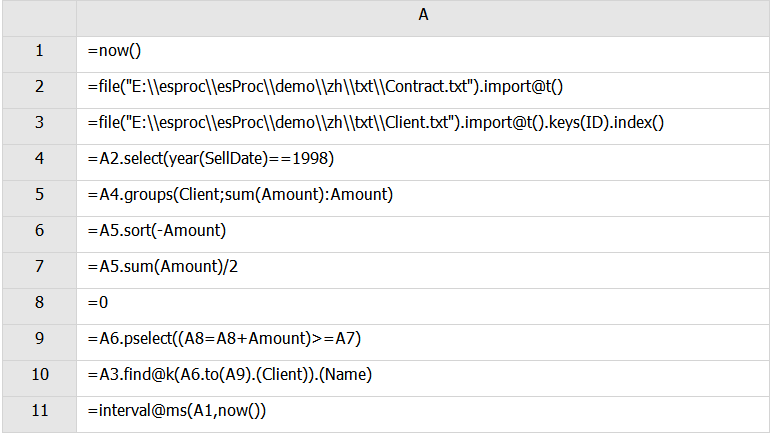
A3:T.keys(Ki,…),为内表T定义键Ki,…。;T.index(n),为序表T的键建立长为n的索引表,n为0或序表重置键时将清除索引表;n省略则自动选长度。如果需要多次根据键来查找数据,在建立了索引表之后可以提高效率。建立索引时假定记录的主键唯一,否则出错。
A4:筛选出1998年的交易记录
A5:按照Client进行分组,同时计算交易量Amount之和
A6:按照Amount进行排序
A9:找到Amount累加到一半交易量的位置
A10:A.find(k),从排列/序表A中找到主键等于k的成员,有索引表则使用索引表。@k当参数k是序列时被认为是键值序列,返回键值对应的A的成员。这里是返回键ID的值等于A6.to(A9).(Client)的成员的Name字段序列。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
contract_info=pd.read_csv('E:\esproc\esProc\demo\zh\txt\Contract.txt',sep='\t')
client_info = pd.read_csv('E:\esproc\esProc\demo\zh\txt\Client.txt',sep='\t',encoding='gbk')
contract_info['SellDate']=pd.to_datetime(contract_info['SellDate'])
contract_info_1998 = contract_info[contract_info['SellDate'].dt.year==1998]
contract_1998_g = contract_info_1998[['Client','Amount']].groupby(by='Client',as_index=False)
contract_sort = contract_1998_g.sum().sort_values(by = 'Amount',ascending=False).reset_index(drop=True)
half_amount = contract_sort['Amount'].sum()/2
sm=0
for i in range(len(contract_sort['Amount'])):
sm+=contract_sort['Amount'][i]
if sm>=half_amount:
break
n_client = contract_sort['Client'].loc[:i]
client_info = client_info.set_index('ID')
print(client_info.loc[n_client]['Name'])
e = time.time()
print(e-s)
筛选出1998年的记录
因为这里只用到了交易信息的Client和Amount字段,所以只选出这两个字段并按照Client字段分组。df.sort_values(by,ascending),这里是按照Amount进行倒序排序。
df.reset_index(drop)重建索引,drop=True表示丢掉原来的索引,否则把原来的索引当做一列插入。
求得所有交易额的一半的值,循环Amount字段,找到累加之和大于或等于交易额一半的位置。取Client字段0到该位置的值组成一个Series。
根据这个Series去client_info中找到对应的行的Name值。
结果:
esproc
python


3.找出1995年每个月销售额都在前8名的销售员
esproc
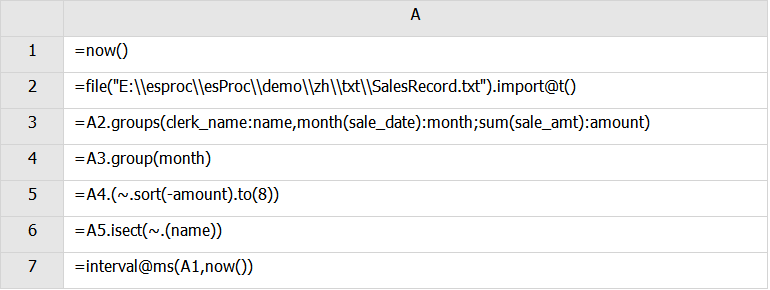
A3:按照clerk_name和月份month(sale_date)分组,同时将这两个字段命名为name和month,计算各组sale_amt的和,命名为amount
A4:按照月份分组并进行求和。
A5:将amount按照倒序排序,并取前8名
A6: A.isect(),序列A成员可以为序列,产生所有子序列都有的成员组成的新序列。这里是求所有成员的交集。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
sale_rec = pd.read_csv('E:\esproc\esProc\demo\zh\txt\SalesRecord.txt',sep='\t')
sale_rec['sale_date'] = pd.to_datetime(sale_rec['sale_date'])
sale_rec['m'] = sale_rec['sale_date'].dt.month
sale_rec_g = sale_rec.groupby(by=['clerk_name','m'],as_index=False).sum()
sale_month_g = sale_rec_g.groupby('m',as_index=False)
sale_set = set(sale_rec['clerk_name'].drop_duplicates().values.tolist())
for index,group in sale_month_g:
group_topn = group.sort_values(by='sale_amt',ascending=False)[:8]
sale_set = sale_set.intersection(set(group_topn['clerk_name'].values.tolist()))
print(list(sale_set))
e = time.time()
print(e-s)
新增一列m表示月份
按照clerk_name,m进行分组,并求取sale_amt的和
按照m分组
初始化一个包含所有clerk_name的集合
循环分组,用初始集合与各个组的clerk_name一次求交集,并赋值给初始的集合,最终求得所有集合的交集。
结果:

4.找出修改过的记录
esproc
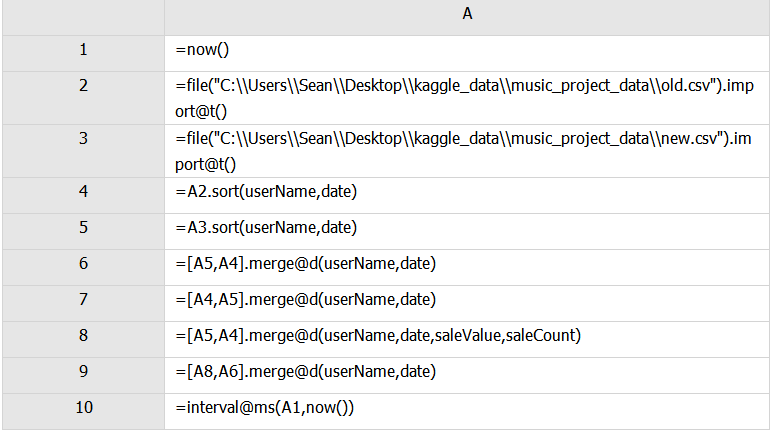
A4、A5:按照userName和date排序
A6: A.merge(xi,…) ,归并计算A(i)|…,A(i)对[xi,…]有序,将多个序表/排列按指定字段xi有序合并,xi省略按主键合并,若xi省略且A没有主键则按照r.v()合并。A(i)必须同构。@d选项,从A(1)中去掉A(2) &…A(n)中的成员后形成的新序表/排列,即求差集。新表与旧表的差集即新增加的记录。
A7:求旧表与新表的差集,即旧表中删除的记录。
A8:xi为所有字段,得到新表中所有修改过的记录包括新增的和修改的
A9:用所有修改的记录与新增的记录求差集得到修改的记录。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
old = pd.read_csv('C:\Users\Sean\Desktop\kaggle_data\music_project_data\old.csv',sep='\t')
new = pd.read_csv('C:\Users\Sean\Desktop\kaggle_data\music_project_data\new.csv',sep='\t')
old_delet_rec = pd.merge(old,new,how='left',on=['userName','date'])
delet_rec = old_delet_rec[np.isnan(old_delet_rec['saleValue_y'])][['userName', 'date', 'saleValue_x', 'saleCount_x']]
print('delet_rec')
print(delet_rec)
new_add_rec = pd.merge(old,new,how='right',on=['userName','date'])
new_rec = new_add_rec[np.isnan(new_add_rec['saleValue_x'])][['userName', 'date', 'saleValue_y', 'saleCount_y']]
print('new_rec')
print(new_rec)
all_rec = pd.concat([old,new])
all_update_rec = all_rec.drop_duplicates(keep=False)
update_rec = all_update_rec[all_update_rec[['userName','date']].duplicated()]
print('update_rec')
print(update_rec)
e = time.time()
print(e-s)
首先merge(old,new,on=’left’)将旧表左连接新表,新表中包含nan的行就是旧表删除的行,由于字段名一样,所以python默认添加的后缀是_x,_y,删除的记录就是截取merge以后的前四个字段。
同理使用右连接,得到新表新增的行。
pd.concat([df1,df2])将旧表和新表纵向连接,df.drop_duplicates(keep=False),删除所有重复的行,得到两张表所有不一样的记录,从中选出['userName','date']两个字段相同的字段,即为修改过的字段。
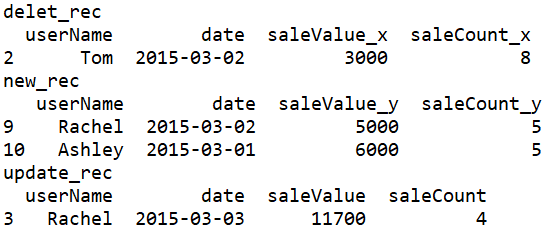
结果:
esproc
delet_rec

new_rec

update_rec

python

5. 计算出指定时间段内每天每种货物的库存状态
题目介绍:stocklog.csv中的数据有四个字段分别是STOCKID货物编号,DATE日期(不连续),QUANTITY出入库数量,INDICATOR标致,如果INDICATOR为空表示入库,ISSUE表示出库。
数据如下:
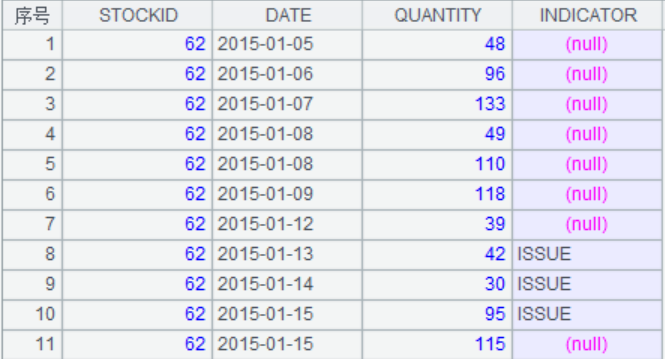
我们的目的是用这份数据分别计算出指定时间内各种货物的库存状态,即STOCKID,货物编号,DATE日期(连续的),OPEN开库时数量,ENTER当天入库数量,TOTAL最当天最大数量,ISSUE当天出库数量,CLOSE闭库时的数量。
esproc
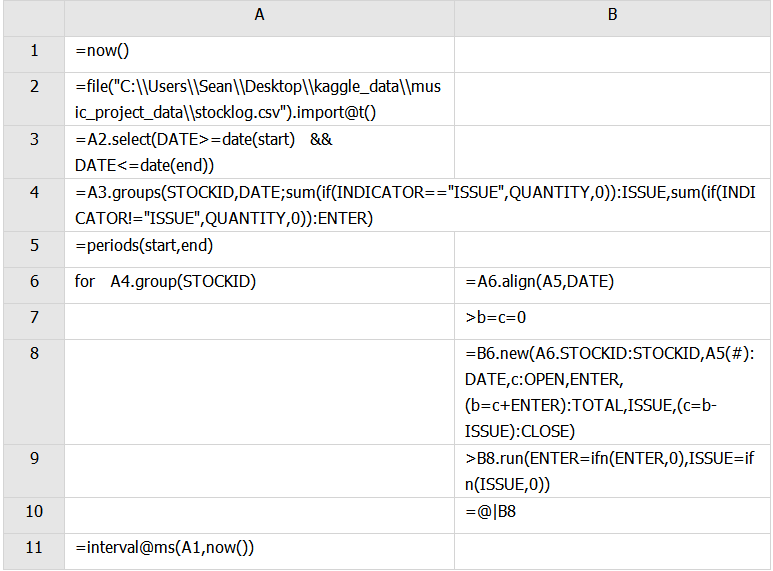
A3:选出指定日期内的数据,start和end是提前设置好的网格变量(在集算器的程序——网格参数处可以设置。)
A4:按照STOCKID和DATE分组,同时对各组进行计算,if(x,true,false),这里是如果INDICATOR==ISSUE,if()函数等于QUANTITY的值,否则为0,将此结果在该组中求和后添加到字段ISSUE,如果INDICATOR==ISSUE,if()函数等于0,否则为QUANTITY的值,将此结果在该组中求和后添加到字段ENTER。最终得到每天每种物品的出入库总数。
A5: periods可以生成时间序列
A6:循环分组
B6: P.align(A:x,y),x,y省略则以P当前记录与A中成员对齐。通过关联字段x 和 y 将P 的记录按照A 对齐。对着排列P计算y的值,计算结果和A中的x的值相等则表示两者对齐。这里是当前产品的出入库记录与B5中的时间序列对齐。
B7:定义b,c两个变量,b作为OPEN字段的初始值,
B8:建立新表,其中STOCKID为A6的STOCKID,将时间序列B5按顺序插入新序表,作为新字段DATE,c作为OPEN字段,将B6中的ENTER字段当做现在ENTER字段,为b赋值为c+ENTER作为TOTAL字段,将B6中的ISSUE字段当做现在ISSUE字段,最后把c赋值为b-ISSUE作为CLOSE字段。
B9: ifn(valueExp1, valueExp2) 判断valueExp1的值是否为空,若为空则返回valueExp2,不为空则返回该表达式的值。这里就是将null填为0.
B10:@表示当前格,这里的意思是把结果不断的汇总在当前格,最后得到结果。
python:
import time
import pandas as pd
import numpy as np
s=time.time()
starttime = '2015-01-01'
endtime = '2015-12-31'
stock_data = pd.read_csv('C:\Users\Sean\Desktop\kaggle_data\music_project_data\stocklog.csv',sep='\t')
stock_data['DATE']=pd.to_datetime(stock_data['DATE'])
stock_data = stock_data[stock_data['DATE']>=starttime]
stock_data = stock_data[stock_data['DATE']<=endtime]
stock_data['ENTER']=stock_data['QUANTITY'][stock_data['INDICATOR']!='ISSUE']
stock_data['ISSUE']=stock_data['QUANTITY'][stock_data['INDICATOR']=='ISSUE']
stock_g = stock_data[['STOCKID','DATE','ENTER','ISSUE']].groupby(by=['STOCKID','DATE'],as_index=False).sum()
stock_gr = stock_g.groupby(by='STOCKID',as_index = False)
date_df = pd.DataFrame(pd.date_range(starttime,endtime),columns=['DATE'])
stock_status_list = []
for index,group in stock_gr:
date_df['STOCKID']=group['STOCKID'].values[0]
stock_status = pd.merge(date_df,group,on=['STOCKID','DATE'],how='left')
stock_status = stock_status.sort_values(['STOCKID','DATE'])
stock_status['OPEN']=0
stock_status['CLOSE']=0
stock_status['TOTAL']=0
stock_status = stock_status.fillna(0)
stock_value = stock_status[['STOCKID','DATE','OPEN','ENTER','TOTAL','ISSUE','CLOSE']].values
open = 0
for value in stock_value:
value[2] = open
value[4] = value[2]+value[3]
value[6] = value[4] - value[5]
open = value[6]
stock = pd.DataFrame(stock_value,columns = ['STOCKID','DATE','OPEN','ENTER','TOTAL','ISSUE','CLOSE'])
stock_status_list.append(stock)
stock_status = pd.concat(stock_status_list,ignore_index=True)
print(stock_status)
e=time.time()
print(e-s)
pd.to_datetime(),将DATE字段转换为pandas的datetime类型。Pandas写成这种形式(stock_data = stock_data[endtime>=stock_data['DATE']>=starttime])进行日期筛选是会报错的,不支持同时计算,所以只能分两次截取时间。
新建ENTER,ISSUE两个字段,并按照INDICATOR是否是ISSUE判断,如果是则将QUANTITY的值赋值给ISSUE,如果不是则将QUANTITY的值赋值给ENTER。
取到STOCKID,DATE,ENTER,ISSUE四个字段,并按照STOCKID,DATE进行分组,同时对各组求和,得到每一天每种货物的出入库记录。
pd.date_range(starttime,endtime)生成一个starttime~endtime的Series,pd.DataFrame()将它生成为一个dataframe(date_df)
将数据按照STOCKID进行分组
新建一个list,准备加入各个货物的出入库状态。
循环各组,为 date_df加入STOCKID列,生成包含DATE,STOCKID两列的dataframe,pd.merge(df1,df2,on,how),将该dataframe与该组按照STOCKID,DATE,进行左连接,得到连续日期。
df.fillna(0)将df中的nan赋值为0,
新增加三列OPEN,TOTAL,CLOSE并都赋值为0.
将字段按照['STOCKID','DATE','OPEN','ENTER','TOTAL','ISSUE','CLOSE']顺序,依次取出,并取得这些字段的值(类型是numpy.ndarray)。
初始化open=0
循环这个数组中的元素,'OPEN','ENTER','TOTAL','ISSUE','CLOSE'字段对应的值分别为value[2], value[3], value[4], value[5], value[6],open赋值给value[2],TOTAL=OPEN+ENTER,CLOSE=TOTAL-ISSUE,再将close赋值给open作为下一元素的value[2]。
最后将该数组转换为dataframe,得到这种货物的出入库状态
将所有货物的出入库状态都放入开始新建的list中
最后pd.concat([df1,df2,…,dfn],ignore_index)合并这些dataframe,忽略原来的索引,得到所有货物的出入库状态。
结果:
esproc
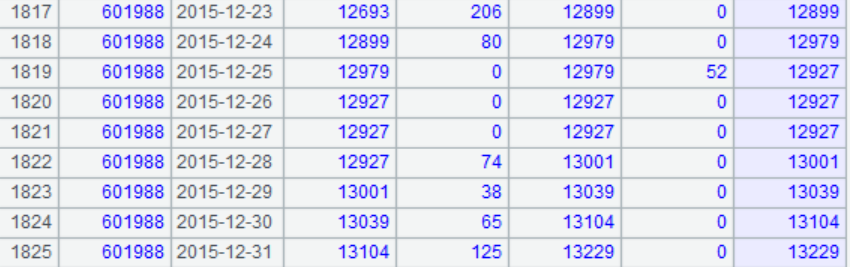
python

6.计算每个人的起止值班时间
题目介绍:表duty记录着值班情况,一个人通常会持续值班几个工作日再换其他人,数据如下:
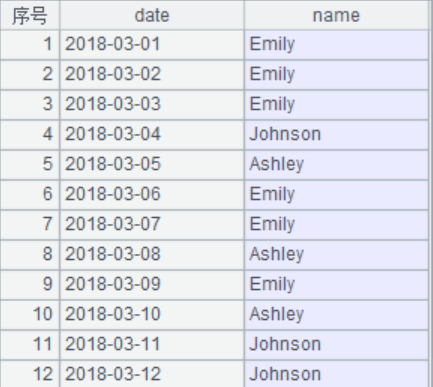
我们的目的是根据duty表计算出每个值班的起止时间。
esproc
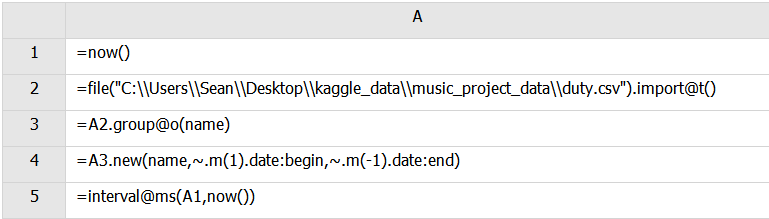
本例依旧简单
A3:A.group(xi,…),将序列/排列按照一个或多个字段/表达式进行等值分组,结果为组集构成的序列。@o表示分组时不重新排序,数据变化时才另分一组。
A4:A.new()根据序表/排列A的长度,生成一个记录数和A相同,且每条记录的字段值为xi,字段名为Fi的新序表/排列。这里表示根据分组子集A3新建二维表,其中~.m(1)表示取各组首行,~.m(-1)表示取各组尾行。
python:
import time
import pandas as pd
import numpy as np
import random
s=time.time()
duty = pd.read_csv('C:\Users\Sean\Desktop\kaggle_data\music_project_data\duty.csv',sep='\t')
name_rec = ''
start = 0
duty_list = []
for i in range(len(duty)):
if name_rec == '':
name_rec = duty['name'][i]
if name_rec != duty['name'][i]:
begin = duty['date'].loc[start:i-1].values[0]
end = duty['date'].loc[start:i-1].values[-1]
duty_list.append([name_rec,begin,end])
start = i
name_rec = duty['name'][i]
begin = duty['date'].loc[start:i].values[0]
end = duty['date'].loc[start:i].values[-1]
duty_list.append([name_rec,begin,end])
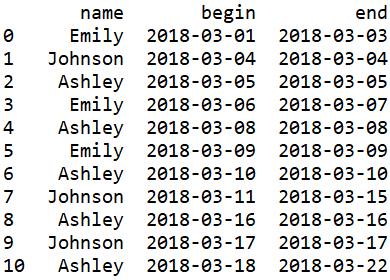
duty_b_e = pd.DataFrame(duty_list,columns=['name','begin','end'])
print(duty_b_e)
e=time.time()
print(e-s)
说明:小编没有找到pandas中不重新排序进行分组的方法,所以只能选择这种笨方法,又因为一直都是对比的pandas,所以也没有用python自带的IO读取方式来完成此题。下面还是简单介绍下代码:
初始化name_rec用来保留name字段的值,strat用来保留截取位置,duty_list用来保存最后的结果。
创建一个循环,开始将数据中的第一个name的值赋值给name_rec,然后下一次循环,如果name_rec相同,则继续。直到不相同了,取start~i-1位置的date的值,第0个赋值给begin,倒数第一个赋值给end,将name_rec,begin,end三个值放入初始化的duty_list中,然后将start赋值为i缓存下来,更新name_rec为当前的name值,进行下一次循环。
利用pd.DataFrame()生成dataframe。
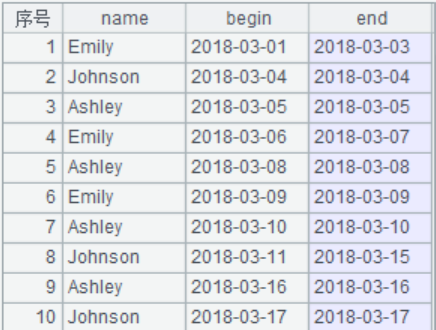
结果:
esproc
python

7.统计各等级在各个项目上的人数合计
题目介绍:sports表中存放有各个项目(短跑,长跑,跳远,跳高,铅球)的成绩(优秀,良好,及格,不及格),数据如下
我们的目的是统计出各个等级在各个项目上的人数。
esproc
A3:初始化一个空序列,用来汇总统计的结果
A4:因为sports表第一个字段是name,所以不用循环。循环各个项目的字段
B4:按照循环的这个字段进行分组
B5:新建一个表,该字段名作为subject字段的值,该字段分组中的值作为mark字段,分组中的成员数作为count字段
B6:将每个项目的结果汇总到A3中
A7: A.pivot(g,…;F,V;Ni:N'i,…),以字段/表达式g为组,将每组中的以F和V为字段列的数据转换成以Ni和N'i为字段列的数据,以实现行和列的转换。Ni缺省为F中的不重复字段值,N'i缺省为Ni。实现行列转换,形成透视表。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
sports = pd.read_csv('C:\Users\Sean\Desktop\kaggle_data\music_project_data\sports.csv',sep='\t')
subject_mark_cnt_list = []
for col in sports.columns[1:]:
sports_g = sports.groupby(by=col,as_index=False).count()[[col,'name']]
sports_g.rename(columns={'name':'count',col:'mark'},inplace=True)
sports_g['subject']=col
subject_mark_cnt_list.append(sports_g)
subject_mark_cnt = pd.concat(subject_mark_cnt_list,ignore_index=True)
subject_mark_count = pd.pivot_table(subject_mark_cnt[['subject','mark','count']],index = ['subject'],columns = 'mark',values = 'count')
print(subject_mark_count)
e = time.time()
print(e-s)
初始化subject_mark_cnt_list准备汇总循环的结果
循环除第一个字段的所有字段
df.groupby()按照该字段进行分组,统计分组中的成员数量,同时取当前的col这个字段和name字段。
df.rename(columns={})修改这个dataframe的列名
新增一列subject,并赋值为当前的col值。
将这个dataframe放入初始化的subject_mark_cnt_list列表中。
pd.concat()将列表中的数据连接成新的dataframe
pd.pivot_table(data,index,columns,values)将其改为透视表。
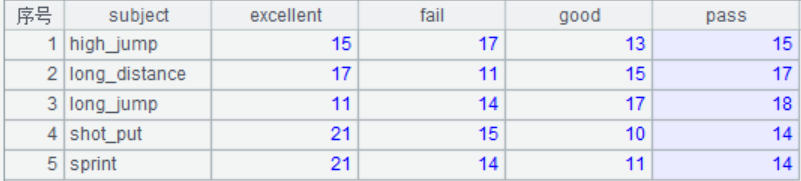
结果:
esproc
python


小结:本节我们计算了一些网上常见的题目,这些题目中多次用到了动态计算字段值,并进行赋值的操作,esproc很好的支持这一功能,大大简化了代码。而python不支持此功能,带来了麻烦,并且esproc的~表示了当前记录,省去了循环语句(其实仍是循环),python只能通过循环来完成。另外python中的merge函数不支持差集计算(或许其他函数支持),造成在第四例中特别麻烦。python pandas的dataframe结构是按列进行存储的,按行循环时就显得特别麻烦。





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。